Figure 1. The xkcd comic plays around causation vs. correlation dichotomy and underscores the importance of the background knowledge when performing causal inference. Original: https://xkcd.com/552/
 Figure 2. A diagram illustrating the overall structure of the post
Figure 2. A diagram illustrating the overall structure of the postThe rules of causality play a role in almost everything we do. Criminal conviction is based on the principle of being the cause of a crime (guilt) as judged by a jury and most of us consider the effects of our actions before we make a decision. Therefore, it is reasonable to assume that considering causality in a world model will be a critical component of intelligent systems in the future. However, the formalisms, mechanisms, and techniques of causal inference remain a niche subject few explore. In this blog we formally consider the statement “association does not equal causation”, review some of the basics of causal inference, discuss causal relationship discovery, and describe a few examples of the benefits of utilizing causality in AI research.
1. Association vs Causation
While most of us have heard the oft-repeated saying “correlation does not imply causation”, there is rarely any formality in illustrating why this is. The word “association” is used instead of “correlation” to be consistent with the terms from the reference we lean on for the following example (Wasserman, 2004).
1.1 Association does not equal Causation
To formally illustrate this concept, we will attempt to determine the causal effect of vitamin C intake on resistance to sickness. Let X be defined as a binary indicator representing if this subject intakes vitamin C and let Y be a binary indicator of being healthy (not getting sick). X is also referred to as the ‘treatment’ in a more general setting. Now, let C1 be the value of Y if X=1 (vitamin C is taken) and C0 be the value of Y if X=0 (vitamin C is not taken). We call C0 and C1 the potential outcomes of this experiment.
 Figure 3. On the left, we see two possible outcomes for an individual where only one can be observed. On the right, a table presenting data for multiple subjects (along with the value of the unobserved outcome represented by *). Table from (Wasserman, 2004)
Figure 3. On the left, we see two possible outcomes for an individual where only one can be observed. On the right, a table presenting data for multiple subjects (along with the value of the unobserved outcome represented by *). Table from (Wasserman, 2004) For a single person, the causal effect of taking vitamin C in this context would be the difference between the expected outcome of taking vitamin C and the expected outcome of not taking vitamin C.
Causal Effect = E(C1) – E(C0)
Unfortunately, we can only ever observe one of the possible outcomes C0 or C1. We cannot perfectly reset all conditions to see the result of the opposite treatment. Instead, we can use multiple samples and calculate the association between Vitamin C and being healthy.
Association = E(Y|X=1) – E(Y|X=0)
From the table in Figure 3, we can calculate the association as being (1+1+1+1)/4 – (0+0+0+0)/4 = 1 and the causal effect, using the unobserved outcomes*, as being (4*0 + 4*1)/4 – (4*0 + 4*1)/4 = 0. We just calculated that, in this case, association does not equal causation. Observationally, there seems to be a perfect association between taking Vitamin C intake and being healthy. However, we can see there is no causal effect because we are privileged with the values of the unobserved outcomes. This inequality could be explained by considering that the people that stayed healthy practiced healthy habits which included taking Vitamin C. While it is easy to see the inequality in this instance, let us look at a real-world example of when this is not obvious.
1.2 Causality in the Media
In response to a large study that studied the relationship between income and life expectancy, Vox published an article titled “Want to live longer, even if you’re poor? Then move to a big city in California” (Klein, 2016). However, as is implied by the title of the study “The Association Between Income and Life Expectancy in the United States, 2001-2014”, the study did not presume to make this recommendation and in fact the closest statement made to the Vox recommendation was “… the strongest pattern in the data was that low-income individuals tend to live longest (and have more healthful behaviors) in cities with highly educated populations, high incomes, and high levels of government expenditures, such as New York, New York, and San Francisco, California.” (Chetty et al., 2016).
Similar to the example regarding vitamin C and health, this study only found associative effects. However, just like it is incorrect to say that vitamin C causes a person to be healthy, it is also incorrect to say that moving to California will cause you to live longer.
1.3 More examples
Let us further investigate the differences between association and causation, by starting with Pearl’s three-level causal hierarchy (Figure 4 [Pearl, et al., 2016]). The first level is association, the second level is intervention, and the third level is counterfactual. The first level, association, involves just seeing what is. It invokes purely statistical relationships, defined by the naked data. It can handle questions such as “What does a symptom tell me about a disease?”. The second level, intervention, ranks higher than association because it involves not just seeing what is, but changing what we see. It can handle questions such as “What if I take aspirin, will my headache be cured?”. The top level is called counterfactuals. A typical question in the counterfactual category is “What if I had acted differently,” thus necessitating retrospective reasoning. Questions at level i can only be answered if information from level i or higher is available.
