Figure 1: Overview of the setting of unsupervised domain adaptation and its difference with the standard setting of supervised learning. In domain adaptation the source (training) domain is related to but different from the target (testing) domain. During training, the algorithm can only have access to labeled samples from source domain and unlabeled samples from target domain. The goal is to generalize on the target domain.
One of the backbone assumptions underpinning the generalization theory of supervised learning algorithms is that the test distribution should be the same as the training distribution. However in many real-world applications it is usually time-consuming or even infeasible to collect labeled data from all the possible scenarios where our learning system is going to be deployed. For example, consider a typical application of vehicle counting, where we would like to count how many cars are there in a given image captured by the camera. There are over 200 cameras with different calibrations, perspectives, lighting conditions, etc. at different locations in Manhattan. In this case, it is very costly to collect labeled data of images from all the cameras. Ideally, we would collect labeled images for a subset of the cameras and still be able to train a counting system that would work well for all cameras.
 Figure 2: Locations of different cameras in Manhattan.
Figure 2: Locations of different cameras in Manhattan. Domain adaptation deals with the setting where we only have access to labeled data from the training distribution (a.k.a., source domain) and unlabeled data from the testing distribution (a.k.a., target domain). The setting is complicated by the fact that the source domain can be different from the target domain — just like the above example where different images taken from different cameras usually have different pixel distributions due to different perspectives, lighting, calibrations, etc. The goal of an adaptation algorithm is then to generalize to the target domain without seeing labeled samples from it.
In this blog post, we will first review a common technique to achieve this goal based on the idea of finding a domain-invariant representation. Then we will construct a simple example to show that this technique alone does not necessarily lead to good generalization on the target domain. To understand the failure mode, we give a generalization upper bound that decomposes into terms measuring the difference in input and label distributions between the source and target domains. Crucially, this bound allows us to provide a sufficient condition for good generalizations on the target domain. We also complement the generalization upper bound with an information-theoretic lower bound to characterize the trade-off in learning domain-invariant representations. Intuitively, this result says that when the marginal label distributions differ across domains, one cannot hope to simultaneously minimize both source and target errors by learning invariant representations; this provides a necessary condition for the success of methods based on learning invariant representations. All the material presented here is based on our recent work published at ICML 2019.
Adaptation by Learning Invariant Representations
The central idea behind learning invariant representations is quite simple and intuitive: we want to find a representations that is insensitive to the domain shift while still capturing rich information for the target task. Such a representation would allow us to generalize to the target domain by only training with data from the source domain. The pipeline for learning domain invariant representations is illustrated in Figure 3.
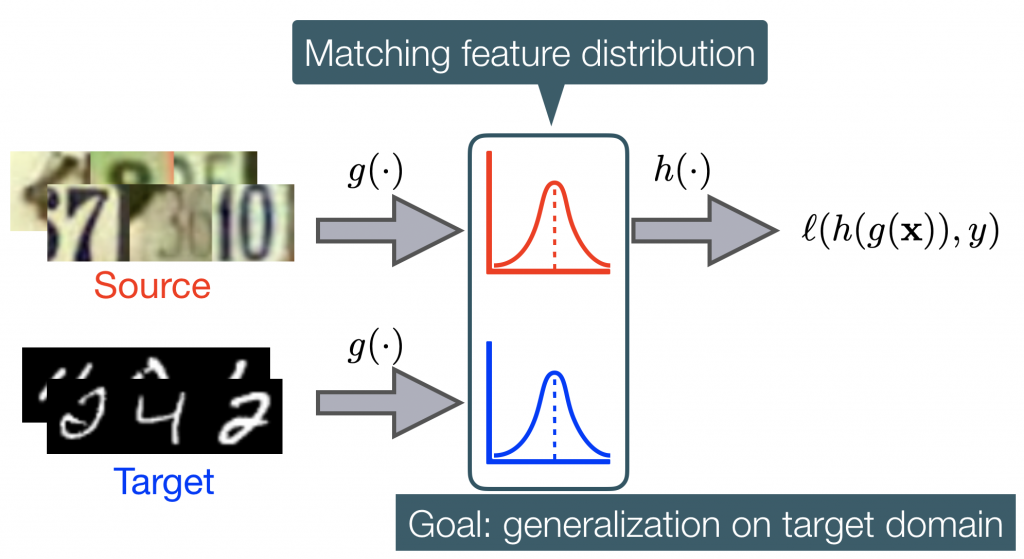 Figure 3: Images from source and target domains are transformed by mapping \(g\) to a representation in which the two domains have similar feature distributions. A hypothesis \(h\) is then trained on labeled data from the source domain and used to generate predictions \(h\circ g\) for the target domain.
