Figure 1: An example of federated learning for the task of next-word prediction on mobile phones. Devices communicate with a central server periodically to learn a global model. Federated learning helps preserve user privacy and reduce strain on the network by keeping data localized.
What is federated learning? How does it differ from traditional large-scale machine learning, distributed optimization, and privacy-preserving data analysis? What do we understand currently about federated learning, and what problems are left to explore? In this post, we briefly answer these questions, and describe ongoing work in federated learning at CMU. For a more comprehensive and technical discussion, please see our recent white paper.
What is federated learning?
Federated Learning is privacy-preserving model training in heterogeneous, distributed networks.
Motivation
Mobile phones, wearable devices, and autonomous vehicles are just a few of the modern distributed networks generating a wealth of data each day. Due to the growing computational power of these devices—coupled with concerns about transmitting private information—it is increasingly attractive to store data locally and push network computation to the edge devices. Federated learning has emerged as a training paradigm in such settings. As we discuss in this post, federated learning requires fundamental advances in areas such as privacy, large-scale machine learning, and distributed optimization, and raises new questions at the intersection of machine learning and systems.
Potential applications of federated learning may include tasks such as learning the activities of mobile phone users, adapting to pedestrian behavior in autonomous vehicles, or predicting health events like heart attack risk from wearable devices. We discuss two canonical applications in more detail below.
- Learning over smart phones. By jointly learning user behavior across a large pool of mobile phones, statistical models can power applications such as next-word prediction, face detection, and voice recognition. However, users may not be willing to physically transfer their data to a central server in order to protect their personal privacy or to save the limited bandwidth/battery power of their phones. Federated learning has the potential to enable predictive features on smart phones without diminishing the user experience or leaking private information. Figure 1 illustrates an application where we aim to learn a next-word predictor in a large-scale mobile phone network based on users’ historical text data.
- Learning across organizations. Organizations such as hospitals can also be viewed as remote ‘devices’ that contain a multitude of patient data for predictive healthcare. However, hospitals operate under strict privacy practices, and may face legal, administrative, or ethical constraints that require data to remain local. Federated learning is a promising solution for these applications, as it can reduce strain on the network and enable private learning between various devices/organizations. Figure 2 depicts an example application in which a model is learned from distributed electronic health data.
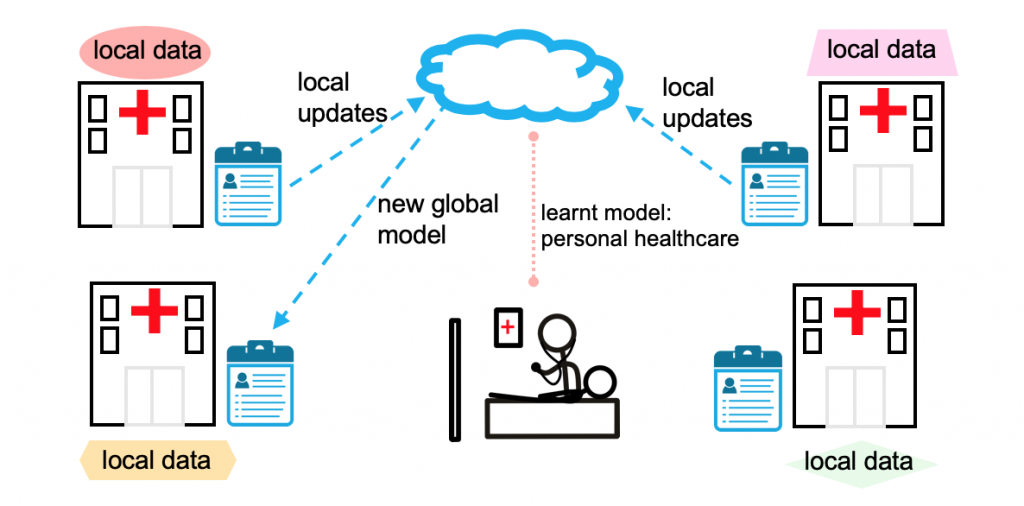 Figure 2. Another application of federated learning for personal healthcare via learning over heterogeneous electronic medical records distributed across multiple hospitals.
Figure 2. Another application of federated learning for personal healthcare via learning over heterogeneous electronic medical records distributed across multiple hospitals.
Federated learning has been deployed in practice by major companies, and plays a critical role in supporting privacy-sensitive applications where the training data are distributed at the edge. Next, we formalize the problem of federated learning and describe some of the fundamental challenges associated with this setting.
What are the challenges in federated learning?
