Figure 1. Modern ML practitioners witness phenomena that cast new insight on the bias-variance trade-off philosophy. The evidence that very complex neural networks also generalize well on test data motivates us to rethink overfitting. Research also emerges for developing new methods to avoid overfitting for Deep Learning.
Introduction
Overfitting, as a conventional and important topic of machine learning, has been well-studied with tons of solid fundamental theories and empirical evidence. However, as breakthroughs in deep learning (DL) are rapidly changing science and society in recent years, ML practitioners have observed many phenomena that seem to contradict or cannot be thoroughly explained by the “classical” overfitting theory. For example, the bias-variance tradeoff implies that a model should balance underfitting and overfitting, while in practice, very rich models trained to exactly fit the training data often obtain high accuracy on test data and do well when deployed. This contradiction has raised questions about the mathematical foundations of the classical theories and their relevance to practitioners. It seems that what we have learned about overfitting is just the tip of the iceberg, representing the classical ML paradigm where our models are not super complex and our goal is purely to make predictions on test data. The underwater part of this overfitting iceberg contains more mysteries that have not yet been fully understood, partly due to the “black-box” characteristics of deep neural networks.
The goals of this blog post are to: (i) raise questions that make people rethink the classical overfitting theory and guide people to explore a broader definition of overfitting, (ii) illustrate some recent discoveries that not only provide evidence for the ubiquity of unconventional overfitting phenomena for DL but also posit a mechanism for their emergence, and (iii) summarize some state-of-the-art strategies to deal with overfitting in the modern DL practice.
We first review some of the key insights of the classical theory in overfitting in the following section. We then devote a section to each of our three goals. In the final discussion and summary, we will see how our insights from classical ML theory could be modified to better suit the modern DL paradigm, and we will conclude by summarizing the main takeaways. Note that the aim of this blog is not to challenge the classical theory, but to point out that many situations might be more nuanced and subtle than we initially thought. Our exploration of overfitting in the DL regime is neither exhaustive nor rigidly proved by theory – indeed, many topics are still open questions. Rather, we hope this blog post to be eye-opening and to help make people rethink their previous beliefs about overfitting.
Classical Overfitting
Definition
In contrast to a classical description such as “the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably”, it is sometimes more useful to express it in terms of the empirical risk minimization (ERM) framework, where we define:
with an appropriate loss function l and hypothesis h.
Under the ERM framework, overfitting happens when the empirical (training) risk of our model is relatively small compared to the true (test) risk. In the equation, h refers to our prediction model, and l is some loss function.
Regardless of the form of the definition, the conventional definition of overfitting focuses solely on the model’s performance on an underlying “true” data distribution, which is usually estimated by measuring the model’s performance on a held-out test set.
Bias-Variance Tradeoff
The bias-variance tradeoff theory often comes together with overfitting, providing theoretical guidance on how to detect and prevent overfitting. The bias-variance tradeoff can be summarized in the classical U-shaped risk curve, shown in Figure 2, below. As stated in the original paper, the predictor hn is commonly chosen from some function class H such as logistic regression, using empirical risk minimization (ERM). By changing the model complexity, the capacity of the function class H also changes. It is possible to control the bias-variance tradeoff by selecting our models to balance underfitting and overfitting:
- If the set H is too small, all predictors in H may under-fit the training data (i.e., have large empirical risk) and hence perform poor predictions on test data. In this case we have low variance but high bias.
- If the set H is too large, the empirical risk minimizer may over-fit spurious patterns in the training data resulting in poor prediction performance on test data (small empirical risk but large true risk). In this case, we have low bias but high variance.
 Figure 2: The classical “U-shaped” curve arising from the bias-variance trade-off.
Figure 2: The classical “U-shaped” curve arising from the bias-variance trade-off.
Source: (Belkin et al., 2019)The conventional understanding is that we need to find the “sweet spot” between underfitting and overfitting. Our control over the function class capacity can be explicit or implicit (more details in the next section). When a suitable balance is achieved, the performance of the predictor h on the training data is said to generalize to the true data distribution.
Common Ways to Prevent of Overfitting
Various approaches have been proposed and applied in practice to avoid overfitting. They target different aspects of a machine learning task.
- Design of datasets. In general, the model generalizes better with more training data. In addition to gathering more data, data augmentation is also widely adopted.
- Use of a simpler model. As a larger function space is more prone to overfitting, a simpler model is usually preferred.
