Figure 1. Illustration of the tradeoff between statistical parity and optimal decision making. In this example, due to the different population-level repayment rates between the Circle and Square groups, to obey statistical parity, the decision maker must either deny loans to some repaying Circle applicants (left) or grant loans to some defaulting Square applicants (right).
Example adjusted from the book “The Ethical Algorithm”.
With the prevalence of machine learning applications in high-stakes domains (e.g., criminal judgment, medical testing, online advertising, etc.), it is crucial to ensure that these decision-support systems do not propagate existing bias or discrimination that might exist in historical data. Broadly speaking, there are two central notions of fairness in the algorithmic fairness literature. The first one is individual fairness, which basically asks fair algorithms to treat similar individuals similarly. However, in practice, it is often hard to find or design a socially-acceptable distance metric that captures similarity between individuals with respect to a specific task. Instead, in this blog post, we focus on the second notion of fairness, group fairness, and more specifically statistical parity, which essentially requires that a predictor’s outcomes be equal across different subgroups.
As an example, let’s consider the following problem of loan granting. Suppose there are two groups of applicants in this virtual world: Circles and Squares. The goal of an automated loan approval system \(C\) is to predict whether an applicant will repay the loan \((C(X) = 1)\) or not \((C(X) = 0)\) if granted, given a description \(X\) of the applicant. If we use \(A = 0/1\) to mean that an applicant is from the Circles/Squares group, respectively, then the definition of statistical parity says: $$\Pr(C(X) = 1\mid A = 0) = \Pr(C(X) = 1 \mid A = 1),$$ where the probability is taken over the joint distribution \(\mathcal{D}\) of \(X, A, Y\) (the description of the applicant, the applicant’s group identity, and the ground-truth label of whether the applicant will repay or not). Put another way, statistical parity requires that the predictor \(C(X)\) is independent of the group attribute \(A\): \(C(X)\perp A\).
Learning Fair Representations
One way to build classifiers that (approximately) satisfy statistical parity while preserving task utility as much as possible is by learning fair representations. At a high level, this line of work seeks to find a Rich \(Z\) (thanks to Prof. Richard Zemel), a feature transformation of the input variable \(X\) such that \(Z\) is (approximately) independent of \(A\) while still containing rich information with respect to the target \(Y\). This goal can be formalized as the following optimization problem: $$\max_{Z = g(X)}\quad I(Y; Z) \\ \text{subject to} \quad I(A; Z)\leq \epsilon,$$ where \(\epsilon > 0\) is a preset constant and we use \(I(\cdot;\cdot)\) to denote the mutual information between two random variables. The maximum in the objective function is over all possible feature transformations. Due to recent advances in learning representations with deep neural networks, one algorithmic implementation of the above optimization problem is via adversarial training, as illustrated in Figure 2. This specific methodology dates back at least to Edwards et al.
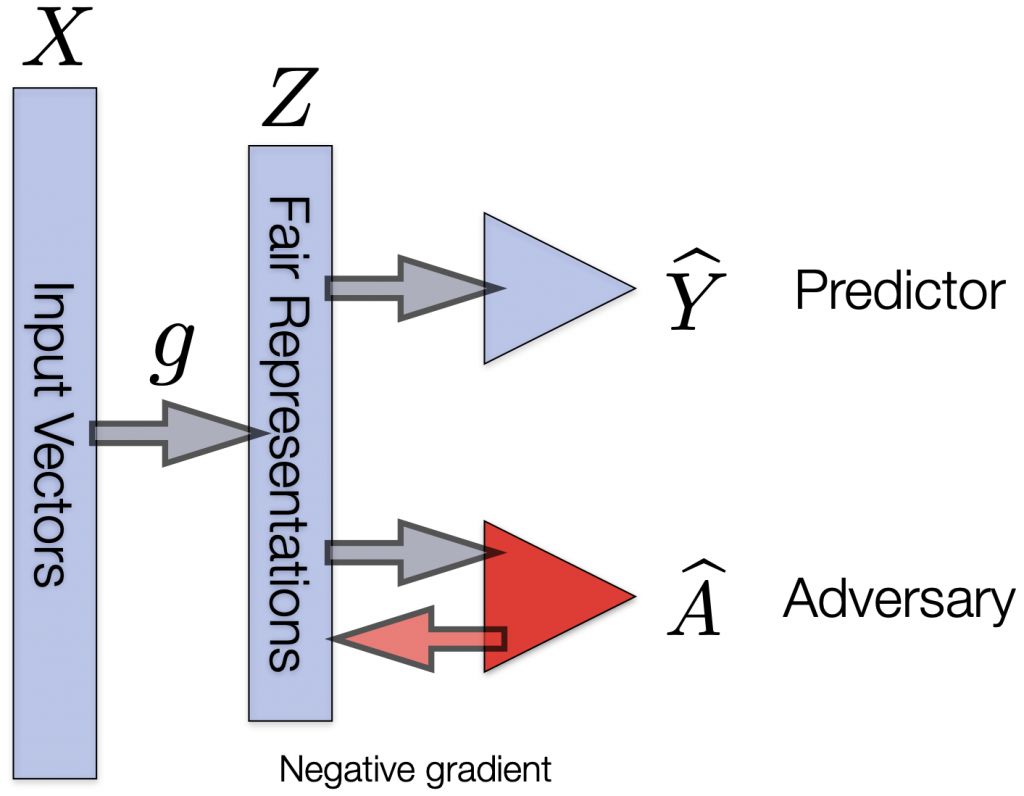 Figure 2. An algorithmic implementation of learning fair representations. The middle representations try to fool the adversary, whose goal is to distinguish whether the group attribute of the input variable is Circle (\(A = 0\)) or Square (\(A = 1\)). The overall network could be trained via gradient descent.
