Automated decision-making is one of the core objectives of artificial intelligence. Not surprisingly, over the past few years, entire new research fields have emerged to tackle that task. This blog post is concerned with regret minimization, one of the central tools in online learning. Regret minimization models the problem of repeated online decision making: an agent is called to make a sequence of decisions, under unknown (and potentially adversarial) loss functions. Regret minimization is a versatile mathematical abstraction, that has found a plethora of practical applications: portfolio optimization, computation of Nash equilibria, applications to markets and auctions, submodular function optimization, and more.
In this blog post, we will be interested in showing how one can compose regret-minimizing agents—or regret minimizers for short. In other words, suppose that you are given a regret minimizer that can output good decisions on a set \(\mathcal{X}\) and another regret minimizer that can output good decisions on a set \(\mathcal{Y}\). We show how you can combine them and build a good regret minimizer for a composite set obtained from \(\mathcal{X}\) and \(\mathcal{Y}\)—for example their Cartesian product, their convex hull, their intersection, and so on. Our approach will treat the two regret minimizers, one for \(\mathcal{X}\) and one for \(\mathcal{Y}\), as black boxes. This is tricky: we simply combine them without opening the box, so we must account for the possibility of having to combine very different regret minimizers. On the other hand, the benefit is that we are free to pick the best regret minimizers for each individual set. This is important. For example, consider an extensive-form game: we might know how to build specialized regret minimizers for different parts of the game. We figured out how to combine these regret minimizers to build a composite regret minimizer that can handle the whole game. All material is based off of a recent paper that appeared at ICML 2019.
By the end of the blog post, I will give several applications of this calculus. It enables one to do several things which were not possible before. It also gives a significantly simpler proof of counterfactual regret minimization(CFR), the state-of-the-art scalable method for computing Nash equilibrium in large extensive-form games. The whole exact CFR algorithm falls out naturally, almost trivially, from our calculus.
Regret Minimizer: An Abstraction for Repeated Decision Making
A regret minimizer is an abstraction of a repeated decision-maker. One way to think about a regret minimizer is as a device that supports two operations:
- Output the next decision \(\mathbf{x}^t\), drawn from a convex and bounded domain of decisions \(\mathcal{X}\); and
- Receive/observe a convex loss \(\ell^{t-1}\) function meant to evaluate the last decision \(\mathbf{x}^{t-1}\) that was output. The loss function is revealed after the decision \(\mathbf{x}^{t-1}\) has been made, and it could have been chosen adversarially by the environment.
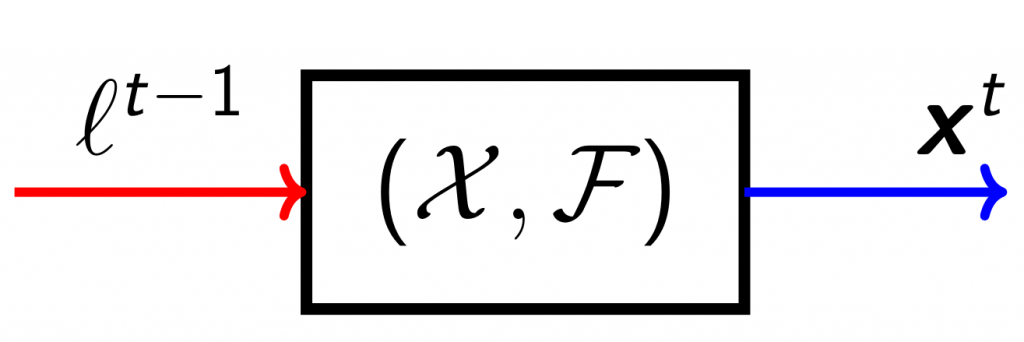 Figure 1: Pictorial representation of a regret minimizer. Left, in red, is the loss function. Right, in blue, is the output decision. \(\mathcal{X}\) and \(\mathcal{F}\) denote the domain of decisions and loss functions, respectively.
Figure 1: Pictorial representation of a regret minimizer. Left, in red, is the loss function. Right, in blue, is the output decision. \(\mathcal{X}\) and \(\mathcal{F}\) denote the domain of decisions and loss functions, respectively. The decision making is online, in the sense that each decision is made by only taking into account the past decisions and their corresponding loss functions; no information about future losses is available to the regret minimizer at any time. For the rest of the post, we focus on linear losses, that is \(\mathcal{F} = \mathcal{L}\) where \(\mathcal{L}\) denotes the set of all linear functions with domain \(\mathcal{X}\).