- Regularization in various forms. Explicit regularization includes adding a penalty term, dropout for Deep Neural Networks (DNN), weight decay, etc. Implicit regularizations include early stopping and batch normalization, etc.
- Ensembling. Ensembling includes bagging, stacking, and boosting, etc. It has been shown that an ensemble of many simple models can fit the data with both low bias and low variance and thus prevent overfitting.
- Validation. The main method of detecting overfitting in the first place is to leave part of the training data as a validation set (or a development set), and compare the model’s performance between the training and validation sets. It will also allow one to measure how effective their overfitting prevention strategies are.
In summary, classical overfitting theory offers the following insights:
- Bad performance on test data and good performance on training data indicates overfitting.
- The U-shaped bias-variance tradeoff curve shows that beyond the sweet-spot, generalization performance decreases as the model becomes more complex.
- Using a highly complex model without considering overfitting is risky, as we are forced to use explicit regularization to obtain good test performance.
- A typical strategy to train an ML model can be summarized as follows:
So far so good, right? The classical theory seems elegant and works well in many cases. However, we will see some new examples and weird phenomena that challenge our confidence for the classical theories. At the end of this blog post, we will gain another perspective of these insights and discuss whether or not they still hold.
Non-Conventional Examples of Overfitting
Case 1: Beyond the Classical Regime in a Toy Example
As machine learning practitioners, we should all be familiar with the “polynomial fitting” toy example that has been excessively used to show the bias-variance tradeoff. Plots 1-3 in Figure 3 more or less illustrate the same phenomenon: we are trying to fit 10 samples from a sin(·) function (plus Gaussian noise) using N basis functions, and when N = 10 we perfectly interpolate the data with a wiggly curve that fails to generalize at all. The corresponding excess risks are also marked in the bottom plot. This perfectly matches the classical U-shaped curve.
However, the story does not end here. If we continue to increase the number of terms used but also regularize the model by finding the min-norm solution, the fitted curve looks smooth again (plots 4 and 5 in Figure 3)! It seems that a complex model with over 500 basis terms still generalizes well.
Under the classical definitions, a model is almost definitely considered to be overfitted if it achieves zero training error (i.e. zero empirical risk). However, we intuitively wouldn’t think of the behavior of plot 5 as being overfitted, at least not to the same extent as plot 3, even though both achieve zero training error. There is an increasing understanding that neural networks that generalize well are more similar to plot 5 than to plot 2 in our example. We will see later that similar “double-descent” curves (a term introduced by Belkin et al. 2019) can be widely observed in other models as well.

Figure 3: A toy regression example of fitting 10 samples from a sin(·) function (plus Gaussian noise) using a function with N basis. This example shows that after the classical “overfitting” stage, the excess risk decreases as the model complexity increases.
Case 2: The Creative AI Game Agent who take Shortcuts
As part of the The OpenAI Retro Contest, AI has been taught to play the original Sonic the Hedgehog. The goal of Sonic is to defeat enemies and collect rings while beating each level as fast as possible, all of which increases the player’s score. The AI agent is trained using deep reinforcement learning to maximize its score, in the hope that it will learn to do well on all three aspects of the game.

Figure 4: A screenshot of the Sonic game. The player increases their score by collecting rings, defeating enemies and completing levels quickly.
Source: (Gach, 2018)
This particular definition of success led to a surprising result: the agent accidentally discovered a glitch in which it could pass through walls in the game’s water zones in order to finish more quickly, thus rapidly increasing its score. Despite not being what the researchers had intended, it was a creative solution to the problem laid out in front of the AI, which ended up discovering accidental shortcuts while trying to move right.
One might say that in a reinforcement learning scenario, especially one that uses a game as its environment, there is no such thing as “testing” data and it is hard to define “generalize well”. But clearly, if we tested this agent on an identical release of this Sonic game with the walk-through-walls glitch fixed, the agent will probably do poorly. The failure of the trained model is obvious given that the game interface offers easy visualization of the agent’s behaviors, why they maximize reward in the task, and why these behaviors represent an unintended and fragile solution to the task.
This type of failure likely applies more generally than game-playing AI, though it can be hard to demonstrate this with certainty on complex models whose behavior cannot be not easily visualized. We could imagine supervised learning tasks where the model exploits delicate properties of the training dataset to improve its loss. If the delicate properties are not just an artifact of random noise (i.e. if they represent unintended biases in the sampling process), the model may even perform well on i.i.d. validation data, but still fail in a nearly identical task that happens to lack the same subtleties in the data.