 Figure 4: The Causal Hierarchy. Questions at level i can only be answered if information from level i or higher is available. Table from (Pearl, 2018).
Figure 4: The Causal Hierarchy. Questions at level i can only be answered if information from level i or higher is available. Table from (Pearl, 2018).
In the following, let us go through some real-world examples to show why causality matters in our daily life. Figure 5(a) plots the polio rate against ice cream sales in 1949. We can see that they are highly correlated. So does eating more ice cream increase the rate of polio? In the 1940s, public health experts certainly thought so. They even recommended that people stop eating ice cream as part of an “anti-polio diet”. Let us look at another example. Figure 5(b) gives the plots of ice cream sales and shark attacks. Again, they are highly correlated. So does eating ice cream lead to the increase of shark attacks? It seems very weird from our common sense. Then why are there high correlations in these two cases? From the plots, we can see that in both cases, there is a peak around August. From a causal view, in the first case, it is the temperature that affects both ice cream sales and polio rates. With the increase of temperature, both ice cream sales and polio rates increase, thus leading to a high correlation between ice cream sales and polio. Similarly, in the second case, temperature is also the confounder of ice cream sales and shark attacks. It is the ignorance of a confounder that causes the spurious correlation. If we directly analyze data at hand without investigation and thinking, it is possible to make misleading conclusions.
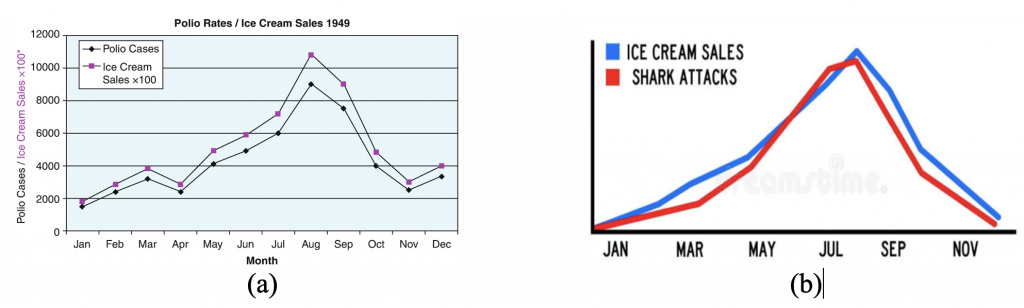 Figure 5: Examples of spurious correlation due to confounders. (a) Plots of ice cream sales and polio rates. Although ice cream sales and polio rates are highly correlated, they are not causally related. (b) Plots of ice cream sales and shark attacks. Similarly, although ice cream sales and shark attacks are highly correlated, they are not causally related. From https://www.kdnuggets.com/2019/09/risk-ai-big-data.html
Figure 5: Examples of spurious correlation due to confounders. (a) Plots of ice cream sales and polio rates. Although ice cream sales and polio rates are highly correlated, they are not causally related. (b) Plots of ice cream sales and shark attacks. Similarly, although ice cream sales and shark attacks are highly correlated, they are not causally related. From https://www.kdnuggets.com/2019/09/risk-ai-big-data.htmlLet us look at another example about locomotor disease and respiratory disease. Sackett did two experiments to study the relationship between locomotor disease and respiratory disease [Sackett, 1979]. In the first experiment, he collected data from 257 hospitalized individuals and found a correlation between locomotor disease and respiratory disease with an odds ratio 4.06. The odds ratio is a statistic that quantifies the strength of association between two events; two events are independent if and only if their odds ratio equals 1. In the second experiment, he collected data from 2783 individuals from the general population and found that there was no correlation between locomotor disease and respiratory disease, with an odds ratio 1.06. Why does this happen? Which result is more reasonable? From a causal perspective, we have the causal graph given in Figure 6: both diseases cause hospitalization. From this graph, it is easy to see that locomotor disease and respiratory disease are marginally independent, but they are dependent given hospitalization. Hence, the spurious correlation is due to sample selection bias in the first experiment, where the data were only collected from the hospital.
