Figure 1: A two-dimensional convex function represented via contour lines. Each ellipse denotes a contour line. The function value is constant on the boundary of each such ellipse, and decreases as the ellipse becomes smaller and smaller. Let us assume we want to minimize this function starting from a point \(A\). The red line shows the path followed by a gradient descent optimizer converging to the minimum point \(B\), while the green dashed line represents the direct line joining \(A\) and \(B\).
In today’s post, we will discuss an interesting property concerning the trajectory of gradient descent iterates, namely the length of the Gradient Descent curve. Let us assume we want to minimize the function shown in Figure 1 starting from a point \(A\). We deploy gradient descent (GD) to this end, and converge to the minimum point \(B\). The green dashed line represents the direct line joining \(A\) and \(B\). GD however does not initially know the location of \(B\). Instead, it performs local updates that direct it towards \(B\), as represented by the red solid line. Consequently, the length of the red path that GD follows is longer than the direct green path. How long will the red path be? We studied this question and arrived at some interesting bounds on the path length (both upper and lower) in various settings (check out our preprint!). We discuss some of these bounds in this post. But first, we motivate why understanding path lengths could be useful for understanding nonconvex optimization.
Motivation
Consider the following two-dimensional loss surface with multiple global minima, all equivalent in function value. Over-parameterized systems such as deep neural networks may have losses that exhibit a similar structure.
Suppose we were to run GD to minimize the loss function, starting from two different initialization points \(A\) and \(B\). The GD paths in both cases converge to different minima, which have the same function value. Intuitively, we know that because the slope is high, convergence is fast. This is because on the path of interest followed by the GD iterates, the function behaves like a convex function (in fact, a strongly convex function). Yet, our traditional convergence bounds would fail here since they require such properties to hold at a global level. Check out this blog by Prof. Sanjeev Arora for more insights on how our conventional view on optimization is insufficient to explain optimization in some modern machine learning settings.
By proving path length bounds for GD curves, we hope to establish that Gradient Descent explores only a small region of the parameter space. Thus desirable properties such as convexity need only hold in a small region. A number of recent advances toward proving convergence and generalization bounds for deep neural networks depend on path length bounds (for example, this paper). In this post we will discuss some interesting upper and lower bounds on the path length of GD curves under a variety of assumptions on the loss surface. We first begin with a meta-theorem that connects fast convergence with short paths.
Linear Convergence Leads to Short Path Lengths
We know that GD exhibits fast convergence in many situations. Does fast convergence imply that the path followed must be short? Perhaps unsurprisingly, the answer is yes for linear convergence. If the iterates are \(\mathbf{x}_0, \mathbf{x}_1, \mathbf{x}_2, \ldots \) and the optimal point is \(\mathbf{x}^*\), then linear convergence refers to the following recurrent inequality for every \(k\) (assume all norms, denoted by \(\|\cdot\|\), in this post refer to the Euclidean \(\ell_2\) norm):
$$\|\mathbf{x}_k – \mathbf{x}^*\| \leq (1 – c) \|\mathbf{x}_{k-1} – \mathbf{x}^*\|.$$
If linear convergence holds for any iterative optimization algorithm (not just GD), we can derive a path length bound by using the triangle inequality:
Consider the triangle \(\mathbf{x}_k \mathbf{x}_{k+1} \mathbf{x}^*\) above. Assuming \(\|\mathbf{x}_k – \mathbf{x}^*\| = \varphi\), we have a bound \(\|\mathbf{x}_{k+1} – \mathbf{x}^*\| \leq (1 – c)\varphi\) because of linear convergence. Then by the triangle inequality, \(\|\mathbf{x}_{k} – \mathbf{x}_{k+1}\| \leq (2-c) \varphi\). We use the same technique for the next triangle \(\mathbf{x}_{k+1} \mathbf{x}_{k+2} \mathbf{x}^*\) but the length \(\|\mathbf{x}_{k+1} – \mathbf{x}^*\|\) is now smaller than \((1-c)\varphi\) instead of just \(\varphi\). Thus, \(\|\mathbf{x}_{k+1} – \mathbf{x}_{k+2}\| \leq (2-c)(1-c) \varphi\). In this manner, we add up all the contributions starting from \(k = 0\) to \(k = \infty\). This leads to the following geometric series:
$$\begin{align*}\sum_{k=0}^\infty \|\mathbf{x}_{k} – \mathbf{x}_{k+1}\| &\leq \sum_{k=0}^\infty (2-c)(1-c)^k\|\mathbf{x}_{0} – \mathbf{x}^*\| \\ &= \left( \frac{2-c}{c}\right) \|\mathbf{x}_{0} – \mathbf{x}^*\|. \end{align*}$$
Thus the total path of GD, even if we were to run it forever, would still be bounded by the distance between the initial point and the convergent point, times a number that depends on the linear convergence constant \(c\).