The same principle applies when we try to solve important real world tasks with reinforcement learning agents trained in physics simulators. Even if experts believe that the physics simulator is extremely representative of reality, the reinforcement learning agent may still find a difference and develop its behaviors around it. This is not the fault of the simulator; even if the model were trained in the real world, if the solution were fragile enough it might fail if a little dust falls on the agent’s sensors.
In a sense, these models depend on arbitrarily subtle properties of the training data distribution or environment, making them fail even in nearly identical test distributions or environments. Though that still technically makes this an example of “covariate shift” instead of “overfitting” according to the definitions of the terms, it is indicative of a very similar generalization issue likely originating from similar reasons as actual “overfitting”, so we believe it would be wrong to treat generalization errors of these kinds as being totally unrelated to overfitting.
Case 3: The Suicide Move of an AI Go Player Smarter than Human
After the power show of AlphaGo Zero, most of the Go AI developers shifted gears to reinforcement learning on self-play. The “Zero-series” AI Go players, while trained without any human expertise and supervision, can often over-perform the counterparts trained with human experiences and achieve higher ranks in competitions. Nowadays, the top Zero-series AI Go agents can achieve Go ratings close to 5000 while top expert system Go agents have ratings around 4200. With such high ratings, we would expect these top Zero-series AI agents to have perfect performance when given human games as input, since top human players only have ratings around 3650.

Figure 5: A highly rated Zero-series agent commits suicide in a scenario that human expert would never make.
Source: Moves generated from running these agents on Google cloud with specified constraints.
However, after years of training, even the self-play approach is starting to show some limitations. For example, as shown in Figure 5, it is observed that a Zero-series agent, LeelaZero, committed suicide in a simple survival puzzle despite the fact that its Go rating has surpassed top human players. In contrast, another agent Zen6, trained by human expertise data, makes a reasonable move. Ironically, the rating of LeelaZero is much higher than Zen6, which indicates that Leela has much better performance than Zen6 when playing a Go match from start to finish.
Such “unreasonable” moves are not rare for Go agents that have been trained with no human expert data. In fact, this is just another representation of overfitting in the DL era. Although the Zero-series agents can make impeccable predictions on their self-play datasets (the training data), their predictions are generally unreliable on human games (the testing data), which is just a simple survival puzzle in this case.
One might say it is unreasonable to expect an agent to do well on a task that is demonstrably different from the training setup, but in practice we obviously want our models to generalize as much as possible. We continue to develop Go AI so that we can use these agents for educational insights when teaching people how to win a game under a given board position, but if Zero-series agents cannot do this then they are not useful to us despite their high Go rating. An agent that uses simpler, more generalizable tactics to achieve a high Go rating will be more useful to us, and in this case we have found that we can reduce generalization error by giving an inductive bias to the model to prefer tactics used by human Go experts. Note that we have the exact same goal of introducing inductive bias when we reduce “normal” overfitting with methods such as data augmentation and initialization from a pre-trained model.
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
We hope that these examples help illustrate that overfitting is more nuanced than what the classical definitions suggest, at least in the era with DL excessively deployed. We think that instead of achieving low prediction error, the ultimate goal in statistics/machine learning is to use data to make useful inferences. The inferences can take on many forms, such as:
- Parameters to a model
- Predictions for test data
- Discoveries about the structure of the data
- Comparisons between architectures and methods
There are many criteria for inferences to be useful. Most relevant to this blog is that we want our results to be applicable in scenarios different from our original experimental setup. Depending on the use case, “generalizability to other scenarios” can mean very different things, and sometimes even a high performance score on i.i.d. test set data is not enough. Therefore, overfitting deserves a broader definition in the modern DL era.
Rethinking Overfitting
The Double Descent Curve
In contrast to the well-accepted “U-shaped” curve, practitioners who routinely use modern deep learning models have witnessed something different: despite the high model capacity and a near-perfect fit of the training data, these predictors often give fairly accurate predictions when evaluated on test data and when deployed for real world use cases.
Such phenomenon can be summarized in the curve shown in Figure 6. This “double descent” curve incorporates the U-shaped risk curve (with respect to the “classical” regime) together with the observed behavior from deploying higher capacity models (with respect to the “modern” interpolating regime), separated by the “interpolation threshold”. “Interpolation” here means the model is trained to exactly fit the data, so the models to the right of the interpolation threshold have zero training risk.

