Figure 1: Summary diagram highlighting the different steps in a data analysis project and the questions one should ask at each step in order to overcome the barriers to various types of reproducibility.
Introduction
Reproducing a study is a common practice for most researchers as this can help confirm research findings, get inspiration from others’ work, and avoid reinventing the wheel. According to the U.S. National Science Foundation (NSF) subcommittee on replicability in science, “reproducibility refers to the ability of a researcher to duplicate the results of a prior study using the same materials as were used by the original investigator”. That is, a second researcher might use the same raw data to build the same analysis files and implement the same statistical analysis in an attempt to obtain the same results.
Reproducibility is important not just because it ensures that the results are correct, but also because it ensures transparency and gives us confidence in understanding exactly what was done. In general, reproducibility reduces the risk of errors, thereby increasing the reliability of an experiment. It is now widely agreed that reproducibility is a key part of any scientific process and that it should be considered a regular practice to make our research reproducible. Despite this widely accepted notion, many fields including machine learning are experiencing a reproducibility crisis.
Figure 1 shows the steps involved in a data analysis project and the questions a researcher should ask to help ensure various kinds of reproducibility. In this blog post, we will introduce the different types of reproducibility and delve into the reasons for the formulation of these questions at each step. We first introduce the reproducibility crisis in science and motivate the need for asking these questions. Next, we discuss the different types of reproducibility, and for each one, we discuss its importance, barriers to enforcement, and suggestions to help achieve it. we lastly talk about why reproducibility is objectively hard in science using a mathematical argument and give a few real-life examples that showcase the adverse effects of some bad research practices.
Reproducibility Crisis in Science and ML
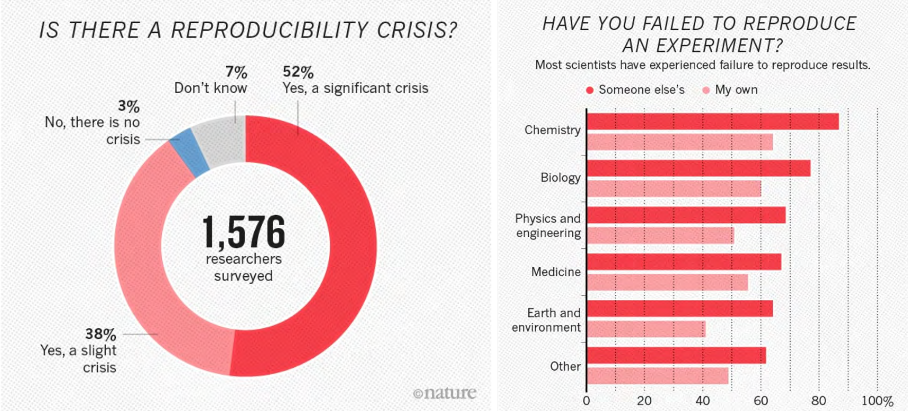 Figure 2: Key results of the survey on reproducibility conducted by Nature in 2016 [16].
Figure 2: Key results of the survey on reproducibility conducted by Nature in 2016 [16].Reproducibility is a minimum requirement for a finding to be believable and informative, yet more than 70% of researchers have reported failure to reproduce another scientist’s experiments [16]. Over the past decade, this problem has plagued many scientific fields. The situation is more severe in some fields such as chemistry and biology since it can take years to fully replicate a study, making it incredibly hard to check for reproducibility. According to a 2016 survey on reproducibility conducted by Nature (results in Figure 2), among the 1,576 researchers from various fields who responded to it, over half thought that there is a significant reproducibility crisis in science and some failed to even reproduce their own research [16].
The situation is not any better in machine learning. “I think people outside the field might assume that because we have code, reproducibility is kind of guaranteed,” says Nicolas Rougier, a computational neuroscientist at France’s National Institute for Research in Computer Science and Automation in Bordeaux [17]. In fact, ML researchers have found it difficult to reproduce many key results and it is leading to a new conscientiousness about research methods and publication protocols. A very common problem is that the source code used in a study is not open-sourced. At AAAI, Odd Erik Gundersen, a computer scientist at the Norwegian University of Science and Technology, reported the results of a survey of 400 algorithms presented in papers at two top AI conferences in the past few years. It was found that only 6% of the presenters shared their code. Only a third shared the data they tested their algorithms on, and just half shared pseudocode [17]. This has led the top ML conferences to strongly encourage the submission of code for accepted papers in the last year.
Types of Reproducibility
According to Goodman et al. [10], there are three types of reproducibility: methods, results, and inferential reproducibility. In the following sections, we describe these types in detail, provide a mathematical justification as to why reproducibility is hard, and give some suggestions for avoiding barriers to reproducibility.
Methods Reproducibility
Definition
Methods reproducibility is defined as the ability to implement, as exactly as possible, the experimental and computational procedures, with the same data and tools, to obtain the same results as in an original work [10]. Methods reproducibility involves providing enough detail about the procedures and data in the study so the same procedures could, in theory or in actuality, be exactly repeated.
Why is it important?
