Consider the following problem: we are given a set of items, and the goal is to pick the “best” ones from them. This problem appears very often in real life — for example, selecting papers in conference peer review, judging the winners of a diving competition, picking city construction proposals to allocate funds, etc. In these examples, a common procedure is to assign the items (papers/contestants/proposals) to people (reviewers/judges/citizens) and ask them for their opinion. Then, we aggregate their opinions, and select the best items accordingly. For simplicity, we assume that each item pertains a “true” quality (or “true” value), which is a real number that precisely quantifies how good the item is, and this number is unknown to us. The best items are then the ones with the highest true qualities.
There are a number of sources of biases that may arise when soliciting evaluations from people. In this blog post, we focus on miscalibration, which refers to people using different scales when assigning numerical scores. As a running example throughout this blog post, we consider conference peer review. Peer review is a process common in scientific publication. When researchers submit a paper to a conference, the conference organizers will assign the paper to a few “peer reviewers”, who are researchers in the same field, and ask these reviewers to evaluate the quality of the paper. Based on the reviews and comments written by the peer reviewers, the conference organizers make a decision on whether to accept or reject the paper.
It might be the case that some reviewers are lenient and always provide scores in the range [6, 10] whereas some reviewers are more stringent and provide scores in the range [0, 4]. Or it might be the case that one reviewer is moderate whereas the other is extreme — the first reviewer’s 2 is equivalent to the second reviewer’s 1 whereas the first reviewer’s 3 is equivalent to the second reviewer’s 9. Indeed, the issue of miscalibration has been widely noted in the literature:
“The rating scale as well as the individual ratings are often arbitrary and may not be consistent from one user to another.”
[Ammar & Shah, 2012]
“A raw rating of 7 out of 10 in the absence of any other information is potentially useless.”
[Mitliagkas et al. 2011]
So what should we do with the miscalibrated scores we receive? There are two common approaches to address miscalibration. One approach is to make simple assumptions about the nature of miscalibration. For example, in the past, people have assumed that miscalibration is linear. That is, when a reviewer reviews a paper, the score reported by this reviewer will be the true quality of the paper multiplied by a positive scalar, followed by an addition or subtraction of another scalar. However, calibration issues with human-provided scores are often much more complex, and therefore we have not seen much success with these simple models in real conference peer review settings.
The second approach is to use only the ranking of the items. We use “ranking” to refer to the ordering of items. For example, if a reviewer gives scores of 5, 9, and 3 to three papers respectively, then the “ranking” from this reviewer is that the second paper is better than the first paper, and the first paper is better than the third. The ranking can be obtained by sorting the reviewer’s scores of papers (for simplicity, assume there are no ties), or by directly asking the reviewers to rank the papers. In practice, rankings are often used instead of numerical scores. For example, quoting the landmark paper by Freund et al.:
“[Using rankings instead of ratings] becomes very important when we combine the rankings of many viewers who often use completely different ranges of scores to express identical preferences.”
[Freund et al. 2003]
It is a folklore belief that without making any simplifying assumptions on miscalibration, the only useful information is the underlying ranking. In our AAMAS 2019 paper, we examine the fundamental question of whether this folklore belief is true. Concretely, we present theoretical results that contest this belief. We show that, if we use the rating data instead of only the ranking data, we can do strictly better in selecting the best items, even amidst high levels of miscalibration.
For simplicity, let’s first consider the following toy problem: given two papers and two reviewers, we want to select the better paper out of the two. Suppose each reviewer is assigned one paper, and this assignment is done uniformly at random. The two reviewers provide their evaluations (e.g., on a scale from 0 to 10) for the respective paper they review. The reviewers’ rating scales may be miscalibrated. This miscalibration can be arbitrary, and is unknown to us. Since each reviewer only provides a single score, the ranking data collected from each reviewer is vacuous. An algorithm based on rankings can’t really do better than randomly guessing which paper is better. The question we aim to answer is thus: in such a case, can we do strictly better than a random guess, by making use of the scores given by the two reviewers, instead of just their rankings?
Interestingly, as we will explain shortly, the answer turns out to be “yes”. This contests the forklore belief that under arbitrary miscalibration, the only useful information in ratings is the underlying ranking.