Figure 7: The double descent risk curve is observed with various models: (a) a fully connected neural network on MNIST and (b) random forests on MNIST. The dotted line in each plot indicates the interpolation threshold.
Source: (Belkin et al., 2019)
Besides neural networks, the double descent risk curve also manifests with other high-capacity models. Belkin et al. give empirical evidence that random forests also show similar generalization behavior as neural nets. In particular, when random forests are used with maximally large (interpolating) decision trees, the flexibility of the individual trees and the regularization imposed by ensembling yields interpolating predictors that are more robust to noise in the training data than the predictors produced by rigid, non-interpolating methods. Figure 7 (b) shows the double descent curves of random forests on MNIST, with similar patterns as the curves of a neural network in Figure 7 (a).
Why do these counter-intuitive phenomena beyond the interpolation threshold exist? A short answer would be “a larger function class gives us more candidate models, allowing us to choose the more ‘suitable’ ones.” (Belkin et al., 2019) gives a more precise description of this mechanism for the emergence of double descent curves, i.e., why increasing function class capacity improves the performance of classifiers. In essence, they argue:
- The capacity of the function class does not necessarily reflect how well the predictor matches the inductive bias appropriate for the problem at hand. Instead, it is usually reflected by the regularity or smoothness of a function. In other words, the simplest explanation compatible with the observations should be preferred.
- By considering larger function classes containing more candidate predictors compatible with the data, we are able to find interpolating functions that have smaller norm and are thus “simpler”.
Believe it or not, it has been known for a long time that highly complex model spaces can generalize well, and arguably the double descent curve is not such a new discovery after all. Back in 1995, Leo Breiman raised the question “Why don’t heavily parameterized neural networks overfit the data” in his paper. In addition, despite being empirically witnessed in many of the experiments mentioned in (Belkin et al., 2019), the double descent behavior has been historically overlooked. It is probably due to several cultural and practical reasons:
- Observing the double descent curve requires a parametric family of function spaces which can be made arbitrary complex. However, the models studied extensively in classical statistics usually assume a small, fixed set of input features and limited representation capacity.
- Richer families of function space are usually explored in the context of non-parametric statistics, with smoothing and regularization almost always deployed. These may prevent interpolation and compromise the representation capacity of the function class, and, hence, mask the interpolation peak.
- Due to the non-convexity of the optimization problem for general multilayer neural networks, solutions in the classical under-parametrized regime are highly sensitive to initialization. Therefore, the interpolation peak can only be observed within a narrow range of parameters, which sampling of the parameter space can easily miss.
- In practice, early stopping is excessively deployed in the training process of neural networks, which stops training as soon as the test risk fails to improve. The regularizing effect brought by early stopping makes it difficult to observe the interpolation peak.
Super-Flexible NNs and their Generalization Mystery
As another direct challenge to the traditionally-considered bias-variance trade-off, recent empirical evidence indicates that large neural networks trained to interpolate the training data obtain near-optimal test results, even when the training data are highly corrupted (Zhang et al., 2016).

Figure 8: Experiments show that NNs can fit different corrupted datasets with zero training errors, which shows their super flexibility just like cats can easily fit into any shape of containers.
Source: (Zhang et al., 2016)
The phenomenon of good generalization ability in an overparameterized model cannot be theoretically explained by traditional complexity measures such as Rademacher complexity and VC dimension. Rademacher complexity and VC dimension both consider the worst predictor that minimizes empirical risk within the function space (note the sup in their definitions). Such bounds are far too loose to be useful for the overparameterized model class, where there are many predictors that generalize poorly, and therefore the worst one is undoubtedly bad. However, the predictor found by typical gradient based algorithms turns out to generalize much better than the worst one in the function space.
Then, what is the real reason for generalization here? It might be related to what we have discussed in the previous section: the specific predictor found by a specific algorithm may match the inductive bias for the specific problem. We introduce the minimum norm intuition, that for many problems we actually deal with, the inductive bias would be some regularity or smoothness, or in other words, the underlying model should have small norm. Fortunately, the typical algorithms we use such as stochastic gradient descent (SGD) usually finds a small norm solution. In other words, SGD acts as an implicit regularization.
