Figure 1. Fine-tuning a language model to predict EEG data. The encoder is pretrained on Wikipedia to predict the next word in a sequence (or previous word for the backward LSTM). We use the contextualized embeddings from the encoder as input to a decoder. The decoder uses a convolution to create embeddings for each pair of words, which, along with word-frequency and word-length become the basis for a linear layer to predict EEG responses. The model is fine-tuned to predict this EEG data. In this example the model is jointly trained to predict the N400 and P600 EEG responses.
Imagine for a moment that we can take snippets of text, give them to a computational model, and that the model can perfectly predict some of the brain activity recorded from a person who was reading the same text. Can we learn anything about how the brain works from this model? If we trust the model, then we can at least identify which parts of the brain activity are related to the text. Beyond this though, what we learn from the model depends on how much we know about the mechanisms it uses to make its predictions. Given that we want to understand these mechanisms, and that models produced by deep learning can be difficult to interpret, deep learning seems at first glance not to be a good candidate for analyzing language processing in the brain. However, deep learning has proven to be amazingly effective at capturing statistical regularities in language (and other domains). This effectiveness motivated us to see whether a deep learning model is able to predict brain activity from text well, and importantly, whether we can gain any understanding about the brain activity from the predictions. It turns out that the answer to both questions is yes.
One of the open questions in the study of how the brain processes language is how word meanings are integrated together to form the meanings of sentences, passages and dialogues. Electroencephalography (EEG) is a tool that is commonly used to study those integrative processes. In a recent paper, we propose to use fine-tuning of a language model and multitask learning to better understand how various language-elicited EEG responses are related to each other. If we can better understand these EEG responses and what drives them, then we can use that understanding to better study language processing in people.
In our analysis, we use EEG observations of brain activity recorded as people read sentences. Several different kinds of deviations from baseline measurements of activity occur as people read text. The most well studied of these is called the N400 response. It is a Negative deflection in the electrical activity (relative to a baseline) that occurs around 400 milliseconds after the onset of a word (thus N400), and it has been associated with semantic effort. If a word is expected in context — for example “I like peanut butter and jelly” versus “I like peanut butter and roller skates” — then the expected word jelly will elicit a reduced N400 response compared to the unexpected roller.
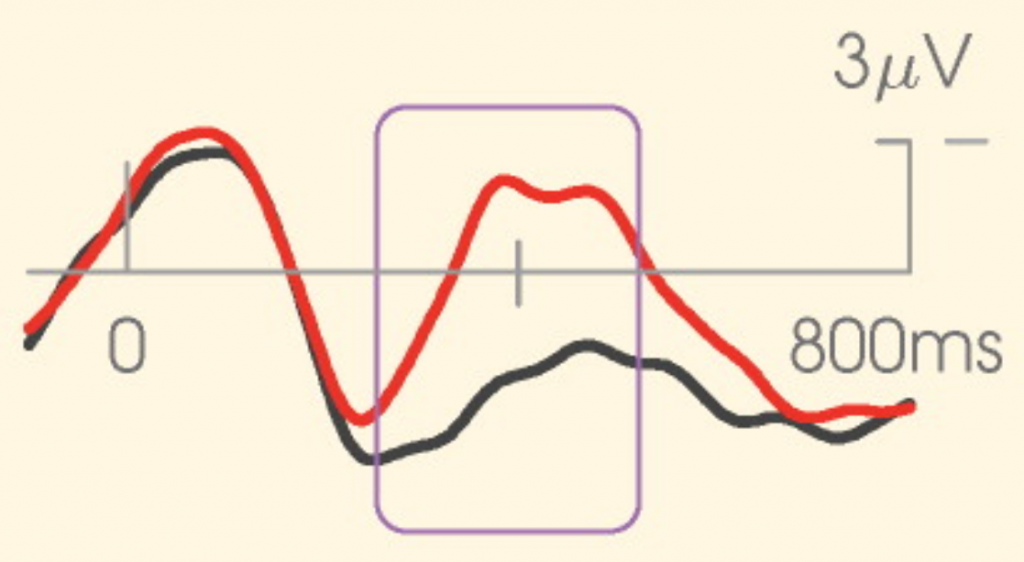 Figure 2. An example N400 response to an unexpected (red line) versus expected (black line) word from Kutas and Federmeier. Notice that upwards on the y-axis is more negative.
