Figure 1: A motivating figure for this blog post. The plot on the left shows that increasing the amount of regularization used when running ridge regression (corresponding to moving up higher on the y-axis) implies that ridge begins to tune out the directions in the data that have lower variation (i.e., we see more dark green as we scan from right to left). Meanwhile, the plot on the right actually shows very similar behavior, but this time for a very different estimator: gradient descent when run on the least-squares loss, as we terminate it earlier and earlier (i.e., as we increasingly stop gradient descent far short of when it converges, given again by moving higher up on the y-axis). This raises the question: are these similarities just a coincidence? Or is there something deeper going on here, linking together early-stopped gradient descent to ridge regression? We’ll try to address this question, in this blog post. (By the way, many of the other details in the plot, e.g., the labels “Grad Flow”, “lambda”, and “1/t” will all be explained, later on in the post.)
[Update: if you found this blog post interesting, then you may want to take a look at our recent paper, where we take up some of the same issues, as they relate to stochastic gradient descent.]
These days, it seems as though tools from statistics and machine learning are being used almost everywhere, with methods from the literature now seen on the critical path in a number of different fields and industries. A consequence of this sort of proliferation is that, increasingly, both non-specialists and specialists alike are being asked to deploy statistical models into the wild. This often makes “simple” methods a natural choice, with “simple” usually meaning (a) “easy-to-implement” and/or (b) “computationally cheap”.
That being the case, what could be simpler than gradient descent? Gradient descent is often quite easy to implement and computationally affordable, which probably explains (at least some of) its popularity. One thing people tend to do with gradient descent is to “stop it early”, by which I mean: people tend to not run gradient descent until convergence. Why not? Well, it has been long observed (by many, e.g., here, here, and here) that early-stopping gradient descent has a kind of regularizing effect—even if the loss function that gradient descent is run on has no explicit regularizer. In fact, it has been suggested (see, e.g., here and here) that the implicit regularization properties of optimization algorithms may explain at least in part some of the recent successes of deep neural networks in practice, making implicit regularization a very lively and growing area of research right now.
In our recent paper, we precisely characterize the implicit regularization effect of early-stopping gradient descent, when run on the least-squares regression problem. Apart from being interesting in its own right, the hope is that this sort of characterization will also be useful to practitioners.
(By the way, in case you think that least-squares is an elementary and boring problem: I would counter that and say that least-squares turns out to actually be quite an interesting problem to study, and moreover it represents a good starting point before moving onto more exotic problems. In any event, I’ll mention ideas for future work at the end of this post!)
The basic setup
To fix ideas, here is the standard least-squares regression problem:
\begin{equation}
\tag{1}
\hat \beta^{\textrm{ls}} \in \underset{\beta \in \mathbb{R}^p}{\mathrm{argmin}} \; \frac{1}{2n} \|y-X\beta\|_2^2.
\end{equation}
To be clear, \(y \in \mathbb{R}^n\) is the response, \(X \in \mathbb{R}^{n \times p}\) is the data matrix, \(n\) denotes the number of samples, and \(p\) the number of features. Running gradient descent on the problem (1) just amounts to
\begin{equation}
\tag{2}
\beta^{(k)} = \beta^{(k-1)} + \epsilon \cdot \frac{X^T}{n} (y – X \beta^{(k-1)}),
\end{equation}
where \(k=1,2,3,\ldots\) is an iteration counter, and \(\epsilon > 0\) is a fixed step size. At this point, it helps to also consider ridge regression:
\begin{equation}
\tag{3}
\hat \beta^{\textrm{ridge}}(\lambda) = \underset{\beta \in \mathbb{R}^p}{\mathrm{argmin}} \; \frac{1}{n} \|y-X\beta\|_2^2 + \lambda
\|\beta\|_2^2,
\end{equation}
where \(\lambda \geq 0\) is a tuning parameter.