The terminology norm has different meanings in different scenarios. For example, in an overparameterized linear regression, SGD initialized at zero is guaranteed to converge to the minimum l2-norm interpolating solution; in a neural network with all but the final layer fixed, SGD also converges to a solution with small l2-norm; in a kernel regression, SGD converges to a solution with small Hilbert norm; in a random forest, SGD converges to a highly averaged solution, where averaging trees leads to higher degree of smoothness. Unfortunately, in more complicated cases like DNN, although we hold an intuition that SGD can converge to a smooth solution, we have no ideas about which norm exactly characterizes such smoothness. We may not just use the l2-norm: for example, in a MNIST experiment, with wavelet preprocessing the l2-norm of the weights increases a lot, yet the test error drops.
In addition, Zhang et al. have shown empirically that such perfect fitting ability is qualitatively unaffected by explicit regularization methods, such as weight decay, dropout, and data augmentation. Explicit regularization may improve generalization, while some other implicit regularizations including early stopping and batch normalization, to some extent, may also contribute to generalization, but these regularzations are neither necessary nor by themselves sufficient for such good generalization.
In conclusion, the generalization of DNN is not a result of a single factor. It cannot be explained by complexity theory or explicit regularization. Implicit regularization and the related inductive bias may be involved, but no definitive answers nor formal theories exist for now.
Avoiding Overfitting for DNNs
Since DNNs have been widely applied, there has been much research on how to avoid overfitting for DNN. Some obvious approaches include: (1) explicit regularization, such as weight decay and dropout, (2) ensembling, (3) choosing an architecture that is known to do well on similar tasks. Information about the above methods is broadly available online. In this section, we discuss two common practices representing less obvious approaches for regularization: (1) using early stopping for deep learning (inferred from kernel methods) and (2) adjusting initialization and learning rate schedule.
Early Stopping for Kernel Methods
Wei et al. have theoretically and empirically showed that early stopping can improve the generalization ability of kernel methods. Let us consider a kernel regression problem, where we minimize the following empirical fitting error:
Here we minimize over all functions within a reproducing kernel Hilbert space (RKHS). For example, we use the Gaussian kernel space to represent polynomials, Sobolev space to represent Lipschitz smooth functions, etc.
Since a RKHS has infinite dimensions, there are infinitely many interpolating solutions. One can think about the Sobolev space case, where there are infinitely many ways to fit n data points with a Lipschitz smooth function. To avoid the potential overfitting, the traditional way is adding regularization, namely, to minimize the fitting error as well as limit the model complexity.
Instead of using the explicit regularization, we can also avoid overfitting by using an implicit regularization, i.e., early stopping. Wei et al. proposed an iterative kernel boosting method to directly minimize the empirical fitting error. The kernel boosting iterates can be viewed as analogous to gradient descent iterates.
If we are running kernel boosting iterates all the way through, it will eventually overfit the data. The three plots below show the performance of kernel boosting with a Laplacian kernel after 1, 6, and 100 rounds, respectively. We find that the performance at round 6 is the best, where the function fits the data smoothly. At round 100, the function exhibits a severe overfitting.
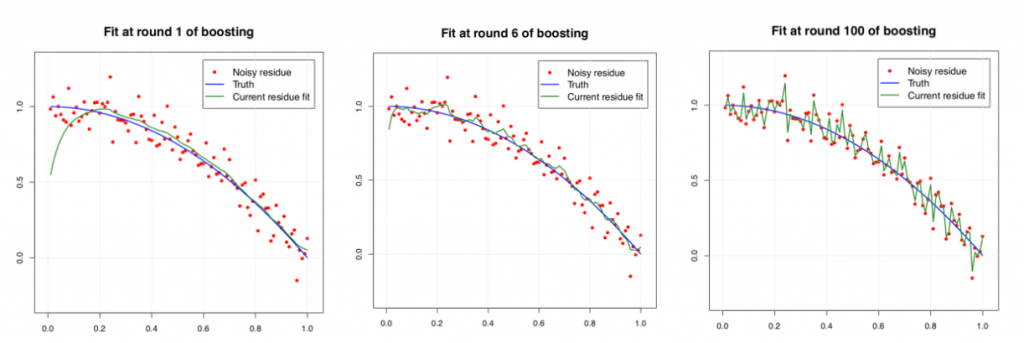
Figure 9. The performance of kernel boosting with a Laplacian kernel at different rounds.
Source: (Wei et al., 2017)
The mean-squared error v.s. iterations of the above experiment is shown in the left plot of Figure 10. The route of kernel boosting iterates is intuitively described as the right plot: after a certain number of updates, the function f is closest to the underlying ground truth f*, but continuing the updates will push the function away from the ground truth.