Figure 3: Images from source and target domains are transformed by mapping \(g\) to a representation in which the two domains have similar feature distributions. A hypothesis \(h\) is then trained on labeled data from the source domain and used to generate predictions \(h\circ g\) for the target domain.
Note that in the framework above we can use different transformation functions \(g_S/g_T\) on the source/target domain to align the distributions. This powerful framework is also very flexible: by using different measures to align the feature distributions, we recover several of the existing approaches, e.g., DANN (Ganin et al.’ 15), DAN (Long et al.’ 15) and WDGRL (Shen et al.’ 18).
A theoretical justification for the above framework is the following generalization bound by Ben-David et al.’ 10: Let \(\mathcal{H}\) be a hypothesis class and \(\mathcal{D}_S/\mathcal{D}_T\) be the marginal data distributions of source/target domains, respectively. For any \(h\in\mathcal{H}\), the following generalization bound holds: $$\varepsilon_T(h) \leq \varepsilon_S(h) + d(\mathcal{D}_S, \mathcal{D}_T) + \lambda^*,$$ where \(\lambda^* = \inf_{h\in\mathcal{H}} \varepsilon_S(h) + \varepsilon_T(h)\) is the optimal joint error achievable on both domains. At a colloquial level, the above generalization bound shows that the target risk could essentially be bounded by three terms:
- The source risk (the first term in the bound).
- The distance between the marginal data distributions of the source and target domains (the second term in the bound).
- The optimal joint error achievable on both domains (the third term in the bound).
The interpretation of the bound is as follows. If there exists a hypothesis that works well on both domains, then in order to minimize the target risk, one should choose a hypothesis that minimizes the source risk while at the same time aligning the source and target data distributions.
A Counter-example
The above framework for domain adaptation has generated a surge of interest in recent years and we have seen many interesting variants and applications based on the general idea of learning domain-invariant representations. Yet it is not clear whether such methods are guaranteed to succeed when the following conditions are met:
- The composition \(h\circ g\) achieves perfect classification/regression on the source domain.
- The transformation \(g: \mathcal{X}\to\mathcal{Z}\) perfectly aligns source and target domains in the feature space \(\mathcal{Z}\).
Since we can only train with labeled data from the source domain, ideally we would hope that when the above two conditions are met, the composition function \(h\circ g\) also achieves a small risk on the target domain because these two domains are close to each other in the feature space. Perhaps somewhat surprisingly, this is not the case as we demonstrate from the following simple example illustrated in Figure 4.
Consider an adaptation problem where we have input space and feature space \(\mathcal{X} = \mathcal{Z} = \mathbb{R}\) with source domain \(\mathcal{D}_S = U(-1,0)\) and target domain \(\mathcal{D}_T = U(1,2)\), respectively, where we use \(U(a,b)\) to mean a uniform distribution in the interval \((a, b)\). In this example, the two domains are so far away from each other that their supports are disjoint! Now, let’s try to align them so that they are closer to each other. We can do this by shifting the source domain to the right by one unit and then shifting the target domain to the left by one unit.
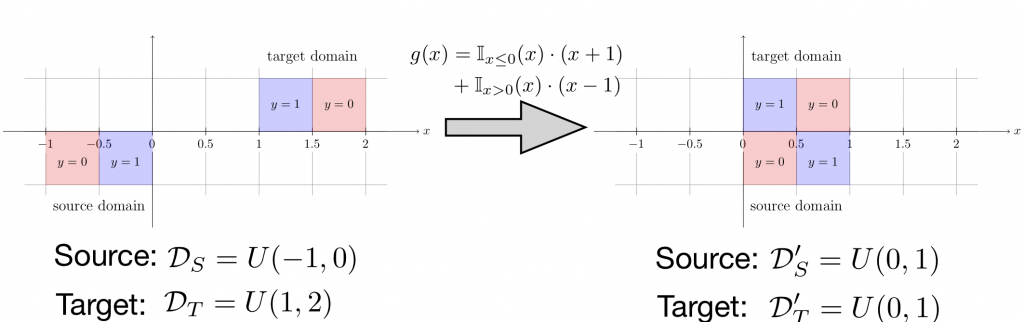 Figure 4: The feature transformation function \(g\) perfectly aligns the source and target domains in the feature space. However, after adaptation any hypothesis that achieves a small risk on the source domain necessarily incurs a large risk on the target domain. In fact no function can have small risk simultaneously on both domains.