There are at least a few reasons which easily come to mind.
- Using baselines to prove a new technique is better – We need to obtain the same accuracy for the baseline as the original research if we want to prove that our approach is an improvement.
- Proof of correctness – If no one obtains the same results as us, it is likely that we are doing something wrong.
- Without methods reproducibility, scientists risk claiming gains from changing one parameter while the real source of improvement may be some hidden source of randomness.
- It is concerning to rely on models in production systems if we do not have ways of rebuilding them since requirements as well as platforms keep changing.
Barriers to methods reproducibility
Pete Warden [8] describes the typical life cycle of a machine learning model in image classification as follows:
- The researcher uses a local copy of one of the ImageNet datasets.
- She tries many different ideas, fixing bugs, tweaking the code, and changing hyperparameters on her local machine. After she is satisfied with her code, she might do a mass file transfer to her GPU cluster to kick off a full training run.
- While the program is in progress, she might change the code locally – since training can take a lot of time to complete.
- She keeps all the weights and evaluation scores from all runs, and decides which weights to release as the final model. These weights could be from any of the runs, and moreover, the code that produced the final score may not have come from the code she currently has on her development machine.
- She publishes her results, with code and weights of the model.
Warden describes this as a rather optimistic scenario, and emphasizes how hard it is for someone to step in, and reproduce each of the steps exactly. Each step is an opportunity for inconsistencies to creep in. Machine learning frameworks trade off numeric determinism to performance, and these frameworks keep updating, making accomplishing methods reproducibility more difficult.
What we want is for a researcher to be able to easily play around with new ideas, without having to pay a large “process tax” in terms of getting an existing code (e.g. baseline) to work as advertised. We want that a researcher be able to step in for a colleague, train all the models exactly, and get the exact results. This is especially difficult in machine learning and deep learning since many times we do not know why, how or to what extent our model works. Moreover, there are also multiple causes of non-determinism:
- Random initialization of layer weights: Most of the times, the layer weights are initialized by sampling randomly from a distribution.
- Shuffling of datasets: Often, the dataset is randomly shuffled at initialization, so our contents of training, test and validation sets may differ across runs. Alternatively, if the sets are fixed, the shuffling within the training set affects the order in which samples are iterated over, thereby affecting how the model learns.
- Changes in machine learning frameworks: This may lead to different behaviours across versions and more discrepancies across frameworks. For instance, Tensorflow warns its users to “rely on approximate accuracy, not on the specific bits computed”.
- Noisy hidden layers: Many architectures for neural networks include layers with inherent randomness. An example of this is the dropout layer which drops neurons with probability p, leading to a different architecture every time.
- Non-deterministic GPU floating-point calculations: Many functions, including some convolutional operations, in cuDNN do not guarantee reproducibility across runs.
In general, the process of documenting everything is extremely manual and time-consuming. In addition, there are no universal best practices on how to archive a training process so it can be successfully rerun in the future.
What can we do?
At the minimum, to reproduce results, the code, data, and overall platform need to be recorded accurately. We can follow a checklist developed by Joelle Pineau and her group which we will talk more about in a later section.
Results Reproducibility
Definition
Results reproducibility is defined as the ability to produce corroborating results in a new (independent) study having followed the same experimental procedures [10]. Again, this type of scrutiny helps debunk false claims.
Barriers to results reproducibility
Joelle Pineau, a professor at McGill University, and her group have studied reproducibility in reinforcement learning. Pineau’s group focused on a particular class of reinforcement learning algorithms called policy gradient methods. The four most commonly used baselines for policy gradient algorithms are TRPO, PPO, DDPG, and ACKTR. The group then compared the performance of these algorithms on Mujoco simulator for various environments. As shown in Figure 3, they observed different performances for each of these algorithms across different environments. This is not too surprising, even if the dynamics, the physics simulator and the computer used are the same since the algorithms are employed on different domains or environments.
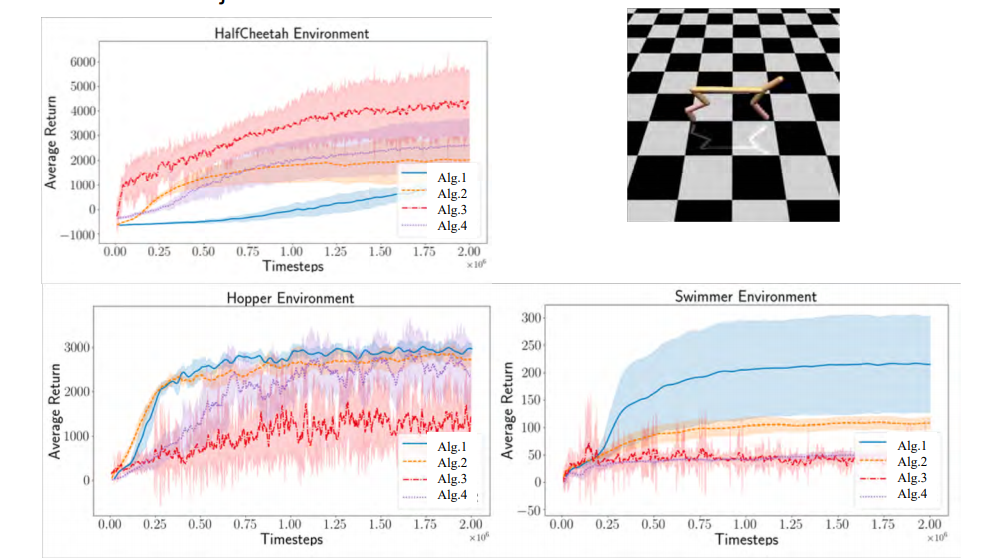 Figure 3: Comparison of performances of the four baseline algorithms on three different environments: HalfCheetah, Hopper, and Swimmer. For the purpose of reproducibility, it is not necessary to know which baseline algorithm each curve or color corresponds to. On HalfCheetah, the red algorithm performs the best, while on Hopper red seems to perform the worst; blue performing the best. Blue also has really low variance on Hopper environment, whereas even though blue also performs the best on Swimmer, it’s variance is much larger [20].