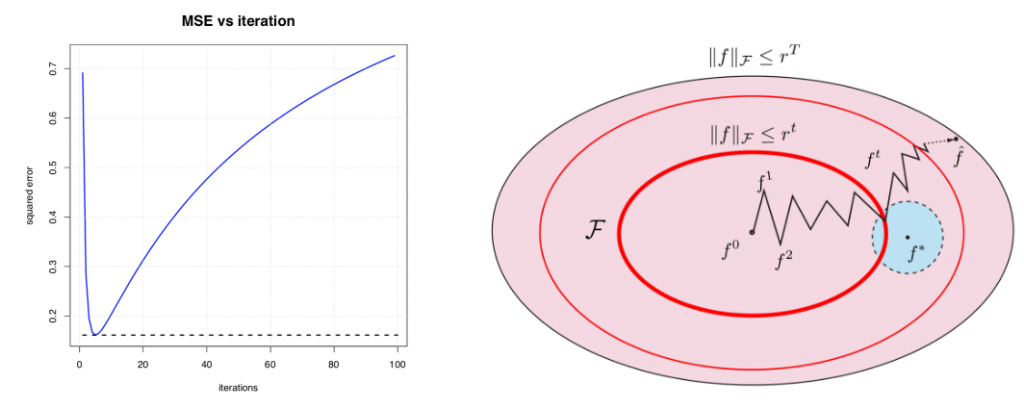
Figure 10. Left: mean-squared error (MSE) versus iterations. Right: route of kernel boosting iterates
Source: (Wei et al., 2017)
In this framework, Wei et al. found the theoretically optimal early stopping criteria for the kernel boosting. As shown in the theorem below, the optimal stopping criteria, as well as the resulting excess loss, depends on a statistical error term δn, which is the localized Gaussian complexity of the kernel class. The detailed values of δn for some typical kernels are listed in the original paper.
Wei et al. also proved that the excess risk of their algorithm achieves the minimax optimal bound, meaning that it is impossible to find a method that has better worst-case performance. Numerical results have shown that by early stopping at the “golden” time given by the theorem, the mean square error can achieve nearly as the oracle, which has access to the underlying distribution and can stop training exactly when excess risk is minimized. By virtue of being optimal, these early stopping bounds also apply in cases where interpolation is not necessarily bad (e.g. the models produced at the early stopping criterion may be close to interpolating the training data).
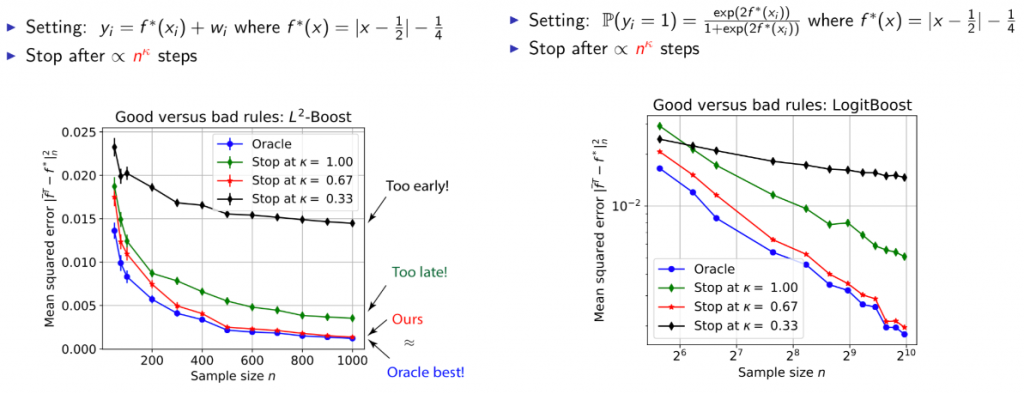
Figure 12. The mean-squared errors for the stopped at the “golden” time achieves the best result.
Source: (Li et al., 2018)
The algorithm is usable on its own, moreover, the results also help us understand the training of DNN. To study an overparameterized DNN, an interesting approach is looking at the infinite limit, namely, a neural network with infinite-width. At first glance this approach may seem hopeless for both practitioners and theorists: all the computing power in the world is insufficient to train an infinite network, and theorists already have their hands full trying to figure out finite ones. But in math/physics, there is a tradition of deriving insights into questions by studying them in the infinite limit, and indeed here too, the infinite limit becomes easier for theory. It turns out that: a properly randomly initialized sufficiently wide deep neural network trained by gradient descent with infinitesimal step size (a.k.a. gradient flow) is equivalent to a kernel regression predictor with a deterministic kernel called neural tangent kernel (Du et al., 2019).