Improving the Path Length Bound
The bound we introduced above is very general. It applies to any iterative algorithm as long as linear convergence holds. However, often with generality comes lack of precision. Let us understand the implications for an important class of functions: strongly convex and smooth (SCS) functions. SCS functions satisfy the following two properties, for some \(L \geq \mu > 0\):
- Strong Convexity: \(f\) is convex and additionally for every \(\mathbf{x}, \mathbf{y}\), \(\|\nabla f(\mathbf{x}) – \nabla f(\mathbf{y})\| \geq \mu \|\mathbf{x} – \mathbf{y}\|\).
- Smoothness: for every \(\mathbf{x}, \mathbf{y}\), \(\|\nabla f(\mathbf{x}) – \nabla f(\mathbf{y})\| \leq L \|\mathbf{x} – \mathbf{y}\|\).
The condition number of \(f\) is denoted as \(\kappa := L/\mu\). This number is important because it governs the convergence speed of first order methods such as GD on SCS functions. Linear convergence holds for SCS functions with \(c = 1/\kappa\). Thus the path length bound is \(2\kappa\|\mathbf{x}_0 – \mathbf{x}^*\|\). It turns out that this bound is not tight, and a better upper bound of \(2\sqrt\kappa\|\mathbf{x}_0 – \mathbf{x}^*\|\) can be achieved for SCS functions (as shown in this paper and this paper). In the rest of this blog, we absorb the \(\|\mathbf{x}_0 – \mathbf{x}^*\|\) term in the product in the \(\mathcal{O}\) notation since all bounds are multiplicative with that term.
Is the \(\mathcal{O}(\sqrt\kappa)\) bound tight or can it be improved further? Are there interesting special cases? We studied this problem and found answers to the following two questions:
- Can we derive worst case lower bounds for the path length? We prove lower bounds for other function classes related to SCS functions, namely PLS functions and quadratic objectives (these are both discussed shortly).
- Can the bound be improved for convex quadratic objectives that occur in linear (least squares) regression? Linear regression is a canonical subclass of strongly convex functions that is simple to work with, yet forms an interesting and non-trivial testbed for many theoretical questions in statistics and optimization (for example, sparse regression). Even though the math is more involved for more general cases, principles derived while studying linear regression often continue to work in ‘real-world’ settings. We completely settle the question for linear regression by proving matching lower and upper bounds (upto constants).
Question 1: Deriving Worst Case Lower Bounds for Polyak-Łojasiewicz Smooth (PLS) Functions
PLS functions are a generalization of SCS functions. The smoothness condition for PLS functions is the same as the SCS case but we replace the strong convexity assumption with the following (weaker) condition:
- Polyak-Łojasiewicz Condition: for every \(\mathbf{x}\) such that \(f(\mathbf{x}) \neq f^*\), \(\|\nabla f(\mathbf{x})\|^2 \geq 2\mu \|f(\mathbf{x}) – f^*\|\) (here \(f^*\) is the minimum objective value).
PLS functions are a superset of SCS functions (PLS functions need not even be convex). If the strong convexity assumption is satisfied for some \(\mu \geq 0\), then so is the PL assumption for the same \(\mu\). In this case too, we define the condition number as \(\kappa = L/\mu\). GD on PLS functions continues to exhibit linear convergence. Furthermore, the \(\mathcal{O}(\sqrt\kappa)\) path length bound is true for PLS functions as well. (If you are interested in knowing more about GD on PLS functions, check out this paper!)
Although lower bounds for SCS functions remains an important open question, we were in fact able to show a \(\mathcal{\widetilde{\Omega}}(\min(\sqrt{d}, \kappa^{1/4}))\) worst case lower bound for PLS functions (the \(\mathcal{\widetilde{\Omega}}\) hides \(\log\) factors). To prove this lower bound, we construct a PLS function \(f\) with condition number \(\kappa\) and identify a particular initialization point \(\mathbf{x}_0\) such that the GD path length from this point is lower bounded as claimed.