Figure 3: Comparison of performances of the four baseline algorithms on three different environments: HalfCheetah, Hopper, and Swimmer. For the purpose of reproducibility, it is not necessary to know which baseline algorithm each curve or color corresponds to. On HalfCheetah, the red algorithm performs the best, while on Hopper red seems to perform the worst; blue performing the best. Blue also has really low variance on Hopper environment, whereas even though blue also performs the best on Swimmer, it’s variance is much larger [20].Next, they tried to pull up a few open source implementations of the same algorithm, and compared their performances on the same environment, in their default settings. As shown in Figure 4, again, differences in performance were observed.
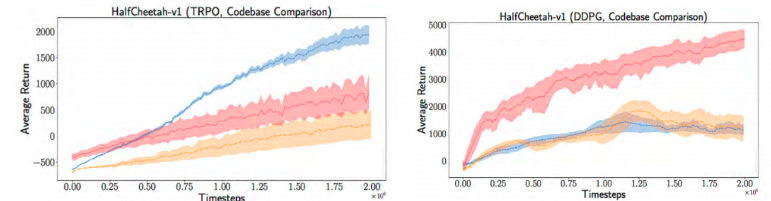 Figure 4: Comparison of different implementations of the same algorithm on HalfCheetah environment. Left plot shows the performance of TRPO, and the right one shows the performance of DDPG. Same algorithm on the same environment has inconsistent performance when implementations differ [20].
Figure 4: Comparison of different implementations of the same algorithm on HalfCheetah environment. Left plot shows the performance of TRPO, and the right one shows the performance of DDPG. Same algorithm on the same environment has inconsistent performance when implementations differ [20].They also experimented with the hyperparameters of the algorithms, and found that the algorithms were highly sensitive to their hyperparameters, and yielded very different results with varied hyperparameters. Figure 5 shows this trend.
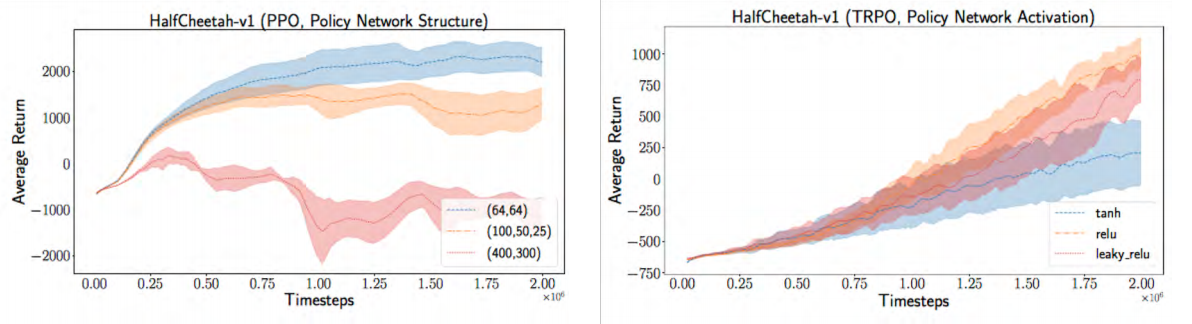 Figure 5: Comparison of the same algorithm on HalfCheetah on changing the hyperparameters. Left plot shows the performance of PPO on varying policy network architecture. Right plot shows the performance of TRPO on varying the activations used. Same algorithm on the same environment is inconsistent when their hyperparameters differ [20].
Figure 5: Comparison of the same algorithm on HalfCheetah on changing the hyperparameters. Left plot shows the performance of PPO on varying policy network architecture. Right plot shows the performance of TRPO on varying the activations used. Same algorithm on the same environment is inconsistent when their hyperparameters differ [20].They also found that the algorithms were very sensitive even to the random seeds, as seen in Figure 6. Changing the random seeds can lead to huge differences in obtained average returns. They looked at the literature to see if the value of n (the number of runs over which the performance is averaged) they were using was too small thus leading to such large differences in performance. However, they found that 5 was in fact towards the higher end of values that were usually used for n.