In other words, in the infinite-width limit, a neural network tends to behave the same as a kernel regression. It is suggested that the gradient descent iterates in a neural network are similar to the kernel boosting iterates in a kernel regression. Thus, DNN training should also benefit from early stopping, although it is still hard to calculate the best stopping criteria for deep neural networks.
This means if it is important to have a theoretical guarantee of generalization performance, you can cut out the middleman and directly use this kernel boosting method. But if you’re willing to perform significant hyperparameter tuning, you can approximate these theoretically optimal results with a neural network. This is a fairly general phenomenon in ML, where in many cases you can choose between a well-understood but relatively inflexible classic algorithm, or a DNN which is more flexible but requires significant tuning to obtain approximate optimality results.
Initialization and Learning Rate
It’s hard to find definitive theories on neural network training because many surprising aspects play a role when training deep neural networks. Note that it is usually hard to train a neural network because of three properties of DNN training:
- Slow: The training process is usually very time consuming, taking a lot of GPU hours. It is impractical to select multiple random starting points and repeat the training process from scratch multiple times.
- High dimensional: Each training process can only visit a tiny fraction of the parameter space.
- Non-convex: There are many local optima, and it is hard to explore more than a small handful of them.
Because of these three properties, we can’t even get close to visiting all the local optima, and must settle with an arbitrary one found by gradient descent. The choice of training algorithm of DNN not only affects the time to convergence, but also affects the quality of the optima used for our inferences. In this section, we discuss two main choices of training algorithm: initialization and learning rate.
Unlike strictly convex problems such as linear regression, which have a unique solution, the selection of initialization point gives inductive bias to the training of DNN. Specifically, it has been observed that SGD is biased to converge to local optima that is “close” to the initial point. The authors in (Liu et al., 2019) have shown that it is possible to force SGD to converge to a “bad” local optima only by choosing a “bad” initial point. This form of inductive bias is even more obvious for large DNNs, which has been observed empirically in (Li et al., 2018). The first observation is that the more steps the SGD takes, the farther the parameters get from the initial point. Another observation is that overparameterized networks are more strongly biased toward the initial point.
Here comes the question: what kind of initialization will work then? It has been suggested in (Li et al., 2018) that random initialization is likely crucial to the training process and the consequent generalization for several reasons. First, random initialization prefers equal numbers of negative and positive weights. It also discourages extremely large or small outputs at each layer, and thus affects the shape of weight distribution. All these effects may contribute to producing smooth networks that generalize well.
In addition to the initialization scheme, learning rate is another thing that we can play with. It is a common practice to train a neural network with decaying learning rates, such as multiplying the learning rate by 0.1 every 100 epochs. Here is a typical plot of training curves for an image classification task, where the learning rate decreased by a factor of 10 every 30 epochs:
By looking at the training curve, we can notice that both the neural nets in this experiment seem to have waited unnecessarily long before decaying the learning rate. However, there are good reasons to stay at a high learning rate for a long time before decaying the learning rate. It seems that SGD favors more “stable” local optima when the learning rates are high. The reason for this phenomenon still remains unknown, though it has been observed empirically that such “stable” local optima usually generalize better than other optima (Chaudhari et al., 2016).
Based on this observation, our goal is thus to tune the learning rate so the model is forced to converge only to these “stable” optima. The first option is to spend more iterations at a high learning rate. This is a reasonable approach as long as you are aware that it might take a long time to see improvements in the training curve. You also must make sure that high learning rates do not introduce instability in training.
Another option, is to use cyclical learning rates. Instead of monotonically decreasing the learning rate, the authors propose to periodically set learning rate high to shake things up. The following plot is often used to visualize the effect of cyclic learning rate:

Figure 14. Left: SGD with a typical learning rate schedule. Right: SGD with several learning rate annealing cycles.
Source: (Huang et al., 2017)
The figure suggests three phenomena. First, the claim is that the brief periods of high learning rates introduced by cyclical learning rates allow fast convergence to a local optimum at the end of each cycle. Second, by having multiple cycles the authors believe that the model will reach multiple local optima, which can be used to create an ensemble model. Thirdly, the belief is that these optima achieve lower training losses with each cycle. Though at the end of the day these phenomena are only hypothesized behaviors, (Huang et al., 2017) does demonstrate that cyclical learning rates reach lower losses quickly and that making an ensemble out of the model parameters from the end of each cycle improves generalization performance.