Problem formulation
The canonical federated learning problem involves learning a single, global statistical model from data stored on tens to potentially millions of remote devices. In particular, the goal is typically to minimize the following objective function:
$$\min_w F(w), ~\text{where}~ F(w) := \sum_{k=1}^m p_k F_k(w)$$
Here \(m\) is the total number of devices, \(F_k\) is the local objective function for the \(k\)th device, and \(p_k\) specifies the relative impact of each device with \(p_k ≥ 0 \) and \( \sum_{k=1}^m p_k = 1 \).
The local objective function \(F_k\) is often defined as the empirical risk over local data. The relative impact of each device \(p_k\) is user-defined, with two natural settings being \(p_k = \frac{1}{m}\) or \(p_k = \frac{n_k}{n}\), where \(n\) is the total number of samples over all devices. Although this is a common federated learning objective, there exist other alternatives such as simultaneously learning distinct but related local models via multi-task learning (Smith et al, 2017) where each device corresponds to a task. Both the multi-task and meta-learning perspectives enable personalized or device-specific modeling, which can be a natural approach to handle the statistical heterogeneity of the data.
At first sight, both federated learning and classical distributed learning share a similar goal of minimizing the empirical risk over distributed entities. However, there are fundamental challenges associated with solving the above objective in the federated settings, as we describe below.
How does federated learning differ from classical distributed learning in data center environments?
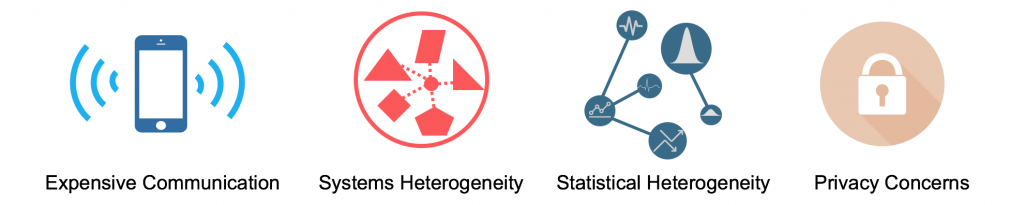 Figure 3. Four fundamental challenges in federated learning.
Figure 3. Four fundamental challenges in federated learning.
- Challenge 1: Expensive Communication: Federated networks are potentially comprised of a massive number of devices (e.g., millions of smart phones), and communication in the network can be slower than local computation by many orders of magnitude. Communication in such networks can be much more expensive than that in classical data center environments. In order to fit a model to data generated by the devices in a federated network, it is therefore necessary to develop communication-efficient methods that iteratively send small messages or model updates as part of the training process, as opposed to sending the entire dataset over the network.
- Challenge 2: Systems Heterogeneity: The storage, computational, and communication capabilities of each device in federated networks may differ due to variability in hardware (CPU, memory), network connectivity (3G, 4G, 5G, wifi), and power (battery level). Additionally, the network size and systems-related constraints on each device typically result in only a small fraction of the devices being active at once. For example, only hundreds of devices may be active in a million-device network. Each device may also be unreliable, and it is not uncommon for an active device to drop out at a given iteration. These system-level characteristics make issues such as stragglers and fault tolerance significantly more prevalent than in typical data center environments.
- Challenge 3: Statistical Heterogeneity: Devices frequently generate and collect data in a non-identically distributed manner across the network. For example, mobile phone users may have varied use of language in the context of a next word prediction task. Moreover, the number of data points across devices may vary significantly, and there may be an underlying structure present that captures the relationship amongst devices and their associated distributions. This data generation paradigm violates frequently-used I.I.D. assumptions in distributed optimization, increases the likelihood of stragglers, and may add complexity in terms of modeling, analysis, and evaluation.
- Challenge 4: Privacy Concerns: Finally, privacy is often a major concern in federated learning applications compared with learning in data centers. Federated learning takes a step towards protecting user data by sharing model updates (e.g., gradient information) instead of the raw data. However, communicating model updates throughout the training process can nonetheless reveal sensitive information, either to a third-party, or to the central server. While recent methods aim to enhance the privacy of federated learning by using tools such as secure multiparty computation or differential privacy, these approaches often provide privacy at the cost of reduced model performance or system efficiency. Understanding and balancing these trade-offs, both theoretically and empirically, is a considerable challenge in realizing private federated learning systems.
These challenges resemble classical problems in areas such as privacy, large-scale machine learning, and distributed optimization. For instance, numerous methods have been proposed to tackle expensive communication in the machine learning, optimization, and signal processing communities. However, prior methods are typically unable to fully handle the scale of federated networks, much less the challenges of systems and statistical heterogeneity. Similarly, while privacy is an important aspect for many machine learning applications, privacy-preserving methods for federated learning can be challenging to rigorously assert due to the statistical variation in the data, and may be difficult to implement due to systems constraints on each device and across the potentially massive network. Our white paper provides more details about each of these core challenges, including a review of recent work and connections with classical results.