Figure 2. An example N400 response to an unexpected (red line) versus expected (black line) word from Kutas and Federmeier. Notice that upwards on the y-axis is more negative. In the data we analyze (made available by Stefan Frank and colleagues) six different language associated responses are considered. Three of these — the N400, PNP, and EPNP responses — are generally considered markers for semantic processes in the brain while the other three — the P600, LAN, and ELAN — are generally considered markers for syntactic processes in the brain. The division of these EEG responses into indicators for syntactic and semantic processes is controversial, and there is considerable debate about what each of the responses signifies. The P600, for example, is thought by some researchers to be triggered by syntactic violations, as in “The plane took we to paradise and back” while others have noted that it can also be triggered by semantic role violations, as in “Every morning at breakfast the eggs would eat …”, and still others have questioned whether the P600 is language specific or rather a marker for any kind of rare event. One possibility is that it is associated with an attentive process invoked to reconcile conflicting information from lower level language processing. In any case, a clearer picture of the relationship between all of the EEG responses and between text and the EEG responses would make them better tools for investigating language processing in the brain.
Rather than having discrete labeling of whether each of the six EEG responses occurred as a participant read a given word, in this dataset the EEG responses are defined continuously as the average potential of a predefined set of EEG sensors during a predefined time-window (relative to when a word appears). This gives us six scalar values per word per experiment participant, and we average the values across the participants to give six final scalar values per word.
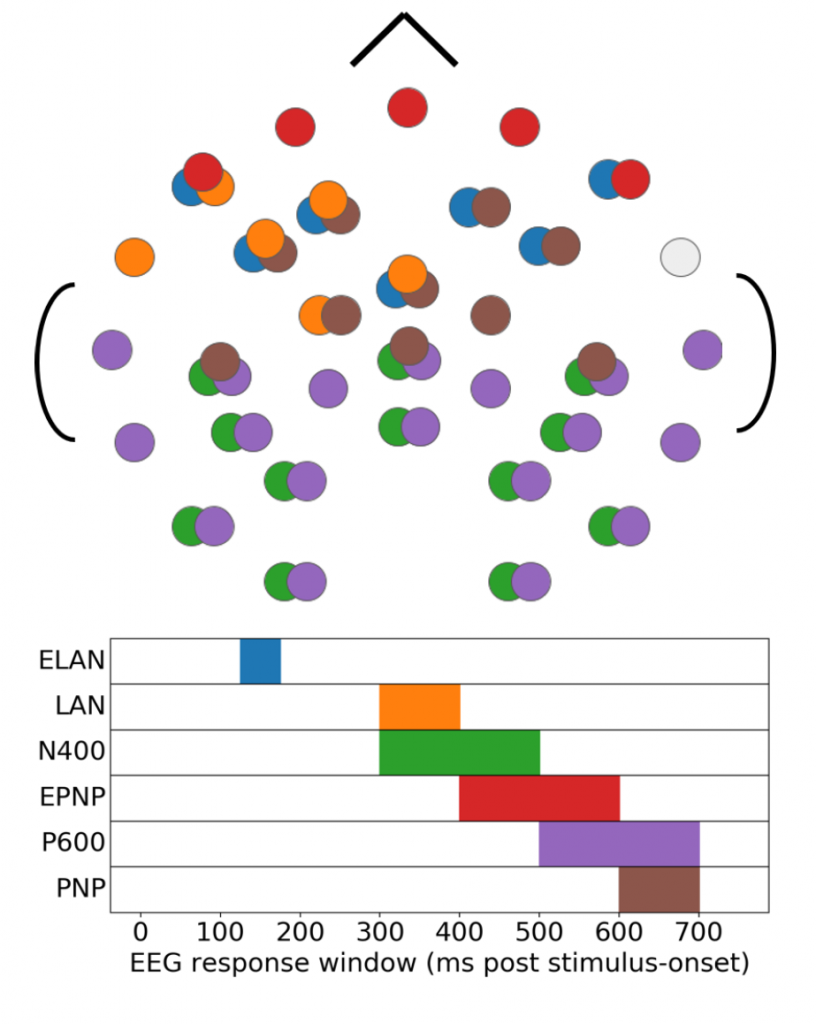 Figure 3. A top-down schematic (with the nose pointing towards the top of the page) of the EEG sensor locations and the timing information for each language-associated EEG response. Overlapping circles indicate multiple responses recorded from the same sensor.