To sum up, initial points and learning rate are two essential factors that can affect the final outcome of your neural network. In practice, if you know a smarter way to initialize your net, such as using pre-trained weights, you should definitely try it. Otherwise, random initialization can also give good results if they can ensure the outputs of the network are not too extreme. The default in many frameworks is to initialize each weight with a standard normal distribution, which often does not result in good initialization as the outputs of the network can become quite extreme; it is usually better to use smarter distributions such as Xavier initialization (Xavier et al., 2017). In addition, spending more time at high learning rate or using cyclical learning rate may help the training algorithm find a more stable local optimum, which can significantly improve generalization performance.
Discussion
Traditionally, we were taught in classes that “overfitting” happens when the model is too complex and achieves much worse accuracy on the test set than on the training set. Such an understanding has motivated whole families of regularization methods to limit model complexity. We generally did not want to see zero training error, which was equivalent to overfitting in our eyes.
In the age of deep learning, we found the need to rethink the definition of overfitting. It has been widely observed that heavily parameterized neural networks generalize well on the test set, as well as achieving zero training loss. A double-descent curve unifies the previous and modern regimes of overfitting and shows the ability of complex models to generalize well when the model is “complex” enough. However, it’s important to understand that deep neural networks seem to generalize well not directly because they have many parameters, but because having many parameters allow stronger regularization. By saying “regularization”, we do not only mean the explicit regularization methods such as dropout or weight decay. Implicit regularization such as SGD and early stopping can be just as important. Although not fully understood, the ability of SGD to find a small norm solution may be a key factor.
However, that does not mean the classical overfitting theory is wrong, or that it was not useful to get where we are. Instead, it means that the situation is nuanced and subtle than we thought. For example, perhaps the reason for the double descent curve is that the x-axis should not be the number of parameters or the complexity of the hypothesis space, but the size or complexity of the learned model instead. This reminds us that we have not understood all these issues yet and we don’t even know what is the right notion of complexity. Here, we try to modify the insights we took from classical theory to better characterize what happens in practice:
- Bad performance on test data and good performance on training data indicates overfitting. → Overfitting can be represented in many other forms. It depends on what you need to use your inferences for.
- The U-shaped bias-variance tradeoff curve shows that beyond the sweet-spot, generalization performance decreases as the model becomes more complex. → Beyond the interpolation point, we can observe another descent of testing error under proper experimental conditions, and a very complex model does not necessarily lead to overfitting.
- Using a highly complex model is risky, as we are forced to use explicit regularization to obtain good test performance. → For DNNs, explicit regularization seems to be more of a tuning parameter that helps improve generalization, but its absence does not necessarily imply poor generalization error. Moreover, the SGD commonly deployed by DNN has the effect of implicit regularization, which may be just as important.
- With huge NNs, we are almost guaranteed to achieve zero training error, so our NN training strategy is better described as:

For more modern tasks such as reinforcement learning for artificial game players, overfitting can manifest in other ways. Cases like Go AI suggest that even if the AIs can beat human players without any human expertise, they do not really “learn” some insights about the game. Other examples in video game AI field show similar behaviors, earning points by performing actions that do not make sense. Though these generalization errors cannot be detected by evaluating on i.i.d. test data, they still exist and can be reduced by introducing inductive biases into the model, e.g. with regularization, data augmentation and smart initialization. The Go AI case study also shows how it helps to integrate human expert data to bias the models toward human-like behaviors. In other words, careful design of data sets is another useful method for avoiding overfitting in these cases.
Summary
Overfitting is a topic that has attracted much research and industrial effort, since it is directly related to the future performance of any model. In this blog post, we mainly focus on the new behaviors and challenges of overfitting in the era of DL. In such a regime, the pattern of a double-descent curve phenomenon which appears to describe reality more accurately and differ from our traditional understanding of overfitting and model complexity. The theory behind such behavior is still an open question, but it is suggested the minimum norm solution achieved by using SGD is an important factor. We also discussed some possible techniques to avoid overfitting, including early stopping, proper initialization and adjusting learning rates. Some new machine learning tasks, such as reinforcement learning, have also posed new challenges on lack of generalization, which require further research. In conclusion, there is no single factor that decides the model’s ability to generalize well. The model architecture, explicit and implicit regularization, and dataset design all play a role.