 Figure 6: Causal graph over locomotor disease, respiratory disease, and hospitalization
Figure 6: Causal graph over locomotor disease, respiratory disease, and hospitalization
2. Causal Discovery
Finding causal relationships is one of the fundamental tasks in science. A widely used approach is randomized experiments. For example, to examine whether a recently developed medicine is useful for cancer treatment, researchers recruit subjects and randomly divide subjects into two groups. One is the control group, where the subjects are given placebo, and the other is the treatment group, where the subjects are given the newly developed drug. The reason of randomization is to remove possible effects from confounders. For example, age can be one of the possible confounders which affects both taking the drug or not and the treatment effect. Thus, in practical experiments, we should keep the distribution of ages in the two groups almost the same. Technically, one may use propensity score matching to remove the effects from possible confounders.
To quantitatively estimate the effectiveness of the medicine, one may use Average Treatment Effect (ATE):
where do(X=1) means treating the subjects with medicine, and do(X=0) means treating the subjects with placebo. The do operator represents intervention; it removes all incident edges to X and sets X to a fixed value (see Figure 7).
 Figure 7: Intervening on X is equivalent to removing all incident edges to X and setting Xto a fixed value
Figure 7: Intervening on X is equivalent to removing all incident edges to X and setting Xto a fixed value However, in many cases, randomized experiments are very expensive and hard to implement, and sometimes it may even involve ethical issues. In recent decades, inferring causal relations from purely observational data, known as the task of causal discovery, has drawn much attention in machine learning, philosophy, statistics, and computer science.
Classic approaches to causal discovery are roughly divided into two types. In the late 1980’s and early 1990’s, it was noted that under appropriate assumptions, one could recover a Markov equivalence class of the underlying causal structure based on conditional independence relationships among the variables (Spirtes et al., 1993). This gave rise to the constraint-based approach to causal discovery, and the resulting equivalence class may contain multiple directed acyclic graphs (DAGs) or other graphical objects to represent causal structures, which entail the same conditional independence relationships. The required assumptions include the causal Markov condition and the faithfulness assumption, which entail a correspondence between d-separation properties in the underlying causal structure and statistical independence properties in the data.
Consider an example of using conditional independence constraints to learn causal relationships (Figure 8). Suppose there are three variables X, Y, and Z, with the corresponding causal graph: Y <- X -> Z. In this case, there is only one independence constraint that given X, Y and Z are independent. From this constraint, we can recover the causal graph up to the Markov equivalence class:Y – X – Z. Note that in this case, we cannot uniquely determine the causal directions; in particular, Y <- X -> Z, Y -> X -> Z, and Y <- X <- Z have the same independence constraints (Figure 8(a)).
Now consider another example (Figure 8(b)): Y -> X <- Z. In this case, Y and Z are dependent given X, but Y and Z are marginally independent. Hence, we can uniquely determine the causal structure between the three variables, which is Y -> X <- Z.
The so-called score-based approach (see, e.g., (Chickering, 2003; Heckerman et al., 1995)) searches for the equivalence class which gives the highest score under some scoring criteria, such as the Bayesian Information Criterion (BIC), the posterior of the graph given the data (Heckerman et al., 1997), and the generalized score functions (Huang et al., 2018).
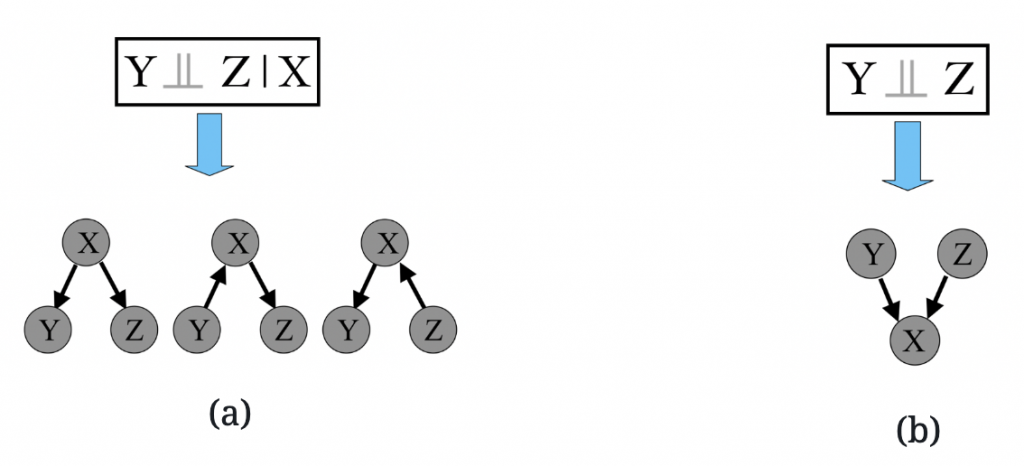 Figure 8: Illustrations of using conditional independence constraints to identify the causal structure. (a) If Y and Z are independent given X, then we can identify the skeleton, but the causal directions are not identifiable; that is, the causal structure is identified up to the Markov equivalence class. (b) If Y and Z are marginally independent, then the causal structure over X, Y, and Z is uniquely identified.