Problem Set-up
To understand the general problem of miscalibration, we first consider a simplified setting, and the key ideas from this setting will be used as a crucial building block for more general algorithms. In this simplified setting, assume that we have two papers with unknown quality values \(x_1, x_2\in \mathbb{R}\), and two reviewers. The two papers are respectively assigned to the two reviewers uniformly at random. That is, paper 1 is assigned to reviewer 1 and paper 2 to reviewer 2 with probability 0.5 (otherwise, paper 1 is assigned to reviewer 2 and paper 2 to reviewer 1). For each reviewer \(i \in \{1, 2\}\), we use a “calibration function” \(f_i: \mathbb{R} \rightarrow \mathbb{R}\) to represent the miscalibration of that reviewer. This function is a mapping from the true quality of a paper, to the score that the reviewer will report for this paper. That is, if the true value of a paper evaluated by reviewer \(i\) is \(x\) then the reviewer will report \(f_i(x)\). For convenience of exposition, we normalize the rating scale such that that the ratings lie in the range of [0, 1], so we have \(f_i : \mathbb{R} \rightarrow [0, 1]\).
We assume that the calibration functions \(f_1\)and \(f_2\) are strictly monotonically increasing. That is, if a reviewer were assigned a paper of higher quality, then the reviewer would give a higher score to that paper (but we don’t know by how much), than to one of lower quality. Other than that, the values \(x_1, x_2\) and functions \(f_1, f_2\) can be arbitrary. Let us denote the reported score for paper 1 (from its assigned reviewer) as \(y_1\), and the reported score for paper 2 (from its assigned reviewer) as \(y_2\). Given the scores \(y_1, y_2\), and the assignment of which paper is assigned to which reviewer, our goal is to tell which paper is better (i.e., infer whether \(x_1 > x_2\) or \(x_1 < x_2\)).
Algorithm and Intuition
At first, it may seem impossible to extract any useful information from the numerical scores, as the two papers are reviewed by different reviewers, and therefore the scores can be different due to either miscalibration, or differences in the true paper qualities. Say, reviewer 1 is assigned paper 1, and gives a score of 0.5, and reviewer 2 is assigned paper 2 and gives a score of 0.8. Then either of the following two cases is possible (among an infinite number of possible cases):
$$ \text{Case I}\\ x_1 = 0.5 \qquad\qquad f_1(x) = x\\
x_2 = 0.8 \qquad\qquad f_2(x) = x\\
\text{Case II}\\
x_1 = 1.0 \qquad\qquad f_1(x) = \frac{x}{2}\\ x_2 = 0.8 \qquad\qquad f_2(x) = x. $$
In Case I, we have \(x_1 < x_2\), and in Case II, we have \(x_1 > x_2\). If an algorithm outputs the outcome aligned with one case, then the algorithm will fail in the other case. Indeed, the following theorem shows that no deterministic algorithm based on ratings can ever be strictly better than random guessing.
Theorem 1. Given the scores \(y_1, y_2\) and the assignment, no deterministic algorithm can always perform strictly better than random guessing, under all possible \(x_1, x_2\) and strictly monotonic \(f_1, f_2\).
Let’s try to understand why this is the case. A deterministic algorithm “commits” to an action (deciding which paper has a better quality). It performs well if the situation is aligned with this action. However, due to its prior commitment it may fail if the situation is not aligned. To be more specific, consider the game of rock-paper-scissors. In this game, a deterministic algorithm always loses to an adversary (if the deterministic algorithm plays scissors, then the adversary wins by playing rock, etc.).
The key to solving the problem is randomization — A randomized algorithm can judiciously balance out the good and bad cases. Going back to the example of rock-paper-scissors, consider a randomized algorithm that chooses one of the three actions (rock, paper or scissors) uniformly at random, then it can be formally shown that this randomized algorithm wins 1/3 of the time against the adversary. Given this motivation, we consider the following randomized algorithm for our estimation problem:
Algorithm. Output the paper with the higher score, with probability \(\frac{1 + \lvert y_1-y_2\rvert}{2}\). Otherwise, output the paper with the lower score.
We now show that our randomized algorithm can indeed achieve the desired goal.
Theorem 2. The proposed randomized algorithm succeeds with probability strictly greater than \(0.5\), for any \(x_1, x_2\) and strictly monotonic \(f_1, f_2\).