Regret as a Quality Metric
The quality metric for a regret minimizer is its cumulative regret. Intuitively, it measures how well the regret minimizer did against the best, fixed decision in hindsight. We can formalize this idea mathematically as the difference between the loss that was cumulated, \(\sum_{t=1}^T \ell^t(\mathbf{x}^t)\), and the minimum possible cumulative loss, \(\min_{\hat{\mathbf{x}}\in\mathcal{X}} \sum_{t=1}^T \ell^t(\hat{\mathbf{x}})\). In formulas, the cumulative regret up to time \(T\) is defined as $$\displaystyle R^T := \sum_{t=1}^T \ell^t(\mathbf{x}^t) – \min_{\hat{\mathbf{x}} \in \mathcal{X}} \sum_{t=1}^T \ell^t(\hat{\mathbf{x}}).$$
Good Regret Minimizers
“Good” regret minimizers, also called Hannan consistent regret minimizers, are such that their cumulative regret grows sublinearly as a function of \(T\). Several good and general-purpose regret minimizers are known in the literature. Some of them, like follow-the-regularized-leader, online mirror descent, and online (projected) gradient descent work for any convex domain \(\mathcal{X}\). Other are tailored for specific domains, such as regret matching and regret matching plus, both of which are specifically designed for the case in which \(\mathcal{X}\) is a (probability) simplex. However, these general-purpose regret minimizers typically come with two drawbacks:
- They need a notion of projection onto the domain of decisions \(\mathcal{X}\), which can be computationally expensive in practice; and
- They are monolithic: they cannot take advantage of the specific combinatorial structure of their domain.
Given the drawbacks of the traditional approaches, we started to wonder about different ways to construct regret minimizers, until we stumbled upon this intriguing thought: can we construct regret minimizers for composite sets by combining regret minimizers for the individual atoms? The answer is yes 🙂
Warm-Up: Cartesian Products
Let’s start from a simple example. Suppose we have a regret minimizer that outputs decisions on a convex set \(\mathcal{X}\), and another regret minimizer that outputs decisions on a convex set \(\mathcal{Y}\). How can we combine them to obtain a regret minimizer for their Cartesian product \(\mathcal{X} \times \mathcal{Y}\)? The natural idea, in this case, is to let the two regret minimizers operate independently:
- Every time we need to output a decision on \(\mathcal{X} \times \mathcal{Y}\), we ask the regret minimizer for \(\mathcal{X}\) and \(\mathcal{Y}\) to independently output their next decisions \(\mathbf{x}^{t+1}\) and \(\mathbf{y}^{t+1}\) on \(\mathcal{X}\) and \(\mathcal{Y}\) respectively, and output the pair \((\mathbf{x}^{t+1}, \mathbf{y}^{t+1})\).
- Every time we receive a linear loss function \(\ell^t\) (defined over \(\mathcal{X}\times\mathcal{Y}\)), we separate the components that refer to \(\mathcal{X}\) and \(\mathcal{Y}\) respectively, and feed them into the regret minimizers for \(\mathcal{X}\) and \(\mathcal{Y}\).
This process is represented pictorially in Figure 2. We coin this type of pictorial representation a “regret circuit”.
 Figure 2: Regret circuit for the Cartesian product of two sets \(\mathcal{X}\) and \(\mathcal{Y}\)
Figure 2: Regret circuit for the Cartesian product of two sets \(\mathcal{X}\) and \(\mathcal{Y}\)Some simple algebra shows that, at all time \(T\), our strategy guarantees that the cumulative regret \(R^T\) of the composite regret minimizer (as seen from outside of the gray dashed box), satisfies \(R^T = R_\mathcal{X}^T + R_\mathcal{Y}^T\), where \(R_\mathcal{X}^T\) and \(R_\mathcal{Y}^T\) are the cumulative regrets of the regret minimizers for domains \(\mathcal{X}\) and \(\mathcal{Y}\) respectively. Hence, if both of those regret minimizers are “good” (Hannan consistent), than so is the composite regret minimizer.
A Harder Example: Convex Hull
What about convex hulls? It turns out that this is much trickier! We can try to reuse the same approach as before: we ask the two regret minimizers, one for \(\mathcal{X}\) and one for \(\mathcal{Y}\), to independently output decisions. But now we run into this dilemma as to how we should form a convex combination between the two decisions.
Big idea: use a third regret minimizer to decide how to “mix” the recommendations from \(\mathcal{X}\) and \(\mathcal{Y}\)
In this case, the regret circuit is shown in Figure 3.