Figure 8: Illustrations of using conditional independence constraints to identify the causal structure. (a) If Y and Z are independent given X, then we can identify the skeleton, but the causal directions are not identifiable; that is, the causal structure is identified up to the Markov equivalence class. (b) If Y and Z are marginally independent, then the causal structure over X, Y, and Z is uniquely identified.Another set of approaches is based on constrained functional causal models, which represent the effect as a function of the direct causes together with an independent noise term. The causal direction implied by the constrained functional causal model is generically identifiable, in that the model assumptions, such as the independence between the noise and cause, hold only for the true causal direction and are violated for the wrong direction. Examples of such constrained functional causal models include the Linear, Non-Gaussian, Acyclic Model (LiNGAM (Shimizu et al., 2006)), the additive noise model (Hoyer et al., 2009; Zhang and Hyvärinen, 2009a), and the post-nonlinear causal model (Zhang and Chan, 2006; Zhang and Hyvärinen, 2009b).
Suppose we have two observed variables X and Y, with X -> Y. We further assume that Y satisfies the following functional causal model:
where X is the cause of Y, E is the noise term, representing the influence from some unmeasured factors, and f represents the causal mechanism that determines the value of Y, together with the values of X and E. In addition, the noise term E is independent of the cause X. If we regress in the reverse direction, that is,
E’ is no longer independent of Y. Thus, we can make use of this asymmetry to identify the causal direction.
Let us go through a real-world example (Figure 9 [Hoyer et al., 2009]). Suppose we have observational data from the ring of an abalone, with the ring indicating its age, and the length of its shell. We want to know whether the ring affects the length, or the inverse. We can first regress length on ring, that is,
and test the independence between estimated noise term E and ring, and the p-value is 0.19. Then we regress ring on length:
and test the independence between E’ and length, and the p-value is smaller than 10e-15, which indicates that E’ and length are dependent. Thus, we conclude the causal direction is from ring to length, which matches our background knowledge.
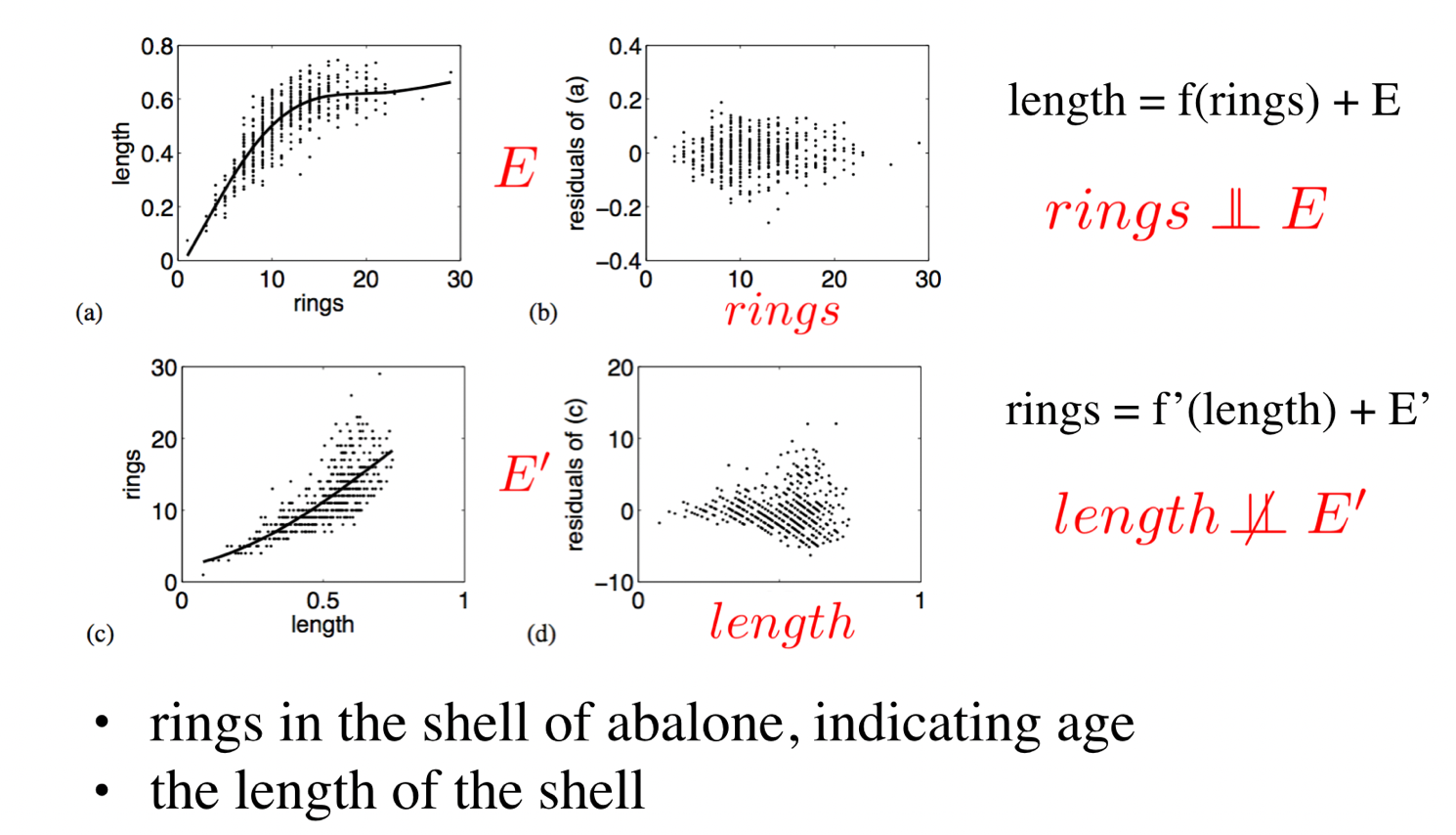