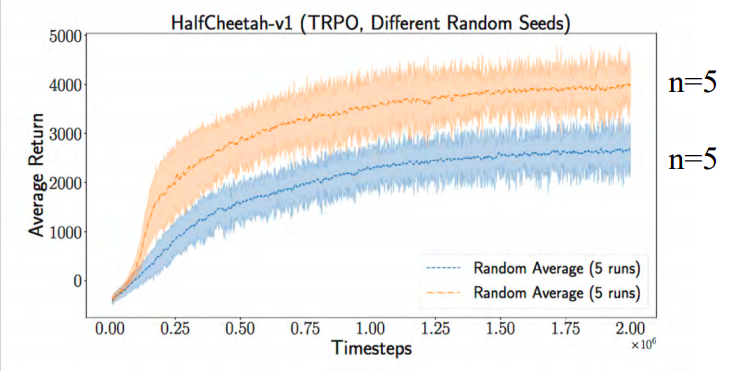 Figure 6: Comparison of the same algorithm TRPO with the same best hyperparameter setting. The two curves are averages across 5 different random seeds [20].
Figure 6: Comparison of the same algorithm TRPO with the same best hyperparameter setting. The two curves are averages across 5 different random seeds [20].
What conclusions can be drawn from the study? Only having fair comparisons with the same amount of data and compute is not sufficient. We need to have robust conclusions. We need to realise that often times, which algorithm performs the best depends on the amount of data and compute budget. We need to realise that in machine learning, the performance of algorithms depends on the hyperparameters, and these algorithms often exhibit high sensitivity to the setting of hyperparameters.
How do we overcome these barriers?
Pineau and her group developed a reproducibility checklist [9] enlisting points that help towards methods as well as results reproducibility. Following are the main points from her checklist:
- We need to have a clear description of the algorithm along with the complexity analysis (space, time, sample size). Sample size becomes important in case of an independent replication study.
- We need to include links to downloadable source code and dataset along with the dependencies.
- We need to provide a clear description about the data collection process, and how samples were allocated for training, testing, and validation.
- We need to specify the range of the hyperparameters considered and the method employed to select the best hyperparameters. Finally, we need to have a specification of the hyperparameters.
- We need to include a clear definition of statistics used to report the results, description of results including central tendency, variance, error bars as well as number of evaluation runs.
- We also need to include the computing infrastructure used.
The checklist can help verify several components of a study we are reproducing, placing particular emphasis on empirical methods. In fact, this checklist was adopted as a mandatory requirement for papers submitted to NeurIPS 2019.
Inferential Reproducibility
Definition
A study is deemed to have inferential reproducibility when an independent replication of the study or a reanalysis of it arrive at qualitatively similar conclusions to that of the original study [10].
Why is it important?
Inferential reproducibility is quite important to both scientific audiences and the general public. This is because most readers of a paper form an opinion of it based on the conclusions of the authors. These conclusions are usually listed in the abstract, introduction and discussion sections. Hence, it is imperative for these sections to be dispassionate, pertinent and demonstrably reproducible. Biased inferences have the potential to create inaccurate scientific narratives that can persist in research.
Barriers to inferential reproducibility and some examples
The two main barriers to inferential reproducibility are research bias and the failure to correct for multiple hypothesis testing [10].
Bias may lead to overinterpretation or misinterpretation of the results to suit the researcher’s hypothesis. For example, a researcher with a bias to show that his/her hypothesis is correct may try to reject the null hypothesis by manipulating the data and justify it in the name of outlier removal. We will be discussing different bias patterns and their underlying causes in a later section. We will also show how bias often leads to an increase in the number of false findings [1].
A familiar scenario is when a researcher tries out many different hypotheses and finally finds and reports a small subset of these hypotheses which are statistically significant. It is quite easy to forget to adjust the significance of the reported results to account for the multitude of hypotheses that have been tested. This might lead to significant yet false findings arising from pure chance. Conclusions which are based on these false findings cannot be trusted and thus act as major barriers to inferential reproducibility.
Bennett et al. [13] demonstrated this using a functional magnetic resonance imaging (fMRI) experiment. fMRI measures the activity of a brain region by detecting the amount of blood flowing through it – a region which was active during a cognitive task is likely to have increased blood flow. fMRI breaks the brain up into thousands of minuscule cubes called voxels and records the activity for each voxel. A subject was put inside a scanner and asked to determine what emotion an individual in a photo appears to be experiencing to help us better understand the brain during perspective-taking. Then, voxelwise statistics were computed using a general linear model (GLM). A t-contrast was used to test for regions with significant signal change during the photo condition compared to rest but no corrections were performed.
Figure 7 shows the significant regions. It is quite clear from the results that the aforementioned subject was not human – it was a dead Atlantic Salmon! This vivid experiment illustrates how it is possible to obtain significant yet false findings when we test many hypotheses but do not correct for it. When the authors performed the correction by either controlling the false discovery rate (FDR) or by controlling the overall familywise error rate (FWER) through the use of Gaussian random field theory, all of the previously significant regions were no longer significant.