Figure 4: The feature transformation function \(g\) perfectly aligns the source and target domains in the feature space. However, after adaptation any hypothesis that achieves a small risk on the source domain necessarily incurs a large risk on the target domain. In fact no function can have small risk simultaneously on both domains.
As shown in Figure 4, after adaptation both domains have distribution \(U(0, 1)\), i.e., they are perfectly aligned by our simple translation transformation. However, due to our construction, now the labels are flipped between the two domains: for every \(x\in (0, 1)\), exactly one of the domains has label 1 and the other has label 0. This implies that if a hypothesis achieves perfect classification on the source domain, it will also incur the maximum risk of 1 on the target domain! In fact, in this case we have \(\varepsilon_S(h) + \varepsilon_T(h) = 1\) after adaptation for any classifier \(h\). As a comparison, before adaptation, a simple interval hypothesis \(h^*(x) = 1\) iff \(x\in (-1/2, 3/2)\) attains perfect classification on both domains.
A Generalization Upper Bound on the Target Error
So what insights can we gain from the previous counter-example? Why do we incur a large target error despite perfectly aligning the marginal distributions of the two domains and minimizing the source error? Does this contradict Ben-David et al.’s generalization bound?
The caveat here is that while the distance between the two domains becomes 0 after the adaptation, the optimal joint error on both domains becomes large. In the counter-example above, this means that after adaptation \(\lambda^{*} = 1\), which further implies \(\varepsilon_T(h) = 1\) if \(\varepsilon_S(h) = 0\). Intuitively, from Figure 4 we can see that the labeling functions of the two domains are “maximally different” from each other after adaptation, but during adaptation we are only aligning the marginal distributions in the feature space. Since the optimal joint error \(\lambda^*\) is often unknown and intractable to compute, could we construct a generalization upper bound that is free of the constant \(\lambda^*\) and takes into account the conditional shift?
Here is an informal description of what we show in our paper: Let \(f_S\) and \(f_T\) be the labeling functions of the source and target domains. Then for any hypothesis class \(\mathcal{H}\) and any \(h\in\mathcal{H}\), the following inequality holds: $$\varepsilon_T(h) \leq \varepsilon_S(h) + d(\mathcal{D}_S, \mathcal{D}_T) + \min\{\mathbb{E}_S[|f_S – f_T|], \mathbb{E}_T[|f_S – f_T|]\}.$$
Roughly speaking, the above bound gives a decomposition of the difference of errors between source and target domains. Again, the second term on the RHS measures the difference between the marginal data distributions. But, in place of the optimal joint error term, the third term now measures the discrepancy between the labeling functions of these two domains. Hence, this bound says that just aligning the marginal data distributions is not sufficient for adaptation, we also need to ensure that the label functions (conditional distributions) are close to each other after adaptation.
An Information-Theoretic Lower Bound on the Joint Error
In the counter-example above, we demonstrated that aligning the marginal distributions and achieving a small source error is not sufficient to guarantee a small target error. But in this example, it is actually possible to find another feature transformation that jointly aligns both the marginal data distributions and the labeling functions. Specifically, let the feature transformation \(g(x) = \mathbb{I}_{x\leq 0}(x)(x+1) + \mathbb{I}_{x > 0}(x)(2-x)\). Then, it is straightforward to verify that the source and target domains perfectly align with each other after adaptation. Furthermore, we also have \(\varepsilon_T(h) = 0\) if \(\varepsilon_S(h) = 0\).
Consequently, it is natural to wonder whether it is always possible to find a feature transformation and a hypothesis to align the marginal data distributions and minimize the source error so that the composite function of these two also achieves a small target error? Quite surprisingly, we show that this is not always possible. In fact, finding a feature transformation to align the marginal distributions can provably increase the joint error on both domains. With this transformation, minimizing the source error will only lead to increasing the target error!