Federated Learning @ CMU
Federated learning is an active area of research across CMU. Below, we highlight a sample of recent projects by our group and close collaborators that address some of the unique challenges in federated learning.
[S. Caldas, S. Duddu, P. Wu, T. Li, J. Konečný, B. McMahan, V. Smith, A. Talwalkar]
The field of federated learning is in its nascency, and we are at a pivotal time to shape the developments made in this area and ensure that they are grounded in real-world settings, assumptions, and datasets. LEAF is a modular benchmarking framework for learning in federated settings. It includes a suite of open-source federated datasets, a rigorous evaluation framework, and a set of reference implementations to facilitate both the reproducibility of empirical results and the dissemination of new solutions for federated learning.
[T. Li, A. K. Sahu, M. Sanjabi, M. Zaheer, A. Talwalkar, V. Smith]
While the current state-of-the-art method for federated learning, FedAvg (McMahan et al, 2017), has demonstrated empirical success, it does not fully address the underlying challenges associated with heterogeneity, and can diverge in practice. This work introduces an optimization framework, FedProx, to tackle systems and statistical heterogeneity. FedProx adds a proximal term to the local loss functions, which (1) makes the method more amenable to theoretical analysis in the presence of heterogeneity, and (2) demonstrates more robust empirical performance than FedAvg.
[T. Li, M. Sanjabi, A. Beirami, V. Smith]
Naively minimizing an aggregate loss function in a heterogeneous federated network may disproportionately advantage or disadvantage some of the devices. This work proposes q-Fair Federated Learning (q-FFL), a novel and flexible optimization objective inspired by fair resource allocation in wireless networks that encourages a more fair accuracy distribution by adaptively imposing higher weight to devices with higher loss. To solve q-FFL, the authors devise a communication-efficient method that can be implemented at scale across hundreds to millions of devices.
[M. Khodak, M. Balcan, A. Talwalkar]
Gradient-based meta learning (GBML) aims to learn good meta-initializations for gradient descent methods for new tasks, and can be applied to federated settings where each device can be viewed as a task. The authors propose a theoretical framework, Average Regret-Upper-Bound Analysis (ARUBA), that connects GBML to online convex optimization, and improves the existing transfer-risk bounds in meta-learning. In applications, ARUBA leads to better methods for federated learning and few-shot learning via learning a per-coordinate learning rate. It also serves as the foundation for the differentially private meta learning work (described below).
[J. Li, M. Khodak, S. Caldas, A. Talwalkar]
Parameter-transfer is a well-known approach for meta-learning, with applications including federated learning. However, parameter-transfer algorithms often require sharing models that have been trained on the samples from specific tasks, thus leaving the task-owners susceptible of privacy leakage. This work formalizes the notion of task-global differential privacy as a practical relaxation of more commonly studied threat models. The authors then propose a new differentially private algorithm for gradient-based parameter transfer that retains provable transfer learning guarantees in convex settings.
Future Directions
Although recent work has begun to address the challenges discussed in this post, there are a number of critical open directions in federated learning that are yet to be explored. We briefly list some open problems below.
- Extreme communication schemes: It remains to be seen how much communication is necessary in federated learning. For example, can we gain a deeper theoretical and empirical understanding of one-shot/few-shot communication schemes in massive and statistically heterogeneous networks?
- Novel models of asynchrony: Two communication schemes most commonly studied in distributed optimization are bulk synchronous and asynchronous approaches. However, in federated networks, each device is often undedicated to the task at hand and most devices are not active on any given iteration. Can we devise device-centric communication models beyond synchronous and asynchronous training, where each device can decide when to interact with the server (rather than being dedicated to the workload)?
- Heterogeneity diagnostics: Recent works have aimed to quantify statistical heterogeneity through various metrics, though these metrics must be calculated during training. This motivates the following questions: Are there simple diagnostics that can be used to quantify systems and statistical heterogeneity before training? Can these diagnostics be exploited to further improve the convergence of federated optimization methods?
- Granular privacy constraints: Privacy is typically defined at either a local or global level with respect to all devices in the network. However, in practice, it may be necessary to define privacy on a more granular level, as privacy constraints may differ across devices or even across data points on a single device. Can we define more granular notions of privacy and develop methods to handle mixed (device-specific or sample-specific) privacy restrictions?
- Productionizing federated learning: There are a number of practical concerns that arise when running federated learning in production. For example, how can we handle issues such as concept drift (when the underlying data-generation model changes over time); diurnal variations (when the devices exhibit different behavior at different times of the day or week); and cold start problems (when new devices enter the network)?
These challenging problems (and more) will require collaborative efforts from a wide range of research communities.
Learn more?
See our recent white paper: Federated Learning: Challenges, Methods, and Future Directions
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of Carnegie Mellon University.