 Figure 3: Regret circuit for the convex hull of two sets \(\mathcal{X}\) and \(\mathcal{Y}\).
Figure 3: Regret circuit for the convex hull of two sets \(\mathcal{X}\) and \(\mathcal{Y}\).If the loss function \(\ell_{\lambda}^{t-1}\) that enters the extra regret minimizer is set up correctly, and if all three internal regret minimizers are good, one can prove that the composite regret minimizer, as seen from outside of the gray dashed box, is also a good regret minimizer. In particular, a natural way to define \(\ell_{\lambda}^{t}\) is as
\[
\ell^t_\lambda : \Delta^{2} \ni (\lambda_1,\lambda_2) \mapsto \lambda_1 \ell^t(\mathbf{x}^t) + \lambda_2\ell^t(\mathbf{y}^t),
\]
which can be seen as a form of counterfactual loss function.
Application: Counterfactual Regret Minimization
It turns out that the two regret circuits we’ve seen so far—one for the Cartesian product and one for the convex hull of two sets—are already enough to give a very natural proof of the counterfactual regret minimization (CFR) framework, a family of regret minimizers, specifically tailored for extensive-form games. CFR has been the de facto state of the art for the past 10+ years for computing approximate Nash equilibria in large games and has been one of the key technologies that allowed to solve large Heads-Up Limit and No-Limit Texas Hold’Em. The basic intuition is as follows (all details are in our paper). Consider for example the sequential action space of the first player in the game of Kuhn poker (Figure 4, left):
- Every time we have to take an action in a game, we are effectively deciding how to break probability mass down onto different subtrees. Intuitively, this corresponds to a convex hull operation.
- Every time we make an observation, we need to have a contingency plan for each possible outcome and formulate a strategy for each possible observation. This is a Cartesian product operation.
In other words, we can represent the strategy of the player by composing convex hulls and Cartesian products, following the structure of the game (Figure 4, right).
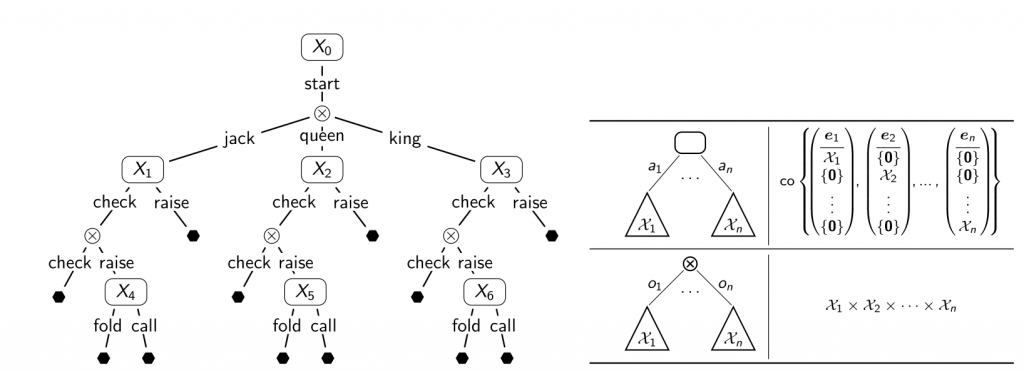 Figure 4: (Left) Sequential action space for the first player in the game of Kuhn poker. (Right) Inductive construction rules.
Figure 4: (Left) Sequential action space for the first player in the game of Kuhn poker. (Right) Inductive construction rules.
Since we can express the set of strategies in the game by composing convex hulls and Cartesian products, it should now be clear how our framework assists us in constructing a regret minimizer for this domain.
Intersections and Constraint Satisfaction
After having seen Cartesian products and convex hulls, a natural question is: what about intersections and constraint satisfaction? In this case, we assume to have access to a good regret minimizer for a domain \(\mathcal{X}\), and we want to somehow construct a good regret minimizer for the curtailed set \(\mathcal{X} \cap \mathcal{Y}\).
It turns out that, in general, these constraining operations are more costly than “enlarging” operations such as convex hull, Minkowski sums, Cartesian products, etc. In the paper, we show two different circuits:
- One is approximate and does not maintain feasibility (that is, some \(\mathbf{x}^t\) might fall outside of the domain of decisions \(\mathcal{X}\)). However, this circuit is very cheap to evaluate and does not use any notion of projection.
- The other guarantees feasibility, but at the cost of using (generalized) projections.