Figure 2. An algorithmic implementation of learning fair representations. The middle representations try to fool the adversary, whose goal is to distinguish whether the group attribute of the input variable is Circle (\(A = 0\)) or Square (\(A = 1\)). The overall network could be trained via gradient descent. Here the goal is very intuitive: if we manage to train a feature transformation \(Z\) that can confuse a very strong adversary (discriminator), then any predictor acting on this representation will also be fair (i.e., satisfy statistical parity) due to the celebrated data processing inequality, which roughly says that post-processing of data cannot increase information.
Tradeoff between Fairness and Utility
The model presented in Figure 2 contains two objectives and optimizes them simultaneously during training. The first objective is to ensure statistical parity by confusing the adversary, and the second objective is to reduce the loss function of the target task of predicting \(Y\). These two objectives are often combined into one, with a hyperparameter \(\lambda\) controlling the tradeoff. However, the notion of statistical parity does not involve the ground-truth label \(Y\) in its definition. As one can imagine, suppose the group attribute \(A\) is highly correlated with the target \(Y\); then asking a predictor to satisfy statistical parity will necessarily eliminate any perfect predictor as well.
For example, as in our case of loan granting shown in Figure 1, the repayment rate of the Circles (90%) is higher than that of the Squares (80%). According to statistical parity, any fair predictor has to grant loans to both the Circles and the Squares at the same rates. For instance, a fair classifier could grant loans to exactly all the Squares that will repay and 80% of all the Circles (Figure 1, left case). But this means that at least 10% of the Circles population get denied loans despite the fact that they will actually repay. Or, a fair classifier could grant loans to exactly all the Circles that will repay and to all the Squares that will repay plus half of the Squares that will default (Figure 1, right case). In both of these cases, the fair classifier has to incur some loss in terms of predictive accuracy in order to meet the criterion of statistical parity. Of course, there are many other possible fair predictors. Could any of them incur less loss?
In our recent paper @ NeurIPS’19, we show that actually both of the two fair classifiers above are optimal in terms of utility in a certain sense. Formally, let \(\text{Err}_{a}(\widehat{Y})\) be the 0-1 binary classification error incurred by \(\widehat{Y}\) on the group \(A = a \in\{0, 1\}\). Define $$\Delta_{\text{BR}} = |\Pr_{\mathcal{D}}(Y = 1\mid A = 0) – \Pr_{\mathcal{D}}(Y = 1\mid A = 1)|$$ to be the difference of the base rates across groups. The following theorem holds:
Theorem 1. For any predictor \(\widehat{Y}\) that satisfies statistical parity, $$\text{Err}_0(\widehat{Y}) + \text{Err}_1(\widehat{Y}) \geq \Delta_{\text{BR}}.$$
In our example of loan granting, the difference in repayment rates between the Circles and the Squares is 10%, so \(\Delta_{\text{BR}} = 0.1\). Note that both of the aforementioned fair classifiers have an error rate of 0.1, either on the Circles or on the Squares. In light of Theorem 1, for any fair classifier, the sum of its error rates on both groups has to be at least 10%, so both of them are optimal. Theorem 1 is quite intuitive; it essentially says:
When the base rates differ across groups, any fair classifier satisfying statistical parity has to incur an error (depending on the difference of base rates) on at least one of the groups.