Suppose our parameter space is \(\mathbb{R}^d\) and \(\mathbf{x}\) is a point in this space. The lower bound function \(f\) we construct is defined as the sum of \(d\) identical scalar functions over each component of the parameter space. That is, \(f(\mathbf{x}) = \sum_{i=1}^d g(\mathbf{x}_i)\), where \(g\) is a scalar PLS function with condition number \(\kappa\) (thus the condition number of \(f\) is also \(\kappa\)). This is a plot of \(g\) over the domain \([0, 1.2]\):
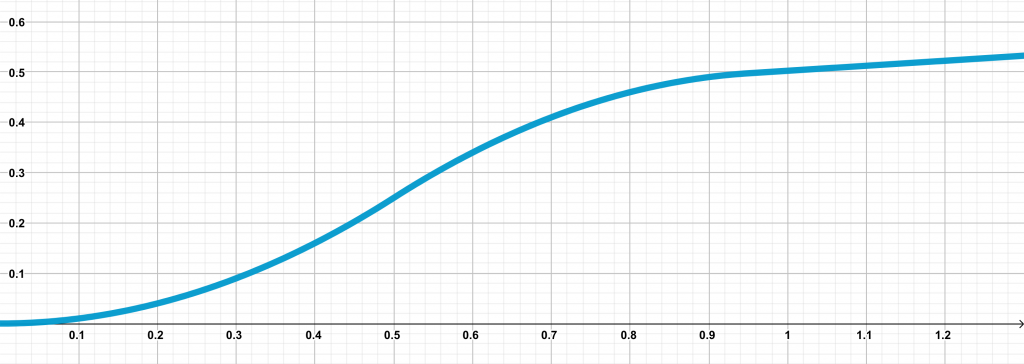
\(g\) is designed so that it is equal to \(x^2\) in the interval (\([0, 0.5]\)) and then gradually tapers off while maintaining the PL curvature condition. We stagger the \(d\) components of the initial point \(\mathbf{x}_0\) so that at every consecutive iterate, a new component enters the interval \([0, 0.5]\). This component exhibits a large decrease of approximately \(0.5\). This way, at every time interval, an additional component is ‘optimized’ from \(0.5\) to almost \(0\). The following figures illustrate this for iterates \(k = 0, 1, 2\). Every colored circle denotes \(\mathbf{x}_i\) for different indices \(i\).
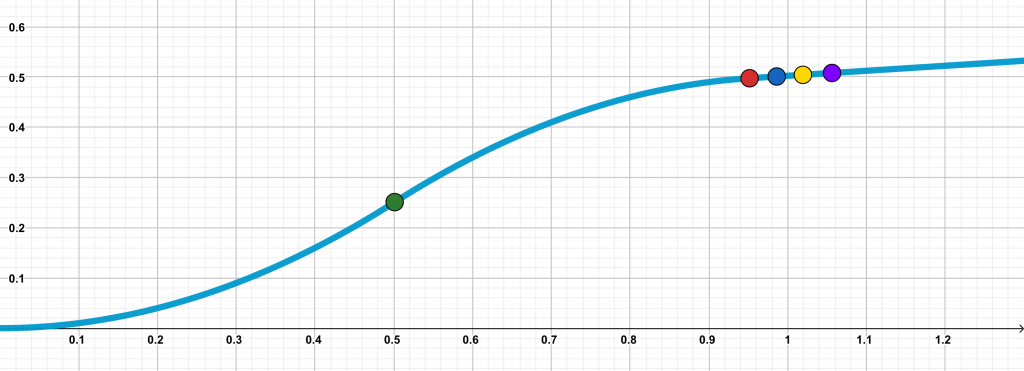 \(k = 0\)
\(k = 0\)
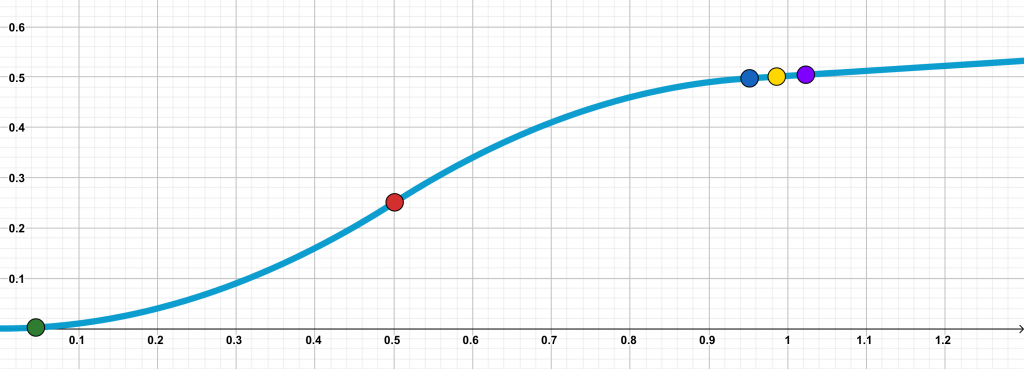 \(k = 1\)
\(k = 1\)
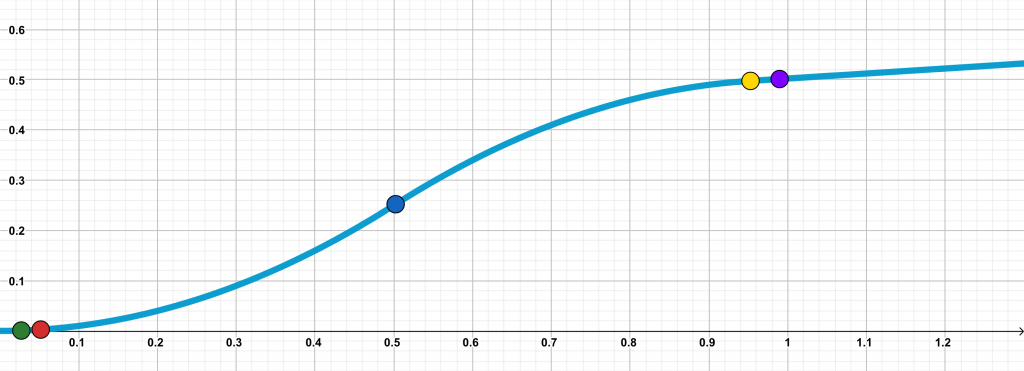 \(k=2\)
\(k=2\)
Our construction thus ensures that the additional path travelled by each iterate is about \(0.5\), and so the total path length is at least about \(0.5d\). However the shortest path is \(\approx \sqrt{1^2 + 1^2 + \ldots + 1^2} = \sqrt{d}\). We conclude that the path followed has length about \(\sqrt{d}\) times the shortest path. Finally, we show that for \(f\), \(\kappa = \Theta(d^2)\). This relates the path length to \(\kappa\) and completes the proof. The broad idea is that instead of moving from the point \((1, 1, \ldots 1)\) to the point \((0, 0, \ldots 0)\) directly through the shortest path, we follow a path aligned with the edges of a \(d\)-dimensional hypercube which is a factor of \(\sqrt{d}\) times the diagonal path.