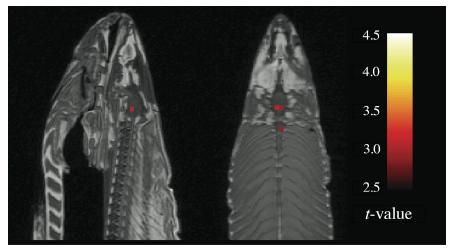 Figure 7: Significant voxels identified by Bennett et al. [13] are shown in red. Uncorrected p < 0.001 for each significant voxel.
Figure 7: Significant voxels identified by Bennett et al. [13] are shown in red. Uncorrected p < 0.001 for each significant voxel.Some other bad practices which hinder inferential reproducibility include hypothesizing after the results are known, selective outcome reporting, selective presentation of previous literature and limited discussion about the shortcomings of a method. In ML-based studies, presenting weak baselines while proposing a novel model can mislead readers into believing that the proposed model works well when in actuality, it does not. The interpretation of the results obtained using clustering techniques can also be highly subjective and different people can perceive them in different ways.
How do we overcome the aforementioned barriers?
Now that we understand the importance of and the barriers to inferential reproducibility, let us look at some suggestions to help us overcome these barriers. Firstly, it is quite important for any paper to have an extensive literature review that presents a wholesome picture of the previous work in the area. This means that it needs to include reviews of articles which oppose the authors’ hypothesis. Such a review will allow the reader to have a balanced opinion of the previous work and more objectively evaluate the study being presented. Post-publication reviews and comments might also aid such an objective evaluation. Eliminating discussion sections altogether could be another way of avoiding biased conclusions but it is quite extreme and might only work in journals which are aimed at very specific audiences who will go through the methods and results section anyway. A middle ground would be to have neutral discussion sections which are written by another expert who has access to all the results and data [14]. Implementing such a system would lead to authors being more careful about the claims they make regarding their methods and results and also assure the reader that the conclusions are largely unbiased. Finally, it is imperative for any researcher who is testing for multiple hypotheses to perform suitable corrections. He/she should also accurately report all versions of the experimental protocol to assure the reader that selective outcome reporting has not occurred.
Why is Reproducibility Difficult in Sciences?
Now that we have looked at methods, results and inferential reproducibility, and their importance in sciences and machine learning, let’s try to understand why conducting reproducible research is so hard. As a negative example of a paper failing to meet standards for reproducibility, consider the Adversarial Logit Pairing paper co-authored by Ian Goodfellow [6]. This paper was later retracted on the grounds that an independent replication study by Engstrom et al found the methods less effective than claimed [7]. Take another example in the field of psychology: a classic study published in 1996 by John Bargh [3], a researcher at Yale, found that infusing people’s minds with the concept of age could make them move slower. They found that when the volunteers were asked to create sentences out of words that were related to age, they walked slower as they left the laboratory. However, when another researcher, Stephane Doyen, tried to replicate the result he found no impact on the volunteers’ behaviors. Further, to test the hypothesis that Bargh’s team could have unwittingly told the volunteers how to behave, Doyen repeated the experiment, only with 50 volunteers, and 10 experimenters. Half of the experimenters were told to expect slow movements from the volunteers, and the other half, to expect faster movements. Indeed, they found that volunteers who moved slowly were in fact tested by experimenters who expected them to move slowly.
 Figure 8: Steps involved in a data analysis project, and research practices to avoid at each step [21].
Figure 8: Steps involved in a data analysis project, and research practices to avoid at each step [21].As a refresher, Figure 8 shows the different steps in a data analysis project, and at each step, the reproducibility pitfalls that can creep in, if appropriate measures are not exercised. In today’s age, the more hypotheses we examine, the more likely that we find statistically significant results that are mere coincidences. Tyler Vigen [5] shows examples of many such correlations discovered in evidently unrelated sets of data. An example showing the correlation between “Age of miss America” and “Murders by steam, hot vapour, and hot objects” is shown in Figure 9. With so many pitfalls, it is not surprising that reproducibility is hard; even in a highly deterministic and transparent field like computer science.
 Figure 9: Plot showing that the “Age of Miss America” is highly correlated with “Murders by steam, hot vapours and hot objects” [5].
Figure 9: Plot showing that the “Age of Miss America” is highly correlated with “Murders by steam, hot vapours and hot objects” [5].Modeling the Framework for False Positive Findings
Now let us talk about whether there’s a mathematical justification behind why reproducibility is hard. Ioannidis [1] makes some bold statements when he proclaims that “Most research findings are false, for most research designs and for most fields” and “It can be proven that most claimed research findings are false”. Let’s delve into some of the math behind these claims, and then we will show a few real-life cases which support the corollaries he derives from the analysis. Table 1 shows the notation used by Ioannidis.