It might already be intuitively obvious to you that (a) running (2) until convergence is equivalent to running (3) with \(\lambda = 0\); and (b) assuming the initialization \(\beta^{(0)} = 0\), not taking any steps in (2) just yields the null model, equivalent to running (3) with \(\lambda \to \infty\). Put differently, it seems as though running gradient descent for longer corresponds to less \(\ell_2\)-regularization, and therefore that early stopping gradient descent corresponds to more \(\ell_2\)-regularization. But is this actually true, in any formal sense? Perhaps a picture is worth a thousand words, at this point:
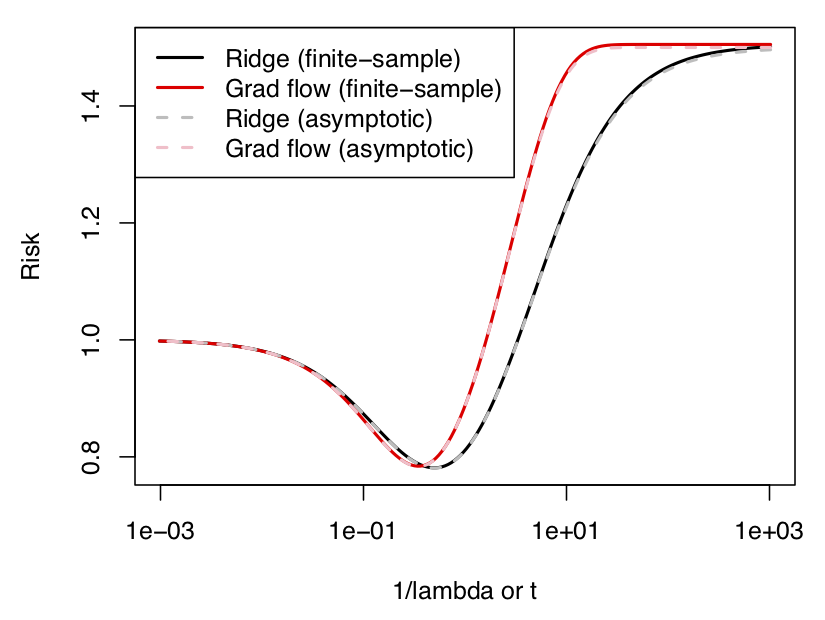 Figure 2: Estimation risk (see the text for a definition) of ridge regression and (essentially) gradient descent on the y-axis vs. the ridge regularization strength (equivalently, the inverse of the number of gradient descent iterations) on the x-axis, in both finite samples as well as in the large sample/dimension limit. The curves look very similar.
Figure 2: Estimation risk (see the text for a definition) of ridge regression and (essentially) gradient descent on the y-axis vs. the ridge regularization strength (equivalently, the inverse of the number of gradient descent iterations) on the x-axis, in both finite samples as well as in the large sample/dimension limit. The curves look very similar.Here, we are plotting the estimation risk (defined next) of ridge regression and (essentially) gradient descent on the y-axis, vs. the ridge regularization strength \(\lambda = 1/t\) (or, equivalently, the inverse of the number of gradient descent iterations) on the x-axis; the data was generated by drawing samples from a normal distribution, but similar results hold for other distributions as well. I’ll explain the reason for the “essentially” in just a minute.
First of all, by the estimation risk of an estimator \(\hat \beta\), I simply mean
\begin{equation}
\mathrm{Risk}(\hat \beta;\beta_0) := \mathbb{E} \| \hat \beta – \beta_0 \|_2^2,
\end{equation}
where here we are taking an expectation over the randomness in the response \(y\), which is assumed to follow a (parametric) distribution with mean \(X \beta_0\) and covariance \(\sigma^2 I\), where \(\sigma^2 > 0\). For now, we fix both the underlying coefficients \(\beta_0 \in \mathbb{R}^p\) as well as the data \(X\); we will allow both to be random, later on.
Back to the plot: in solid black and red, we plot the estimation risk of ridge regression and gradient descent, respectively, while we plot their limiting (i.e., large \(n,p\)) estimation risks in dashed black and red. What should be clear for now is that, aside from agreeing at their endpoints, the black and red curves are very close everywhere else, as well. In fact, it appears as though the risk of gradient descent cannot be more than, say, 1.2 times that of ridge regression.
Actually, maybe a second picture can also be of some help here. Below, we plot the same risks as we did above, but now the x-axis is an estimator’s achieved model complexity, as measured by its \(\ell_2\)-norm; the point of this second plot is that the risk curves are now seen to be virtually identical. So, hopefully that reinforces the point from earlier. Unfortunately, studying this sort of setup turns out to be a little complicated, so we’ll stick to the setup corresponding to the first plot, for the rest of this post.