More generally, let \(g:\mathbb{R} \rightarrow [0, 1]\) be any strictly monotonically increasing function that is anti-symmetric around 0 (that is, \(g(x) = -g(-x)\) for all \(x\in \mathbb{R}\)). Then, Theorem 2 holds for algorithms that output the paper with the higher score with probability \(\frac{1 + g(\lvert y_1 – y_2\rvert)}{2}\). The algorithm mentioned above is a special case using the identity function \(g(u) = u\). The function \(g\) can also take other forms, such as the sigmoid function \(g(u) = \frac{1}{1 + e^{-u}}\).
Using the canonical \(2\times 2\) setting as a building block, we construct algorithms in more general settings such as A/B testing and ranking. See our paper for more details. The paper also includes a discussion on the inspirations and connections to the related work, including Stein’s shrinkage, empirical Bayes, and the two-envelope problem [Cover 1987].
The rest of this section is devoted to giving intuition about Theorem 2 along with a proof sketch.
The key intuition of this result is to exploit the monotonic structure of the calibration functions, whereas this structure is unavailable in ranking data. As we discussed, the randomized algorithm does not make a prior commitment, but instead spreads out its bets on both the good and the bad cases. In this case, because of the monotonic structure of the calibration functions, the probability of the good case (correct estimation) is greater than the probability of the bad case (incorrect estimation) for the randomized algorithm. We now provide a simple proof sketch.
Proof sketch.Without loss of generality, let us assume that \(x_1 < x_2\). Then we consider two cases:
Case I: The scores given by the two reviewers for paper 2 are strictly higher than the scores for paper 1. That is, \(\max\{f_1(x_1), f_2(x_1)\} < \min\{f_1(x_2), f_2(x_2)\}\).
With the random assignment, we observe either \({f_1(x_1), f_2(x_2)}\) or \(\{f_2(x_1), f_1(x_2)\}\). In either assignment, we have \(y_2 > y_1\), and the proposed algorithm succeeds with probability \(\frac{1 + (y_2 – y_1)}{2} > \frac{1}{2}\).
Case II: In at least one of the assignments, the score for paper 2 is lower than or equal to the score for paper 1. Without loss of generality, assume \(f_1(x_1) \ge f_2(x_2)\). Then by the monotonicity of \(f_1, f_2\), we have $$ f_2(x_1) < f_2(x_2) \le f_1(x_1) < f_1(x_2)\qquad \qquad (\star)$$.
We illustrate Equation \((\star)\) pictorially as follows:
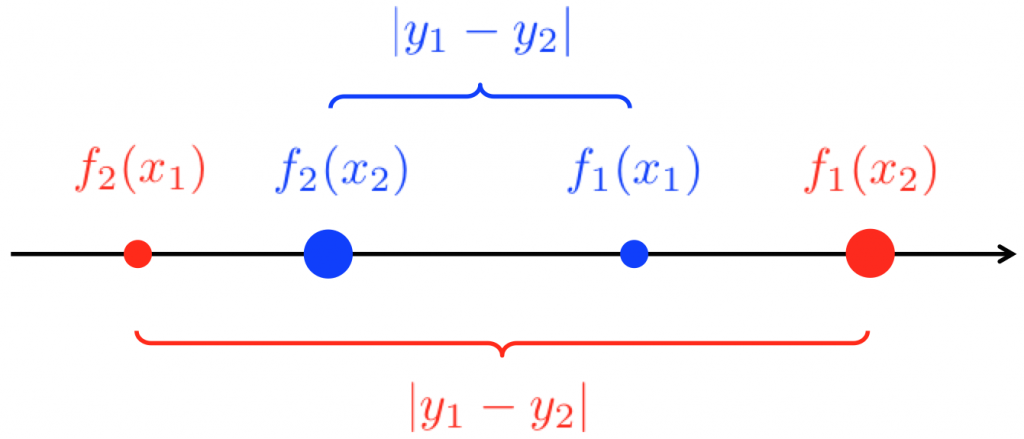 Figure: The four possible scores. The two blue dots are the two scores that are observed under one assignment, and the two red dots are the two scores that are observed under the other assignment. A large dot means that the paper has a better underlying quality, and a small dot means that the paper has a lower underlying quality. We can see that in the blue assignment, the ordering of the scores is flipped from the true ordering of the two papers. The difference of the two scores in the blue assignment is smaller than the difference of the two scores in the red assignment.