Figure 9: Identifying the causal direction between rings and length of shell, by using the asymmetry between estimated noise and hypothetical causes. From Hoyer et al., 2009. 3. Causal Inference in the Wild
Having discussed theoretical foundations of causal inference, we now turn to the practical viewpoint and walk through several examples that demonstrate the use of causality in machine learning research. In this section, we limit ourselves to only a brief discussion of the intuition behind the concepts and refer the interested reader to the referenced papers for a more in-depth discussion.
3.1 Domain adaptation
We begin by considering a standard machine learning prediction task. At first glance, it may seem that if we only care about prediction accuracy, we do not need to worry about causality. Indeed, in the classical prediction task we are given training data
sampled iid from the joint distribution PXY and our goal is to build a model that predicts Y given X, where X and Y are sampled from the same joint distribution. Observe that in this formulation we essentially need to discover an association between X and Y, therefore our problem belongs to the first level of the causal hierarchy.
Let us now consider a hypothetical situation in which our goal is to predict whether a patient has a disease (Y=1) or not (Y=0) based on the observed symptoms (X) using training data collected at Mayo Clinic. To make the problem more interesting, assume further that our goal is to build a model that will have a high prediction accuracy when applied at the UPMC hospital of Pittsburgh. The difficulty of the problem comes from the fact that the test data we face in Pittsburgh might follow a distribution QXY that is different from the distribution PXY we learned from. While without further background knowledge this hypothetical situation is hopeless, in some important special cases which we will now discuss, we can employ our causal knowledge to be able to adapt to an unknown distribution QXY.
First, notice that it is the disease that causes symptoms and not vice versa. This observation allows us to qualitatively describe the difference between train and test distributions using knowledge of causal diagrams as demonstrated by Figure 10.

(a) Target Shift (b) Conditional Shift (c) Generalized Target Shift
Figure 10. Qualitative description of the impact of domain on the distribution of symptoms and marginal probability of being sick. This figure is an adaptation of Figures 1,2 and 4 by Zhang et al., 2013.