More formally, let \(\mathcal{D}_S^Y/\mathcal{D}_T^Y\) be the marginal label distribution of the source/target domain. For any feature transformation \(g: X\to Z\), let \(\mathcal{D}_S^Z/\mathcal{D}_T^Z\) be the resulting feature distribution by applying \(g(\cdot)\) to \(\mathcal{D}_S/\mathcal{D}_T\) respectively. Furthermore, define \(d_{\text{JS}}(\cdot, \cdot)\) to be the Jensen-Shannon distance between a pair of distributions. Then, for any hypothesis \(h: Z\to\{0, 1\}\), if \(d_{\text{JS}}(\mathcal{D}_S^Y, \mathcal{D}_T^Y) \geq d_{\text{JS}}(\mathcal{D}_S^Z, \mathcal{D}_T^Z)\), the following inequality holds: $$\varepsilon_S(h\circ g) + \varepsilon_T(h\circ g)\geq \frac{1}{2}\left(d_{\text{JS}}(\mathcal{D}_S^Y, \mathcal{D}_T^Y) – d_{\text{JS}}(\mathcal{D}_S^Z, \mathcal{D}_T^Z)\right)^2.$$
Let’s parse the above lower bound step by step. The LHS corresponds to the joint error achievable by the composite function \(h\circ g\) on both the source and the target domains. The RHS contains the distance between the marginal label distributions and the distance between the feature distributions. Hence, when the marginal label distributions \(\mathcal{D}_S^Y/\mathcal{D}_T^Y\) differ between two domains, i.e., \(d_{\text{JS}}(\mathcal{D}_S^Y, \mathcal{D}_T^Y) > 0\), aligning the marginal data distributions by learning \(g(\cdot)\) will only increase the lower bound. In particular, for domain-invariant representations where \(d_{\text{JS}}(\mathcal{D}_S^Z, \mathcal{D}_T^Z) = 0\), the lower bound attains its maximum value of \(\frac{1}{2}d^2_{\text{JS}}(\mathcal{D}_S^Y, \mathcal{D}_T^Y)\). Since in domain adaptation we only have access to labeled data from the source domain, minimizing the source error will only lead to an increase of the target error. In a nutshell, this lower bound can be understood as an uncertainty principle: when the marginal label distributions differ across domains, one has to incur large error in either the source domain or the target domain when using domain-invariant representations.
Empirical Validations
One implication made by our lower bound is that when two domains have different marginal label distributions, minimizing the source error while aligning the two domains can lead to increased target error. To verify this, let us consider the task of digit classification on the MNIST, SVHN and USPS datasets. The label distributions of these three datasets are shown in Figure 5.
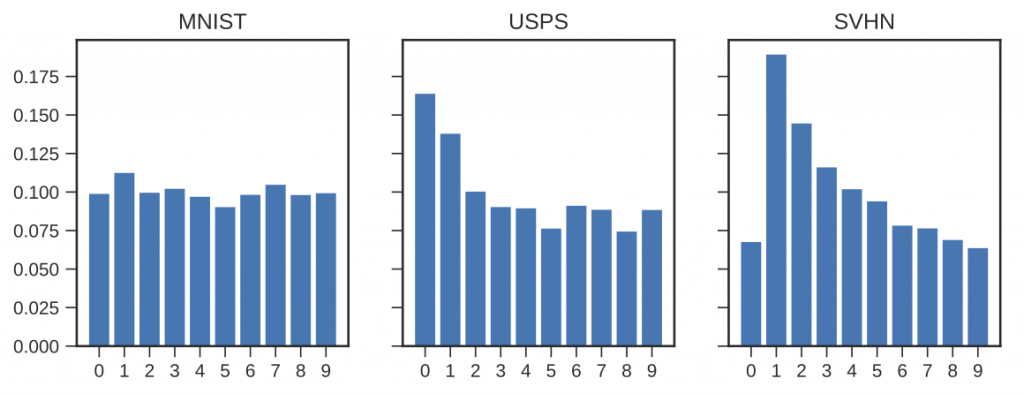 Figure 5: The label (digit) distributions on MNIST, SVHN and USPS.
Figure 5: The label (digit) distributions on MNIST, SVHN and USPS.From Figure 5, it is clear to see that these three datasets have quite different label distributions. Now let’s use DANN (Ganin et al., 2015) to classify on the target domain by learning a domain invariant representation while training to minimize error on the source domain.