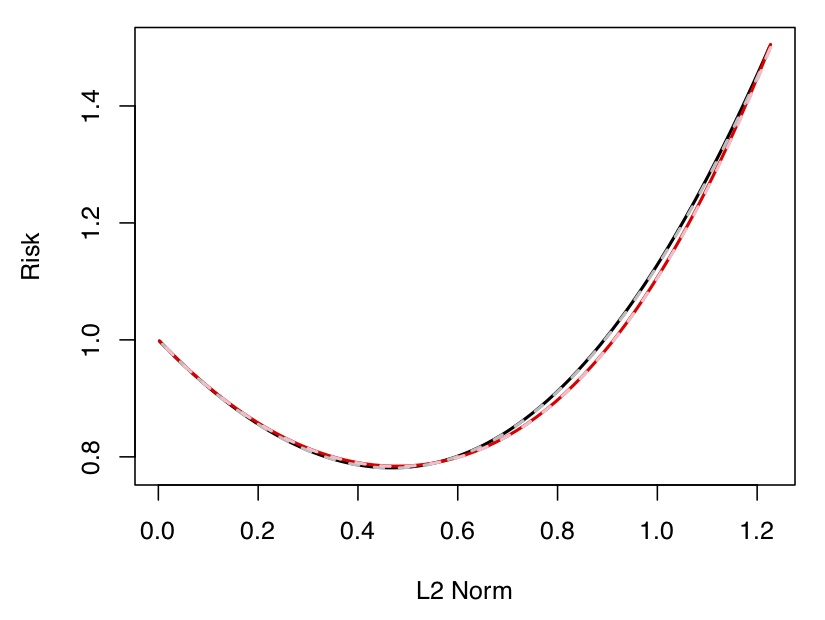 Figure 3: Estimation risk (see the text for a definition) of ridge regression and (essentially) gradient descent on the y-axis vs. the achieved model complexity on the x-axis, in both finite samples as well as in the large sample/dimension limit. The curves look nearly identical.
Figure 3: Estimation risk (see the text for a definition) of ridge regression and (essentially) gradient descent on the y-axis vs. the achieved model complexity on the x-axis, in both finite samples as well as in the large sample/dimension limit. The curves look nearly identical.A first result
The reason for the “essentially” parenthetical above was that in our paper we actually study gradient descent with infinitesimally small step sizes, which is often called gradient flow (this is why “Grad flow” appears in the legend of the plot, above). In contrast to the gradient descent iteration (2), gradient flow for (1) can be expressed as
\begin{equation}
\tag{4}
\hat \beta^{\textrm{gf}}(t) = (X^T X)^+ (I – \exp(-t X^T X/n)) X^T y,
\end{equation}
where \(A^+\) denotes the Moore-Penrose pseudo-inverse, \(\exp(A)\) denotes the matrix exponential, and \(t\) denotes “time”. This turns out to be the key to the analysis (and standard tools from numerical analysis can connect results obtained for (4) to those for (2)). Here is a simplified version of one result from our paper (i.e., Theorem 1) that follows rather immediately after taking the continuous-time viewpoint.
Theorem (simplified). Under the conditions given above, for any underlying coefficients \(\beta_0 \in \mathbb{R}^p\) and times \(t \geq 0\), we have that \(\mathrm{Risk}(\hat \beta^{\textrm{gf}}(t);\beta_0) \leq 1.6862 \cdot \mathrm{Risk}(\hat \beta^{\textrm{ridge}}(1/t);\beta_0)\).
In words, the estimation risk of gradient flow is no more than 1.6862 times that of ridge, at any point along their paths, provided we “line them up” by taking the ridge regularization strength as \(\lambda = 1/t\) (which seems fairly natural, as discussed above). The constant of 1.6862 also seems to match up pretty well with the constant of 1.2 that we noticed empirically above.
To be completely clear, we are certainly not the first authors to relate gradient descent and \(\ell_2\)-regularization (see our paper for a mention of related work), but we are not aware of any other kind of result that does so with this level of specificity as well as generality; more on this latter aspect after a proof of the result.
Proof (sketch). To show the result, we need two simple facts: first, for \(x \geq 0\), it holds that (a) \(\exp(-x) \leq 1/(1+x)\); and second (b) \(1-\exp(-x) \leq 1.2985 \cdot x/(1+x)\). We also need a little bit of notation: let \(s_i, v_i, \; i=1,\ldots,p\) denote the eigenvalues and eigenvectors, respectively, of \((1/n) X^T X\). Owing to the continuous-time representation, it turns out the estimation risk of gradient flow can be written as \(\mathrm{Risk}(\hat \beta^{\textrm{gf}}(t);\beta_0) = \sum_{i=1}^p a_i\), where
\begin{equation*}
a_i = |v_i^T \beta_0|^2 \exp(-2 t s_i) +
\frac{\sigma^2}{n} \frac{(1 – \exp(-t s_i))^2}{s_i},
\end{equation*}
while that of ridge regression can be written as \(\mathrm{Risk}(\hat \beta^{\textrm{ridge}}(\lambda);\beta_0) = \sum_{i=1}^p b_i\), where
\begin{equation*}
b_i = |v_i^T \beta_0|^2 \frac{\lambda^2}{(s_i + \lambda)^2} +
\frac{\sigma^2}{n} \frac{s_i}{(s_i + \lambda)^2}.