Question 2: Deriving Matching Upper and Lower Bounds for Convex Quadratic Objectives
The linear regression objective is described as follows. Given an \(n \times d\) matrix \(\mathbf{A}\) and a \(n \times 1\) output vector \(\mathbf{y}\), we wish to solve for the vector \(\mathbf{x}\) that minimizes the least squares objective:
$$\text{min}_\mathbf{x} \|\mathbf{Ax} – \mathbf{y}\|^2.$$
The linear regression objective is strongly convex if the matrix \(\mathbf{A}\) has full column rank. Thus the \(\mathcal{O}(\sqrt\kappa)\) bound for strongly convex functions applies here too (with some modification a similar bound applies even if \(\mathbf{A}\) does not have full column rank). In fact, this was the best known bound prior to our work.
It turns out that this agnostic bound is wildly loose. The right bound is not \(\mathcal{O}(\sqrt{\kappa})\), but instead \(\mathcal{O}(\min(\sqrt{d}, \sqrt{\log{\kappa}})\)! We call it the right bound since we can also prove a \(\mathcal{\Omega}(\min(\sqrt{d}, \sqrt{\log{\kappa}})\) worst case lower bound for convex quadratic functions. We will give some intuition for the proofs here, but for a complete treatment, do look at our paper.
The lower bound can be obtained by considering the behavior of GD on a function whose Hessian \(\mathbf{A}^T\mathbf{A}\) has geometrically increasing singular values \(\omega^0, \omega^1, \omega^2, \ldots, \omega^d\) for a constant \(\omega\). We can then use a similar idea as the PL lower bound to show that in every consecutive iterate a single additional component exhibits large decrease leading to a \(\sqrt{d}\) lower bound. Since \(\kappa = \omega^{d-1}\), we get the \(\mathcal{\Omega}(\sqrt{\log{\kappa}})\) lower bound as well.