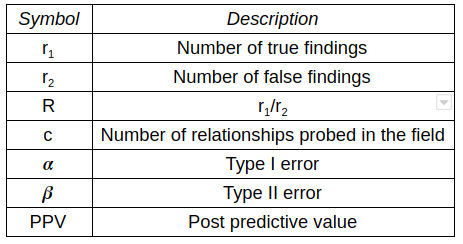 Table 1: Notation used by Ioannidis [1].
Table 1: Notation used by Ioannidis [1].Here, the type I error indicates a false positive. This means that findings are reported to be significant when in fact they have occurred by chance. Type II error indicates a false negative. This means that findings that are actually significant fail to be reported. Statistical power is given by \(1 – \beta\), and it is the probability of finding a true relationship. We can see that the (pre-study) probability of a relationship being true is \(r_1/ (r_1 + r_2)\) or \(R/(R+1)\). Ioannidis relies on post predictive value (PPV) which defines the probability of a finding being true, after a finding has been claimed based on achieving formal statistical significance. Based on these variables, Table 2 shows the probabilities of different combinations of research conclusions versus ground truth. From the table, we can easily compute the PPV as a ratio of highlighted values.
 Table 2: Comparison of research findings against the gold standard of true relationships in terms of probabilities [1].
Table 2: Comparison of research findings against the gold standard of true relationships in terms of probabilities [1].Thus, \(PPV = \frac{(1 − \beta)R}{(R − \beta R + \alpha)} \). In addition, we can derive that findings are more likely true than false if \((1 − \beta)R > \alpha \).
From these calculations, Ioannidis deduces that the smaller the sample sizes used to conduct experiments in a scientific field, the less likely the research findings are to be true. This is the case since smaller studies imply smaller statistical power, and the PPV decreases as the power decreases. Ioannidis also makes the observation that the smaller the effect sizes in a scientific field, the less likely the research findings are to be true. Power is also proportional to the effect size, and thus, the larger the effect size, the higher the power, and thus higher PPV. Finally, it can also be inferred that the greater the number of tested relationships in a scientific field, the less likely the research findings are to be true. This is the case since PPV depends on the pre-study odds \(R\) of a true finding.
Bias and its effects
We have briefly looked at bias as a barrier to inferential reproducibility in a previous section. Now, we shall analyze its effect on the PPV, the implications and also understand various bias patterns and their root causes.
Definition
According to Ioannidis [1], bias is the amalgamation of many design, data, analysis, and presentation factors that may lead to the production of research findings when they should not have been produced. Bias is modeled using a parameter \(u\) which is the probability of producing a research finding even though it is not statistically significant purely because of bias.
Effect on PPV and implications
Table 3 shows the effects of bias on the various probabilities which were introduced in Table 2. Thus, $$ PPV = \frac{(1 − \beta)R + u \beta R}{R + \alpha − \beta R + u − u\alpha + u\beta R} $$ It is apparent that when the amount of bias quantified by \( u \) increases, the PPV decreases, unless \(1-\beta \le \alpha\). This quantitatively shows that increased bias leads to an increase in the number of false research findings.
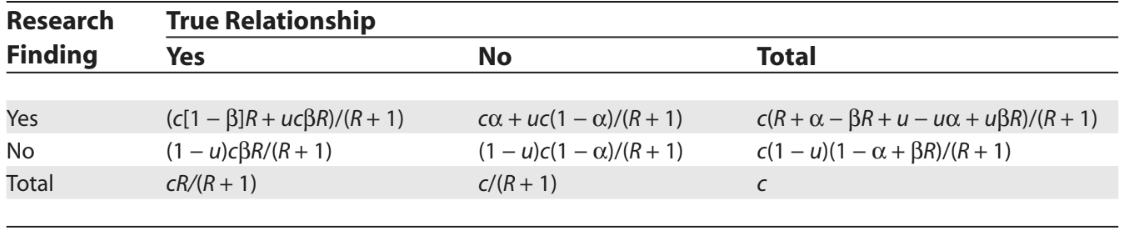 Table 3: The effect of bias on the probability of having a given relationship between the truth and the research findings [1].
Table 3: The effect of bias on the probability of having a given relationship between the truth and the research findings [1].Bias patterns
Given implications of increased bias for research reproducibility, let us look at some common bias patterns as identified by Fanelli et al. [15] in their work on bias and its root causes. Understanding these patterns will help us spot and objectively evaluate biased results/conclusions. Fanelli et al. identify the following prevalent bias patterns:
- Small-study effects: Smaller studies tend to report larger effect sizes. This might be caused by the selective reporting of results or may be due to genuine heterogeneity in study design resulting in the detection of larger effects.
- Gray literature bias: Reputed venues often do not accept studies which show small and/or statistically insignificant effects. Thus, such studies are usually found in lesser known venues such as conference proceedings (not applicable to computer science but is quite applicable to other scientific fields), books, personal communications, and other forms of “gray” literature. This means that reputed journals mostly contain studies which have large effects.
- Decline effect: Early studies in a scientific field tend to overestimate effect sizes when compared to later studies because publication bias (bias to only publish significant/positive results) has reduced over time and later studies also tend to use more accurate methods.