Figure: The four possible scores. The two blue dots are the two scores that are observed under one assignment, and the two red dots are the two scores that are observed under the other assignment. A large dot means that the paper has a better underlying quality, and a small dot means that the paper has a lower underlying quality. We can see that in the blue assignment, the ordering of the scores is flipped from the true ordering of the two papers. The difference of the two scores in the blue assignment is smaller than the difference of the two scores in the red assignment.With the assignment, we either observe the two blue scores, or the two red scores. In the blue assignment, the algorithm is more likely to conclude that paper 1 is better (bad case). In the red assignment, the algorithm is more likely to conclude that paper 2 is better. The difference \(\lvert {y_1 -y_2} \rvert\) between the two scores is greater in the red assignment. By the construction of the algorithm, it leverages this difference, so that it “succeeds more” in the red assignment than the amount it “loses” in the blue assignment.
More formally, for assignment \(\{f_2(x_1), f_1(x_2)\}\), the algorithm succeeds with probability \(\frac{1 + (f_1(x_2) – f_2(x_1))}{2}\), and for assignment \(\{f_1(x_1), f_2(x_2)\}\), the algorithm succeeds with probability \(\frac{1 – (f_1(x_1) – f_2(x_2))}{2}\). Taking an expectation over the assignment, the overall probability of success is
$$ \frac{1}{2} + \frac{(f_1(x_2) – f_2(x_1)) – (f_1(x_1) – f_2(x_2))}{2} > \frac{1}{2}, $$
because \( f_1(x_2) – f_2(x_1) > f_1(x_1) – f_2(x_2)\) by Equation \((\star)\) (or by the Figure).
\(\square\)
Take-Aways and Open Questions
The two key take-aways from our paper are:
(1) Numerical scores contain strictly more information than rankings, even in presence of arbitrary miscalibration. This is in contrast to the folklore belief that under arbitrary miscalibration, the only useful information in ratings is the underlying ranking.
(2) In conference peer review, paper decisions are typically made in a deterministic fashion. However, for papers near the acceptance border, the difference in their scores is small, and could very well be due to issues of calibration of reviewers rather than inherent qualities of the papers. Our work thus suggests that a more fair alternative is to randomize the paper decisions at the border in a randomized fashion like our proposed algorithm in order to account for miscalibration.
Our paper also gives rise to a number of open problems of interest:
(1) Non-adversarial models: In order to analyze the folklore belief, we consider arbitrary miscalibration, and give an algorithm based on ratings that uniformly outperforms algorithms based on rankings. From a practical point of view, it is of interest to model the nature of miscalibration that is not the worst case — something in between over-simplified models for miscalibration and arbitrary miscalibration.
(2) Combining different sources of biases: Miscalibration does not happen in isolation, and indeed other factors do contribute to inaccuracies in terms of paper decisions, such as subjectivity [Noothigattu et al. 2018], strategic behavior [Xu et al. 2018] and noise [Stelmakh et al. 2018]. For example, subjectivity means that people may hold different opinions about the merits of certain papers — what one reviewer thinks is a good paper may look like a mediocre paper from the perspective of another reviewer, and therefore the paper receives different scores from the two reviewers (whereas miscalibration means that even if a paper appears to be identically good to two reviewers, the reviewers may still give different scores due to miscalibration). Combining miscalibration simultaneously with these other factors is a useful and challenging open problem.
DISCLAIMER: All opinions expressed in this posts are those of the author and do not represent the views of Carnegie Mellon University.
References
A. Ammar and D. Shah. “Efficient rank aggregation using partial data“. SIGMETRICS 2012.
T. Cover. “Pick the Largest Number“. 1987.
Y. Freund, R. Iyer, R. E. Schapire and Y. Singer. “An Efficient Boosting Algorithm for Combining Preferences“. Journal of Machine Learning Research 2003.
I. Mitliagkas, A. Gopalan, C. Caramanis and S. Vishwanath. “User rankings from comparisons: Learning permutations in high dimensions“. Allerton 2011.
R. Noothigattu, N. Shah and A. Procaccia. “Choosing how to choose papers“. ArXiv 2018.
I. Stelmakh, N. Shah and A. Singh. “PeerReview4All: Fair and Accurate Reviewer Assignment in Peer Review“. ALT 2019.
Y. Xu, H. Zhao, X. Shi and N. Shah. “On strategyproof conference review“. ArXiv 2018.