Figure 3. A top-down schematic (with the nose pointing towards the top of the page) of the EEG sensor locations and the timing information for each language-associated EEG response. Overlapping circles indicate multiple responses recorded from the same sensor.To predict these six scalar values for each word, we use a pretrained bidirectional LSTM as an encoder. We anticipate that the EEG responses occur in part as a function of a shift in the meaning or structure of the incoming language. For example, the N400 is associated with semantic effort and surprisal, so we might expect that the N400 would be some function of a difference between adjacent word embeddings. Because of this intuition, we pair up the embeddings output from the encoder by putting them through a convolutional layer that can learn functions on adjacent word embeddings. We use the pair embeddings output by the convolution, along with the word length and log-probability of the word as the basis for predicting the EEG responses. The EEG responses are predicted from this basis using a linear layer. The forward and backward LSTMs are pretrained independently on the WikiText-103 dataset to predict the next and previous words respectively from a snippet of text. We fine-tune the model by training the decoder first and keeping the encoder parameters fixed, and then after that we continue training by also modifying the final layer of the LSTM for a few epochs.
A natural question is whether these EEG measures of brain activity can be predicted from the text at all, and whether all of this deep learning machinery actually improves the prediction compared to a simpler model. As our measure of accuracy, we use the proportion of variance explained — i.e. we normalize the mean squared error on the validation set by the variance on the validation set and subtract that number from 1: \(\mathrm{POVE} = 1 – \frac{\mathrm{MSE}}{\mathrm{variance}}\). We compare the accuracy of using the decoder on top of three different encoders: an encoder which completely bypasses the LSTM (i.e. the output embeddings are the same as the input embeddings to the encoder), an encoder which is a forward-only LSTM, and an encoder which is the full bidirectional LSTM.
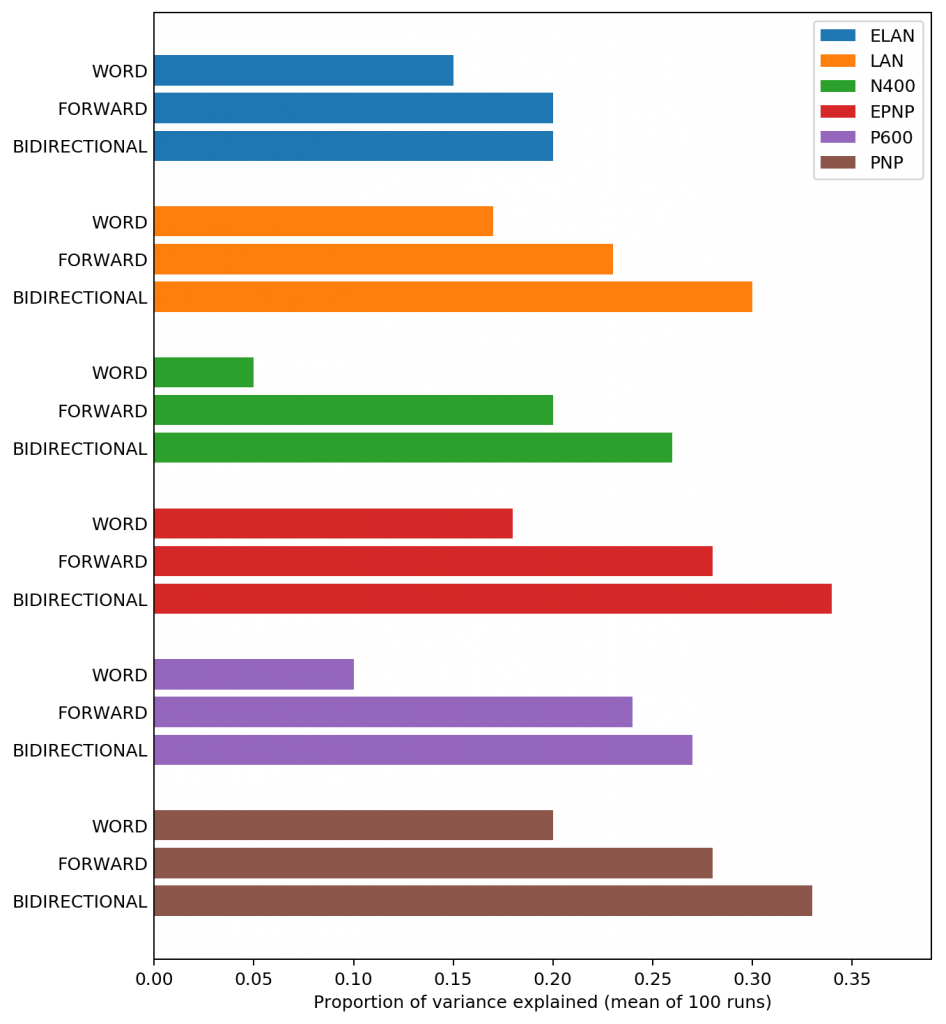 Figure 4. The proportion of variance explained for each target EEG signal (mean of 100 runs). The bars are color-coded by which EEG signal we are predicting. WORD indicates that the input word embedding is used as the encoder representation, FORWARD indicates that the forward-only LSTM is used as the encoder representation, and BIDIRECTIONAL indicates that the bidirectional LSTM is used as the encoder.