- Early-extreme: This pattern is related to the previous one in that early studies usually show extreme effects in any direction as such findings are often controversial and have an early window of opportunity for publication before more mature studies are conducted.
- Citation bias: Studies which show large effect sizes are usually cited more often than ones that show smaller effects.
- US effect: Certain sociological factors might cause authors from the US to overestimate effect sizes.
- Industry bias: Industry sponsorship can often bias the conclusions and demonstrated effect sizes of a study.
Fanelli et al. collected more than 3000 meta-analyses (analyses of previously published studies) from various scientific fields and tried to determine which bias patterns were prevalent in the literature using a regression-based analysis – they tested if each pattern is associated with a study’s likelihood to overestimate effect sizes. Table 4 summarizes the results of their analysis. It was quite clear that the small study effect does indeed lead to overestimation and was in fact the leading source of bias. The analysis also showed that highly cited articles and articles in reputed venues could also present overestimated effects. The analysis partially supported the claim that industry bias and the US effect lead to overestimation while it did not support the claim that early extreme studies overestimate effect sizes. This insightful analysis sheds some light on what bias patterns we should keep in mind while evaluating a study – mostly the small study effect, the citation bias and the gray literature bias.
| Pattern | Pattern leads to the overestimation of effect sizes |
| Small study effect | Strongly Supported |
| Citation Bias | Supported |
| Gray Literature Bias | Supported |
| Industry Bias | Partially supported |
| US Effect | Partially supported |
| Early Extremes | Not supported |
Table 4: Results reported by Fanelli et al. [15] on the association between various bias patterns and overestimation of effect sizes.
Possible causes of bias
Fanelli et al. also looked at the possible causes of the bias patterns they identified. They studied the role of the following factors which can affect bias:
- Pressures to publish: Direct or indirect pressures to publish can force scientists to exaggerate the magnitude and importance of their results so as to increase the visibility of their papers and/or their number of publications.
- Mutual control: Close collaborations can keep questionable research practices (QRPs) in check because many sets of eyes look at the results of such collaboration in contrast to long-distance collaborations where it is harder for all results to be thoroughly analyzed for correctness.
- Career stage: Early-career researchers might be more likely to adopt QRPs purely because of their inexperience or because it is more crucial for them to publish influential papers.
- Gender of a scientist: Statistics from the US Office of Research Integrity supports the hypothesis that men are more likely to engage in QRPs than women although there might be many alternative explanations for these statistics.
- Individual integrity: The integrity of a researcher might also affect his/her research practices.
Using the regression analysis they used to study bias patterns, Fanelli et al. tried to determine the leading causes of bias. Their results are highlighted in Table 5. Quite surprisingly, they discovered that the pressure to publish does not lead to bias. They find that mutual control can help control bias – close collaborations lead to a reduction in the number of false findings. Junior researchers were also more likely to publish false findings according to their results. Finally, they found partial evidence to support the claims that males and individuals with questionable integrity are more likely to overestimate effects. These results can help us identify risk factors for bias and think about avenues to ultimately eliminate researcher bias.
| Factor | Contributes to bias measured by the overestimation of effects |
| Pressure to Publish | Not Supported |
| Mutual Control | Supported |
| Career Level | Supported |
| Gender | Partially supported |
| Individual Integrity | Partially supported |
Table 5: Results reported by Fanelli et al. [15] on the association between various factors and overestimation of effect sizes.
Effects of Multiple Studies
It is common in academia for multiple teams to focus on similar or the same problems. To simplify the calculations, we assume that all the studies addressing the same sets of research questions are independent and that there is no bias. The probabilities expressed under the i.i.d assumption are shown in Table 6 with \(n\) being the number of independent studies. PPV can be calculated as \(\frac{R(1-\beta n)}{R+1-[1-\alpha]n – R\beta n}\). We can see from this equation that PPV decreases as the number of independent studies grows unless \(1-\beta < \alpha\). This is also seen in Figure 10, for different levels of power and for different pre-study odds.
Table 6: The effect of multiple studies on the probability of having a given relationship between the truth and the research findings [1].
Figure 10: PPV decreases as the number of studies increases for a given power and \(R\) [1].
An example of this situation is when drugs company Amgen tried to replicate some of the landmark publications in the field of cancer drug development for a report published in Nature. It could not replicate 47 out of 53 studies [18]. In the same vein, when Bayer attempted to replicate some drug target studies, 65% of the studies could not be replicated [18]. Both of these fields have long histories and have multiple companies and/or research groups working on similar problems, possibly leading to the aforementioned reproducibility issues.
Here are some suggestions to overcome the issues that are caused by multiple studies on the same problem:
- While evaluating the statistical significance of a given set of results, we must “correct” for the fact that multiple teams are working on the same problem. Thus, results must be evaluated after aggregating them across relevant studies and not independently. As discussed by Ioannidis [1], it is misleading to emphasize the statistically significant findings of a single team.