The matching upper bound proof is involved, but the key to analysis here is that we can explicitly write down the GD iterates for quadratic objectives. We will discuss this first key step here. For simplicity, assume that \(\mathbf{A}\) has full column rank (the bound holds even without this assumption). The GD update with a step-size \(\eta\) is given by
$$\mathbf{x}_{k+1} = \mathbf{x}_{k} – 2\eta\mathbf{A}^T(\mathbf{A}\mathbf{x}_k – \mathbf{y}).$$
If \(\eta\) is appropriately small, the GD updates will converge to the optimal solution \(\mathbf{x}^* = (\mathbf{A}^T\mathbf{A})^{-1}\mathbf{A}^T\mathbf{y}\). (The solution attained if \(\mathbf{A}\) does not have full column rank can also be written explicitly using the Moore-Penrose pseudoinverse). Using the fact that \(\mathbf{A}^T\mathbf{y} = \mathbf{A}^T\mathbf{A}\mathbf{x}^*\), the above recurrence unravels to give us an explicit form for \(\mathbf{x}_k\):
$$\mathbf{x}_{k} = \mathbf{x}^* + (\mathbf{I}_d – 2\eta\mathbf{A}^T\mathbf{A})^k(\mathbf{x}_0 – \mathbf{x}^*),$$
where \(\mathbf{I}_d\) is the \(d \times d\) identity matrix. The path length can explicitly be written as
$$\begin{align*}\sum_{k = 0}^\infty \|2\eta(\mathbf{A}^T\mathbf{A}) (\mathbf{I}_d – 2\eta\mathbf{A}^T\mathbf{A})^k(\mathbf{x}_0 – \mathbf{x}^*)\|.\end{align*}$$
A standard choice for \(\eta\) ensures that the singular values of \(2\eta\mathbf{A}^T\mathbf{A}\) are \(1 \geq \sigma_1 \geq \sigma_2 \ldots \geq \sigma_d\). Now let \(\alpha_i\) denote the component of \(\mathbf{x}_0 – \mathbf{x}^*\) in the singular vector corresponding to \(\sigma_i\). Then we can rewrite the path length as
$$\begin{align*}\sum_{k = 0}^\infty \sqrt{\sum_{i=1}^d \sigma_i^2 (1 – \sigma_i)^{2k}\alpha_i^{2}}.\end{align*}$$
This immediately leads to the \(\mathcal{O}(\sqrt{d})\) bound. For non-negative \(a_1, a_2, \ldots, a_d\), \(\sqrt{a_1^2 + a_2^2 + \ldots + a_d^2} \leq a_1 + a_2 + \ldots + a_d\), and so we obtain
$$\begin{align*}\sum_{k = 0}^\infty \sqrt{\sum_{i=1}^d \sigma_i^2 (1 – \sigma_i)^{2k}\alpha_i^{2k}} &\leq \sum_{k = 0}^\infty \sum_{i=1}^d \sigma_i (1 – \sigma_i)^{k}\alpha_i
\\ &= \sum_{i=1}^d \alpha_i
\\ &\leq \sqrt{d} \sum_{i=1}^d \sqrt{\alpha_i^2}
\\ &= \sqrt{d}\|\mathbf{x}_0 – \mathbf{x}^*\| .\end{align*}$$
The proof for the \(\mathcal{O}(\sqrt{\log \kappa})\) bound is also elementary but we shall skip the details here.