\end{equation*}
Now, using facts (a) and (b) (as well as a change of variables), we get that
\begin{align*}
a_i &\leq |v_i^T \beta_0|^2 \frac{1}{(1 + t s_i)^2} +
\frac{\sigma^2}{n} 1.2985^2 \frac{t^2 s_i}{(1 + t s_i)^2} \\
&\leq 1.6862 \bigg(|v_i^T \beta_0|^2 \frac{(1/t)^2}{(1/t + s_i)^2} +
\frac{\sigma^2}{n} \frac{s_i}{(1/t + s_i)^2} \bigg) \\
&= 1.6862 \, b_i,
\end{align*}
where, again, we used \(\lambda = 1/t\). Summing over \(i=1,\ldots,p\) in the above gives the result.
Going (much) further
Earlier, I hinted that it was possible to generalize the result presented above. In fact, in our paper, we show how to obtain the same result for various other notions of risk:
- Bayes estimation risk (i.e., where \(\beta_0\) is assumed to follow some prior)
- In-sample (Bayes) prediction risk (i.e., \( (1/n) \mathbb{E} \| X \hat \beta – X \beta_0 \|_2^2 \))
- Out-of-sample Bayes prediction risk (i.e., \( \mathbb{E}[(x_0^T \hat \beta – x_0^T \beta_0)^2] \), where \(x_0\) is a test point).
See (the rest of) Theorem 1 as well as Theorem 2 in the paper, for details. Finally, it is also possible to obtain even tighter results in all these settings when we examine the risks of optimally-tuned ridge and gradient flow; see Theorem 3.
An asymptotic viewpoint
To finish up, I’ll (very) briefly mention some of the insights that we get by examining the above issues from an asymptotic viewpoint. In a really nice piece of recent work, it was shown that under a high-dimensional asymptotic setup with \(p,n \to \infty\) such that \(p/n \to \gamma \in (0,\infty)\), the out-of-sample Bayes prediction risk of ridge regression converges to the expression
\begin{equation}
\tag{5}
\sigma^2 \gamma \big[
\theta(\lambda) + \lambda (1 – \alpha_0 \lambda) \theta'(\lambda) \big],
\end{equation}
almost surely, for each \(\lambda > 0\), where \(\alpha_0\) is a fixed constant depending on the variance of the prior on the coefficients. Also, \(\theta(\lambda)\) is a functional (whose exact form is not important for this brief description) that depends on \(\sigma^2, \lambda, \gamma\), as well as the limiting distribution of the eigenvalues of the sample covariance matrix.
Where I think things get really interesting is that it turns out for gradient flow, the analogous risk has the following almost sure limit (see Theorem 6 in our paper for details):
\begin{equation}
\tag{6}
\sigma^2 \gamma \bigg[ \alpha_0 \mathcal L^{-1}(\theta)(2t) + 2 \int_0^t \big( \mathcal L^{-1}(\theta)(u) – \mathcal L^{-1}(\theta)(2u) \big) \, du\bigg],
\end{equation}
where \(\mathcal L^{-1}(\theta)\) denotes the inverse Laplace transform of \(\theta\). In a nice bit of symmetry, note that (5) features the functional \(\theta\) and its derivative, whereas (6) features the inverse Laplace transform of the functional \(\mathcal L^{-1}(\theta)\) and its antiderivative. Moreover, note that (6) is an asymptotically exact risk expression, i.e., there are no hidden constants or anything like that. The key to the analysis here turns out to be applying recent tools from random matrix theory to (functionals of) the sample covariance matrix \((1/n) X^T X\). Again, that was a very brief sketch of the result … but hopefully it at least got across some (more) of the interesting duality between ridge regression and gradient descent.
Future work
If you found this post interesting, that’s great! There is a number of other connections between ridge regression and gradient descent that we point out in the paper, which I didn’t have the space to get into here. There are also plenty of places to go next, including studying stochastic gradient descent and moving beyond least-squares (both of which we are doing right now). Feel free to get in touch if you would like to learn more.
DISCLAIMER: All opinions expressed in this posts are those of the author and do not represent the views of Carnegie Mellon University.