Specifically, it is easy to see that any fair classifier has to incur an error rate of at least \(\Delta_{\text{BR}} / 2\) on at least one of the groups. Furthermore, this result is algorithm-independent, and it holds on the population level (i.e., large training sets will not help). Now let’s take a closer look at the quantity \(\Delta_{\text{BR}}\):
- If \(A\perp Y\), then \(\Pr(Y=1\mid A =0) = \Pr(Y=1\mid A =1)\), which implies that \(\Delta_{\text{BR}} = 0\); in other words, if the group attribute is independent of the target, then the above lower bound becomes 0 and there is no tradeoff.
- If \(A = Y\) or \(A = 1 – Y\) (almost surely), then \(\Delta_{\text{BR}}\) attains the maximum value of 1. In this case, any fair classifier has to incur an error of at least 0.5 on at least one of the groups.
In general, the quantity \(\Delta_{\text{BR}}\) takes values between 0 and 1, and it is this quantity that characterizes the tradeoff between fairness and utility in binary classification.
Tradeoff in Fair Representation Learning
Theorem 1 only holds in an “exact sense”: the predictor needs to satisfy statistical parity exactly. However, in practice, due to limited training data and/or model capacity, this might be hard to achieve. Is it possible for us to characterize the inherent tradeoff when a predictor only approximately meets the criterion of statistical parity? If yes, where and how will the representations play a role?
It turns out that this approximation helps reduce the lower bound in Theorem 1. In particular, let \(\mathcal{D}_a,~a\in\{0, 1\}\), be the conditional distribution of \(\mathcal{D}\) given \(A = a\). For a feature transformation \(g:\mathcal{X}\to\mathcal{Z}\), let \(g_\sharp\mathcal{D}_a\) be the pushforward distribution of \(\mathcal{D}_a\) under \(g\). Furthermore, if we use \(d_{\text{TV}}(\cdot,\cdot)\) to denote the total variation distance between two probability distributions, then the following theorem holds:
Theorem 2. Let \(g:\mathcal{X}\to\mathcal{Z}\) be a feature transformation. For any (randomized) hypothesis \(h:\mathcal{Z}\to\{0, 1\}\) such that \(\widehat{Y} = h(g(X))\) is a predictor, the following inequality holds: $$\text{Err}_0(\widehat{Y}) + \text{Err}_1(\widehat{Y}) \geq \Delta_{\text{BR}} – d_{\text{TV}}(g_\sharp\mathcal{D}_0, g_\sharp\mathcal{D}_1).$$
First of all, it is clear to see that when \(d_{\text{TV}}(g_\sharp\mathcal{D}_0, g_\sharp\mathcal{D}_1) = 0\), Theorem 2 reduces to the lower bound in Theorem 1; in this case, again by the data-processing inequality, any hypothesis \(h\) acting on \(Z\) will also generate the same outcome rates across groups and thus be fair. Second, the smaller the \(d_{\text{TV}}(g_\sharp\mathcal{D}_0, g_\sharp\mathcal{D}_1)\), the larger the lower bound.
It is worth pointing out that there is nothing special about the choice of total variation distance as a measure of the quality of distribution alignment. In Section 3.2 of our paper, we provide a general analysis using \(f\)-divergence, which can be instantiated to obtain lower bounds of the same flavor but using other divergence measures as well, e.g., the Jensen-Shannon distance, the Hellinger distance, etc. On the positive side, under certain conditions, we also show that learning fair representations helps achieve another notion of fairness, namely accuracy parity, which asks for equalized error rates across groups.
What’s in Practice
The lower bounds above imply that over-aligning the feature distributions across groups will inevitably lead to large joint errors. To verify this implication, we conduct experiments on a real-world dataset, the UCI Adult dataset. The task here is annual income prediction in 1994 (\(\geq 50\)K/year), and the group attribute corresponds to Male/Female. For the Adult dataset, \(\Delta_{\text{BR}} = 0.197\), i.e., roughly a 19.7% gap exists between Male and Female.