- Collecting evidence which provides more statistical power (ex. using large sample sizes, conducting low-bias meta-analyses) may help in building a more convincing argument that the discovered effects are indeed present.
- Finally, instead of chasing statistical significance, we should improve our understanding of the range of \(R\) values, the pre-study odds, in various research fields [19]. This may help in increasing the PPV and in effectively choosing research areas.
Summary
As responsible researchers, we owe it to the scientific community and the society at large to be accurate in the claims we make and research reproducibility is at the heart of such a commitment. We have described reproducibility and have also broken it down into three main types – methods, results and inferential. Methods reproducibility acts as a sanity check and assures the community that a study’s results can be replicated at least on its own data. Results reproducibility is a stronger check and concerns itself with the ability to reproduce a set of results on another dataset or using a slightly different method on the original study’s dataset. Inferential reproducibility refers to the ability of multiple researchers to arrive at the same set of conclusions after analyzing a set of results. Each of these types of reproducibility is extremely important in their own regard and we have given some examples of adverse consequences when they are not enforced. We also talked about the difficulties in achieving reproducibility and presented a mathematical argument by Ioannidis [1] which shows that it is in general very hard to achieve. General suggestions to aid reproducibility include clearly describing your methods, open-sourcing your code and documenting it thoroughly, making unbiased conclusions and avoiding bad scientific practices such as p-hacking, not correcting for multiple hypothesis testing and hypothesizing after the results are known. Finally, as a community, we should strive to enforce reproducibility by strengthening the peer review process to include code review, writing of neutral discussion sections and possibly even lifting paper length constraints.
References
- Ioannidis, John PA. “Why most published research findings are false.” PLoS medicine 2.8 (2005): e124.
- Kaplan, Robert M., David A. Chambers, and Russell E. Glasgow. “Big data and large sample size: a cautionary note on the potential for bias.” Clinical and translational science 7.4 (2014): 342-346.
- http://blogs.discovermagazine.com/notrocketscience/2012/03/10/failed-replication-bargh-psychology-study-doyen/#.XbMcVHVKjCK
- https://io9.gizmodo.com/i-fooled-millions-into-thinking-chocolate-helps-weight-1707251800
- http://tylervigen.com/spurious-correlations
- Kannan, Harini, Alexey Kurakin, and Ian Goodfellow. “Adversarial logit pairing.” arXiv preprint arXiv:1803.06373 (2018).
- Engstrom, Logan, Andrew Ilyas, and Anish Athalye. “Evaluating and understanding the robustness of adversarial logit pairing.” arXiv preprint arXiv:1807.10272 (2018).
- https://petewarden.com/2018/03/19/the-machine-learning-reproducibility-crisis/
- https://www.cs.mcgill.ca/~jpineau/ReproducibilityChecklist.pdf
- Goodman, Steven N., Daniele Fanelli, and John PA Ioannidis. “What does research reproducibility mean?.” Science translational medicine 8.341 (2016): 341ps12-341ps12.
- Wehbe, Leila, Brian Murphy, Partha Talukdar, Alona Fyshe, Aaditya Ramdas, and Tom Mitchell. “Simultaneously uncovering the patterns of brain regions involved in different story reading subprocesses.” PloS one 9, no. 11 (2014): e112575.
- Bojanowski, Piotr, Edouard Grave, Armand Joulin, and Tomas Mikolov. “Enriching word vectors with subword information.” Transactions of the Association for Computational Linguistics 5 (2017): 135-146.
- Bennett, Craig M., Michael B. Miller, and G. L. Wolford. “Neural correlates of interspecies perspective taking in the post-mortem Atlantic Salmon: an argument for multiple comparisons corrections.” Neuroimage 47, no. Suppl 1 (2009): S125.
- Avidan, Michael S., John PA Ioannidis, and George A. Mashour. “Independent discussion sections for improving inferential reproducibility in published research.” British journal of anaesthesia 122, no. 4 (2019): 413-420.
- Fanelli, Daniele, Rodrigo Costas, and John PA Ioannidis. “Meta-assessment of bias in science.” Proceedings of the National Academy of Sciences 114, no. 14 (2017): 3714-3719.
- https://www.nature.com/news/1-500-scientists-lift-the-lid-on-reproducibility-1.19970
- https://science.sciencemag.org/content/359/6377/725
- Gregory L. Garrett, “The Flat Earth Trilogy Book of Secrets II”, 2019, Lulu.com.
- Wacholder S, Chanock S, Garcia-Closas M, Elghormli L, Rothman N (2004) Assessing the probability that a positive report is false: An approach for molecular epidemiology studies. J Natl Cancer Inst 96: 434–442.
- https://media.neurips.cc/Conferences/NIPS2018/Slides/jpineau-NeurIPS-dec18-fb.pdf
- Munafò, Marcus R., et al. “A manifesto for reproducible science.” Nature human behaviour 1.1 (2017): 0021.
- https://health.ucdavis.edu/welcome/features/20071114_cardio-tobacco/
- https://courses.lumenlearning.com/waymaker-psychology/chapter/reading-parts-of-the-brain/