Bounds for Convex Functions
The story so far summarizes what we know about function classes that exhibit linear convergence (i.e., SCS, PLS, and quadratic objectives). Now, we will discuss convex functions, where GD exhibits sub-linear convergence rates. Here, even the finiteness of GD paths is a non-trivial matter. In particular, there exist convex functions for which GD paths spiral indefinitely around the minimum (as shown here). Yet it can indeed be shown that the total path length is finite. Before discussing the results in this domain, we introduce a cousin of GD that is actually much easier to work with: Gradient Flow (GF). This is the continuous limit of GD obtained by making the step-size infinitesimally small. Instead of an iterate \(k\), suppose we are at some real-valued time \(t \geq 0\) and the current parameter value is \(\mathbf{x}_t\). For some small \(\epsilon > 0\), the parameter update is given as \(\mathbf{x}_{t+\epsilon} = \mathbf{x}_t – \epsilon \nabla f(\mathbf{x}_t)\). By letting \(\epsilon \to 0\), we can represent the instantaneous change in \(\mathbf{x}_t\) as:
$$\begin{align*}\frac{d \mathbf{x}_t}{dt} &= \lim_{\epsilon \to 0} \frac{(\mathbf{x}_{t} – \epsilon \nabla f(\mathbf{x}_t)) – \mathbf{x}_{t}}{\epsilon} \\ &= -\nabla f(\mathbf{x}_t).\end{align*}$$
Evidently, unlike GD, GF has no step-size! This turns out to be massively useful. While analyzing GD we have to deal with the step-size carefully. However we can study GF in the absence of discretization noise induced by the step-size GD. (If you’re wondering why we don’t use GF instead of GD in practice, that’s because GF is a time-dependent differential equation and not an algorithm that can be implemented on a finite state machine). Yet conclusions made on GF continue to generalize to GD. In particular, all the path length bounds we discussed so far hold for both GD and GF.
To illustrate that GF proofs are clean, in this section we work with GF and prove an interesting fact about the GF curve (we don’t go over the GD proof but you can take our word for it—it’s more involved): the self-contractedness of GF curves of quasiconvex functions, a property that leads to path length bounds in this setting. Specifically, a GD or GF curve \(g\) is self-contracted if for any \(s_1 \leq s_2 \leq s_3\):
$$\|g(s_1) – g(s_3)\| \leq \|g(s_2) – g(s_3)\|. \tag{1}$$
Loosely speaking, the above says that for any point \(s \geq 0\), the curve \(g([0, s])\) converges to \(g(s)\). Below are two-dimensional self-contracted curves (left – GF curve, right – GD curve):

Let us prove the self-contractedness of GF curves of quasiconvex functions. Recall that the GF differential equation is \(\frac{d \mathbf{x}_t}{dt}= -\nabla f(\mathbf{x}_t) \). Thus:
$$\begin{align*} \frac{d f(\mathbf{x}_t)}{dt} &= \left( \frac{d f(\mathbf{x}_t)}{d\mathbf{x}_t} \right)^T \left(\frac{d \mathbf{x}_t}{dt}\right) \\ &= (\nabla f(\mathbf{x}_t))^T(-\nabla f(\mathbf{x}_t)) \leq 0. \end{align*}$$
This shows that the function value is non-increasing with \(t\). Now, fix \(t \geq 0\), and let \(s \leq t\) be a free variable. Then:
$$\begin{align*} \frac{d\|\mathbf{x}_s -\mathbf{x}_t\|^2}{ds} &= 2(\mathbf{x}_s -\mathbf{x}_t)^T\left( \frac{d (\mathbf{x}_s -\mathbf{x}_t)}{ds}\right) \\ &= (\mathbf{x}_s -\mathbf{x}_t)^T(-\nabla f(\mathbf{x}_s)) \\ &\leq 0. \end{align*}$$
The final inequality holds by observing that: (a) \(f(\mathbf{x}_t) \leq f(\mathbf{x}_s)\) as proved earlier, and then (b) using the equivalent definition of quasiconvexity for differentiable functions—if \(f(\mathbf{x}) \leq f(\mathbf{y})\), then \(\nabla f(\mathbf{y})^T(\mathbf{x} – \mathbf{y}) \leq 0.\) This implies that \(\|\mathbf{x}_s -\mathbf{x}_t\|\) is non-increasing in \(s\) which is equivalent to Equation (1).
It seems that self-contracted curves have a natural shrinkage property that should lead to a path length bound. This intuition was nailed down using a very interesting geometric proof in this paper and this paper. It was shown that certain smooth self-contracted curves (which includes GF curves) have a path length bound of \(2^{\mathcal{O}(d \log d)}\). In our paper we show that a similar bound also holds for GD curves of smooth convex functions.
Open Questions
One of the most important questions we have yet to answer is identifying lower and upper bounds in the strongly convex case. It would also be interesting to extend the ideas discussed for GD/GF to other iterative algorithms like Accelerated Gradient Descent, Polyak’s Heavy Ball method, Projected Gradient Descent, etc. If you liked this post, we encourage you to go over our paper and perhaps think about some of these open problems yourselves!
DISCLAIMER: All opinions expressed in this posts are those of the author and do not represent the views of Carnegie Mellon University.