Figure 4. The proportion of variance explained for each target EEG signal (mean of 100 runs). The bars are color-coded by which EEG signal we are predicting. WORD indicates that the input word embedding is used as the encoder representation, FORWARD indicates that the forward-only LSTM is used as the encoder representation, and BIDIRECTIONAL indicates that the bidirectional LSTM is used as the encoder.Surprisingly, we see that all six of the EEG measures can be predicted at above chance levels (\(0\) is chance here since guessing the mean would give us \(\mathrm{POVE}\) of \(0\)). Previous work (here and here) has found that only some of the EEG measures are predictable, but that work did not directly try to predict the brain activity from the text. Instead, it used an estimate of the surprisal (the negative log-probability of the word in context), and an estimate of the syntactic complexity to predict the EEG data. Those intermediate values have the benefit of being interpretable, but they lose a lot of the pertinent information.
We also see that the full bidirectional encoder is better able to predict the brain activity than the other encoders. The comparison between encoders is not completely fair because there are more parameters in the forward-only encoder than the embedding-only encoder, and more parameters than both of those in the bidirectional encoder, so part of the reason that the bidirectional encoder might be better is simply that it has more degrees of freedom to work with. Nonetheless, this result suggests that the context matters for the prediction of the EEG signals, which means that there is opportunity to learn about the features in the language stream that drive the EEG responses.
It’s good to see that the deep learning model can predict all of the EEG responses, but we also want to learn something about those responses. We use multitask learning to accomplish that here. We train our network using \(63 = \binom{6}{1} + \binom{6}{2} + … + \binom{6}{6}\) variations of our loss function. In each variation, we choose a subset of the six EEG signals and include a mean squared error term for the prediction of each signal in that subset. For example, one of the variations includes just the N400 and the P600 responses, so there are mean squared error terms for the prediction of the N400 and the prediction of the P600 in the loss function for that variation, but not for the LAN. We only make predictions for content words (adjectives, adverbs, auxiliary verbs, nouns, pronouns, proper nouns, and verbs), so if there are \(B\) examples in a mini-batch, and example \(b\) has \(W_b\) content words, and if we let the superscripts \(p,a\) denote the predicted and actual values for an EEG signal respectively, then the loss function for the N400 and P600 variation can be written as:
$$\frac{1}{\sum_{b=1}^B W_b} \sum_{b=1}^B \sum_{w=1}^{W_b} (\mathrm{P600}^{p}_{b,w} – \mathrm{P600}^{a}_{b,w})^2 + (\mathrm{N400}^{p}_{b,w} – \mathrm{N400}^{a}_{b,w})^2$$
The premise of this method is that if two or more EEG signals are related to each other, then including all of the related signals as prediction tasks should create a helpful inductive bias. With this bias, the function that the deep learning model learns between the text and an EEG signal of interest should be a better approximation of the true function, and therefore it should generalize better to unseen examples.
We filter the results to keep (i) the variations that include just a single EEG response in the loss function (the top bar in each group below), (ii) the variations that best explain each EEG response (the bottom bar in each group below), and (iii) the variations which are not significantly different from the best variations and which include no more EEG responses in the loss function than the best variation, i.e. all simpler combinations of EEG responses which perform as well as the best combination (all the other bars). For the N400, where the best variation does not include any other EEG signals, we also show how the proportion of variance explained changes when we include each of the other EEG signals.