We implement the model in Figure 2 and vary the tradeoff hyperparameter \(\lambda\) for the adversarial loss between 0.1, 1.0, 5.0 and 50.0. Results are shown in Figure 3:
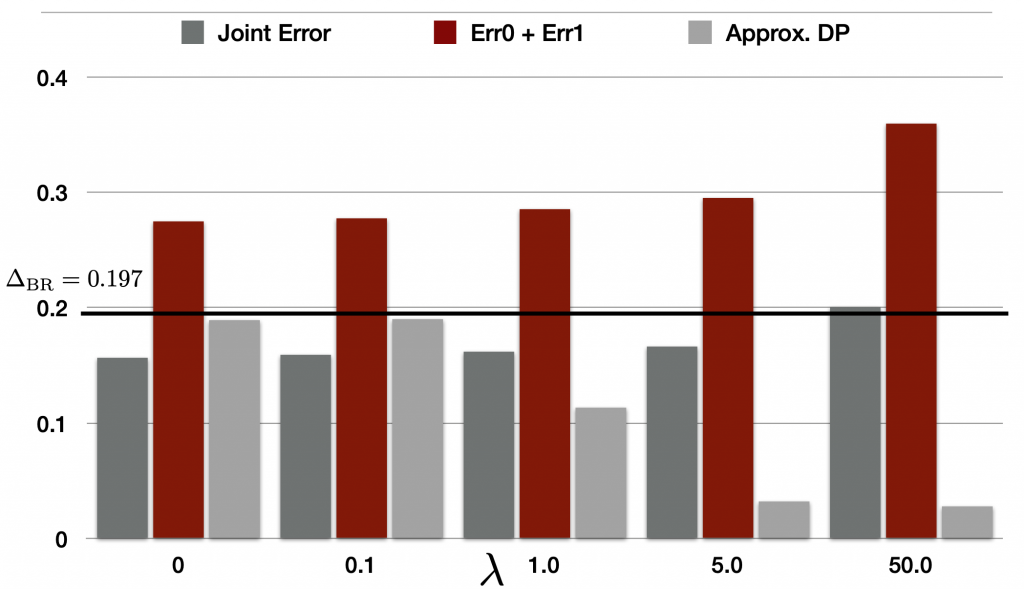 Figure 3. Tradeoff between statistical parity and the sum of error rates across groups with different tradeoff parameters \(\lambda\).
Figure 3. Tradeoff between statistical parity and the sum of error rates across groups with different tradeoff parameters \(\lambda\).
In Figure 3, we plot three metrics and their behavior with increasing \(\lambda\). The first bar corresponds to the joint error (i.e., \(\text{Err}_{\mathcal{D}}(\widehat{Y})\)), which is the overall error on the Adult dataset. The second, red bar represents the sum of errors across groups. This is exactly the one that appears in our lower bounds in both Theorem 1 and Theorem 2. The third, gray bar represents a gap score measuring how close \(\widehat{Y}\) is to satisfying statistical parity; more specifically, it is \(|\Pr(\widehat{Y} = 1\mid A = 0) – \Pr(\widehat{Y} = 1\mid A = 1)|\). Clearly, the smaller the gap score, the closer \(\widehat{Y}\) is to satisfying statistical parity.
As expected, by increasing the value of \(\lambda\), the gap score quickly decreases, and when \(\lambda = 50.0\), the corresponding predictor \(\widehat{Y}\) is already very close to satisfying statistical parity. On the other hand, we can also observe that by increasing the value of \(\lambda\), the red bar quickly increases, reaching a sum of error across groups more than 0.36 at the end. Note that here in Figure 3 the black horizontal line corresponds to \(\Delta_{\text{BR}} = 0.197\), and all the red bars extend above this horizontal line, which is consistent with our theoretical results. In practice, the quantity \(\Delta_{\text{BR}}\) is very easy to compute, and it can serve as a limit on the sum of errors that any fair classifier must incur prior to actually training these fair classifiers.
Concluding Thoughts
Understanding the fundamental tradeoff between utility and statistical parity is both interesting and challenging. In our recent paper and in this blog post, we provide a simple and intuitive characterization of this inherent tradeoff in the setting of binary classification: when the base rates differ across groups, any fair classifier in the sense of statistical parity has to incur an error on at least one of the groups! Finding an analogous characterization in the regression setting remains an open question. On the other hand, our results provide evidence that the definition of statistical parity as fairness is somewhat flawed, i.e., it is agnostic about the ground-truth label \(Y\). On the other hand, equalized odds and accuracy parity are two alternative criteria for group fairness, and both of them are compatible with perfect predictors. In our recent paper @ ICLR 2020, we provide an algorithm to approximately achieve both criteria simultaneously in the setting of binary classification, again through learning representations.
References
- The Ethical Algorithm, Michael Kearns and Aaron Roth.
- Learning Fair Representations, Zemel et al., ICML 2013.
- Inherent Tradeoffs in Learning Fair Representations, Zhao et al., NeurIPS 2019.
- Equality of Opportunity in Supervised Learning, Hardt et al., NeurIPS 2016.
- Conditional Learning of Fair Representations, Zhao et al., ICLR 2020.
- UCI Machine Learning Repository, https://archive.ics.uci.edu/ml/datasets/Adult.
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.