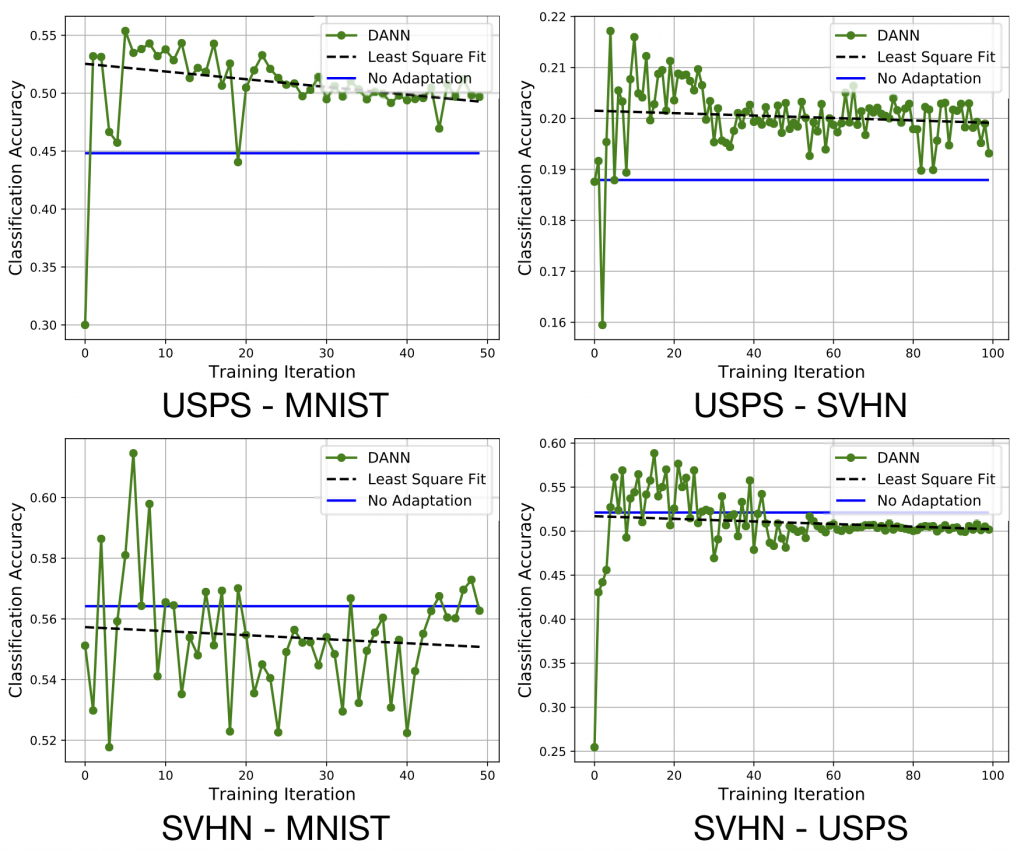 Figure 6: Digit classification on MNIST, USPS and SVHN. The horizontal solid line corresponds to
Figure 6: Digit classification on MNIST, USPS and SVHN. The horizontal solid line corresponds to
the target domain test accuracy without adaptation. The green solid line is the target domain test
accuracy under domain adaptation with DANN. We also plot the least square fit (dashed line) of
the DANN adaptation results to emphasize the negative slope.
We plot four adaptation trajectories for DANN in Figure 6. Across the four adaptation tasks, we can observe the following pattern: the test domain accuracy rapidly grows within the first 10 iterations before gradually decreasing from its peak, despite consistently increasing source training accuracy. These phase transitions can be verified from the negative slopes of the least squares fit of the adaptation curves (dashed lines in Figure 6). The above experimental results are consistent with our theoretical findings: over-training on the source task can indeed hurt generalization to the target domain when the label distributions differ.
Future Work
Note that the failure mode in the above counter-example is due to the increase of the distance between the labeling functions during adaptation. One interesting direction for future work is then to characterize what properties the feature transformation function should have in order to decrease the shift between labeling functions. Of course domain adaptation would not be possible without proper assumptions on the underlying source/target domains. It would be nice to establish some realistic assumptions under which we can develop effective adaptation algorithms that align both the marginal distributions and the labeling functions. Feel free to get in touch if you’d like to talk more!
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.