The main idea for both circuits is to use the regret minimizer for \(\mathcal{X}\) output decisions, and then penalize infeasible choices by injecting extra penalization terms in the loss functions that enter the regret minimizer for \(\mathcal{X}\). In the case of the circuit that guarantees feasibility, the decisions are also projected onto \(\mathcal{X} \cap \mathcal{Y}\) before they are output by the composite regret minimizer. Figure 5 shows the resulting regret circuits, where \(d\) is the distance-generating function used in the projection (for example, a good choice could be \(d(\mathbf{x}) = \|\mathbf{x}\|^2_2\)), and \(\alpha^t\) is a penalization coefficient.
While here we are not interested in all the details of this circuit, we remark an interesting observation: the regret circuit is a constructive proof of the fact that we can always turn an infeasible regret minimizer into a feasible one by projecting onto the feasible set, outside the loop!
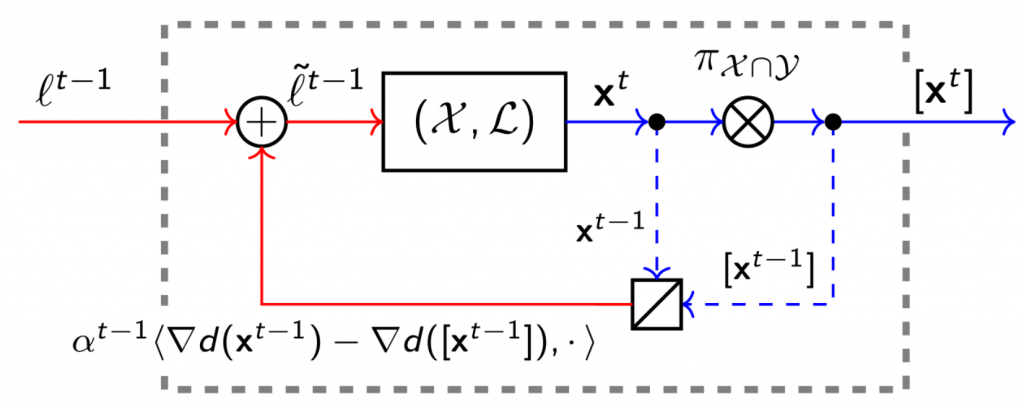 Figure 5: Regret circuit for the intersection of \(\mathcal{X}\) and \(\mathcal{Y}\). The symbol \([\mathbf{x}^t]\) denotes the projection \(\pi_{\mathcal{X}\cap\mathcal{Y}}(\mathbf{x}^t)\) of \(\mathbf{x}^t\) onto \(\mathcal{X}\cap\mathcal{Y}\).
Figure 5: Regret circuit for the intersection of \(\mathcal{X}\) and \(\mathcal{Y}\). The symbol \([\mathbf{x}^t]\) denotes the projection \(\pi_{\mathcal{X}\cap\mathcal{Y}}(\mathbf{x}^t)\) of \(\mathbf{x}^t\) onto \(\mathcal{X}\cap\mathcal{Y}\).Other Applications
Armed with these new intersection circuits, we can show that the recent Constrained CFR algorithm can be constructed as a special example via our framework. Our exact (feasible) intersection construction leads to a new algorithm for the same problem as well.
Another application is in the realm of optimistic/predictive regret minimization. This is a recent subfield of online learning, whose techniques can be used to break the learning-theoretic barrier \(O(T^{-1/2})\) on the convergence rate of regret-based approaches to saddle points (for example, Nash equilibria). In a different ICML 2019 paper, we used our calculus to prove that, under certain hypotheses, CFR can be modified to have a convergence rate of \(O(T^{-3/4})\) to Nash equilibrium, instead of \(O(T^{-1/2})\) as in the original (non-optimistic) version.
Future Research
Regret circuits have already proved to be useful in several applications, mostly in game theory. The fact that we can combine potentially very different regret minimizers as black boxes is very appealing because it enables to choose the best algorithm for each set that is being composed, and conquer different parts of the design space with different techniques. In the paper, we show regret circuits for several convexity-preserving operations, including convex hull, Cartesian product, affine transformations, intersections, and Minkowski sums. However, several questions remain open:
- Most of the work assumes linear loss functions. For many applications, this is less restrictive than it might seem, because every time we face a non-linear loss function we can use a well-known linearization trick and fall back on our results. However, it would still be interesting to see what can be said about general convex loss functions?
- It would be interesting to derive a full calculus of optimistic/predictive regret minimization.
- Not all intersections are equally hard. Perhaps we could improve on the intersection construction in special cases.
- Let’s develop more circuits! If you have a particular application in mind that could benefit from a specially-designed regret circuit, I would love to hear about that. 🙂