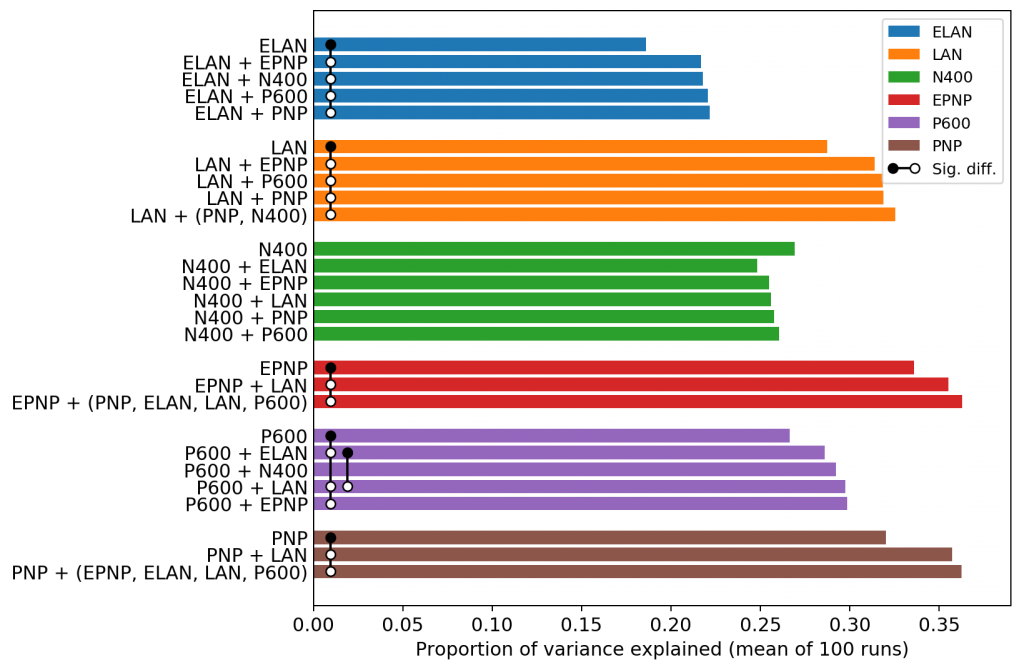 Figure 5. The proportion of variance explained (mean of 100 runs) for each EEG signal when trained with different multitask training variations. If a black dot on one bar is connected to a white dot on another bar by a vertical line, the bars are significantly different from each other after controlling for multiple comparisons using false discovery rate at a 0.01 level.
Figure 5. The proportion of variance explained (mean of 100 runs) for each EEG signal when trained with different multitask training variations. If a black dot on one bar is connected to a white dot on another bar by a vertical line, the bars are significantly different from each other after controlling for multiple comparisons using false discovery rate at a 0.01 level.
For each target EEG signal other than the N400, it is possible to improve prediction by using multitask learning. As Rich Caruana points out in his work on multitask learning, a target task can be improved by auxiliary tasks even when the tasks are unrelated. However, our results are suggestive of relationships between the EEG signals. It’s not the case that training with more EEG signals is always better, and the pattern of improvements for different variations doesn’t look random. The improvements also don’t follow the pattern of raw correlations between the EEG signals (see our paper for the correlations).
Some of the relationships we see here are expected from current theories of how each EEG response relates to language processing. The LAN/P600 and ELAN/P600 relationship is expected based both on prior studies where they have been observed together and theory that the ELAN/LAN responses occur during syntactic violations and the P600 occurs during increased syntactic effort. Our results also suggest some relationships which are not as expected, but which have plausible explanations. For example, some researchers believe that the ELAN and LAN responses mark working memory demands, and if this is so, then those responses might be expected to be related to the other signals that track language processing demands of any kind. That could explain why they seem to widely benefit (and benefit from) the prediction of other signals. However, the apparent isolation of the N400 from this benefit would be surprising in that case.
We need to be a little careful about over-interpreting the results here; the way that the EEG responses are defined in this dataset means that several of them are spatially overlapping and close to each other temporally, so some signals may spill-over into others. Future studies will be required to tease apart the possibilities suggested by this analysis, but we believe that this methodology is a promising direction. Multitask learning can help us understand complex relationships between EEG signals. We can also partially address the concern about signal spill-over by including other prediction tasks.
Two additional tasks we can include are prediction of self-paced reading times (in which words are shown one-by-one and the experiment participant presses a button to advance to the next word) and eye-tracking data. Both are available from different experiment participants for the sentences that the EEG signals were collected on. Self-paced reading times and eye-tracking data can both be thought of as measures of reading comprehension difficulty, so we expect that they should be related to the EEG data. Indeed, we see that when these tasks are used in training, both benefit the prediction of the EEG data compared to training on the target EEG signal alone. This result is really interesting because it cannot be explained by any spill-over effect. It suggests that the model might really be learning about some of the latent factors that underlie both EEG responses and behavior (for the detailed results and further discussion of the behavioral data, please see our paper).
It’s really exciting to see how well the EEG signals can be predicted using one of the latest language models, and multitask learning gives us some insight into how the EEG signals relate to each other and to behavioral data. While this analysis method is for now largely exploratory and suggestive, we hope to extend it over time to gain more and more understanding of how the brain processes language. If you’re interested in more information about the method or further discussion of the results, please check out our paper here.
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.