Target Shift. The target shift happens when the marginal probability of being sick varies across domains, that is, PY ≠ QY.To successfully account for the target shift, we need to estimate the fraction of sick people in our target domain (using, for example, EM procedure) and adjust our prediction model accordingly.
Conditional Shift. In this case the marginal probability of being sick is independent of the domain, but sick people might have different symptoms in different domains, that is, PX|Y ≠ QX|Y . The conditional shift is harder to account for, but if we have a background knowledge that allows modelling the shift, then we can adjust the training set so its distribution matches the distribution of symptoms in the target domain.
Generalized Target Shift. This case is a combination of the two previous scenarios and thus requires a combination of the aforementioned approaches.
To summarize, the causal language allows us to break down the domain adaptation problem into three distinct cases which require different approaches. Despite the problem is in general intractable, in real-life tasks one may rely on the background knowledge to facilitate domain adaptation. We refer the interested reader to the work by Zhang et al., 2013 for a complete discussion.
3.2 Selection bias
When working at the association level of the causal hierarchy, where most of the practical machine learning tasks live, we rarely put strong assumptions on the data generation process. Indeed, given train and test data that are sampled from the same distribution, we typically find the model with the highest predictive power. However, when working at the other levels of causal hierarchy, utmost care must be taken to ensure that the data generation process does not introduce any biases in our analysis.
As a motivation example (Mester, 2017), consider a study that was conducted in 1987 and found that “cats falling from higher stories have fewer injuries than cats falling from lower down.” To explain this strange phenomenon, researchers hypothesized that when falling from higher floors, cats have more time to prepare for landing and thus receive fewer injuries.
To identify possible flaws in the analysis, it is important to inspect how the data for this study was collected. It turns out that the dataset was constructed from veterinarian reports. However, one can imagine that if a cat dies after falling from a high floor, it is likely not to be delivered to the hospital. Therefore, the dataset collected from the veterinarian reports misses some observations, thereby introducing bias in the analysis.

(a) Selection bias on the cause (b) Selection bias on the outcome
Figure 11. Two types of selection bias. S is a binary indicator of whether or not the corresponding observation is missing from the dataset. The bias in subfigure (a) is harmless for the analysis as the missingness is determined by the cause (i.e. floor number in the above example). In contrast, in subfigure (c) the missingness is not independent of the outcome given the cause and hence should be specifically accounted for.
Figure 11 offers a causal perspective on the selection bias. Let S be a binary indicator of whether an observation is missing from the analysis or not. Then two types of selection bias can be distinguished:
Selection on the cause. In this case, the missingness is fully determined by the cause X and hence is independent of the outcome given the cause. Mathematically, this intuition can be summarized as follows:
P[Y|X, S] = P[Y|X].
As a result, in this case, we can perform standard inference without specifically accounting for the selection bias.
Selection on the outcome. In the motivation example introduced at the beginning of this section, the missingness was not independent of the outcome given the cause. Indeed, the missingness is determined by whether a cat was dead which obviously depends on the outcome even if the cause is given. As we discussed, ignoring missing values may lead to the flaws in the analysis and hence special procedures to account for the selection bias should be used in this case (Zhang et al., 2016).
To conclude this section, we note the selection bias may appear in many natural situations and researchers should carefully analyze the data generation process to account for this bias. The interested reader may refer to the work of Zhang et al., 2016, to find out more about the methods to accommodate selection bias.
3.3 Knockoffs
In Section 2 we discussed several tools to perform causal discovery. Unfortunately, these tools often require strict assumptions and are not as flexible as modern machine learning algorithms such as neural networks or kernel SVM. Consider the following toy problem. Let Y be a continuous variable indicating the level of some hypothetical disease that is caused in whole by some genome mutations. Suppose also that we are given a set of candidate genes {X1, X2, …,Xp} that includes all possible confounding factors. The goal is to find all genes that cause the disease, that is, all genes Xi such that (X-i is the set of all genes but Xi):

The hypothetical (and unknown) relationship between genes and disease is depicted in Figure 12. Observe that all genes may be related to each other, however, only a few of them are connected to the disease, that is, only a few genes actually cause the disease. This observation corroborates the hardness of our problem as we need to distinguish correlation from causation. While we can apply general tools for causal discovery to identify all edges, it seems very fruitful to use some modern machine learning methods such as Decision Trees (if we want to enforce interpretability) or Lasso regression (if we have a background knowledge about sparsity) and use of-the-shelf measure of feature importance to identify the causes.
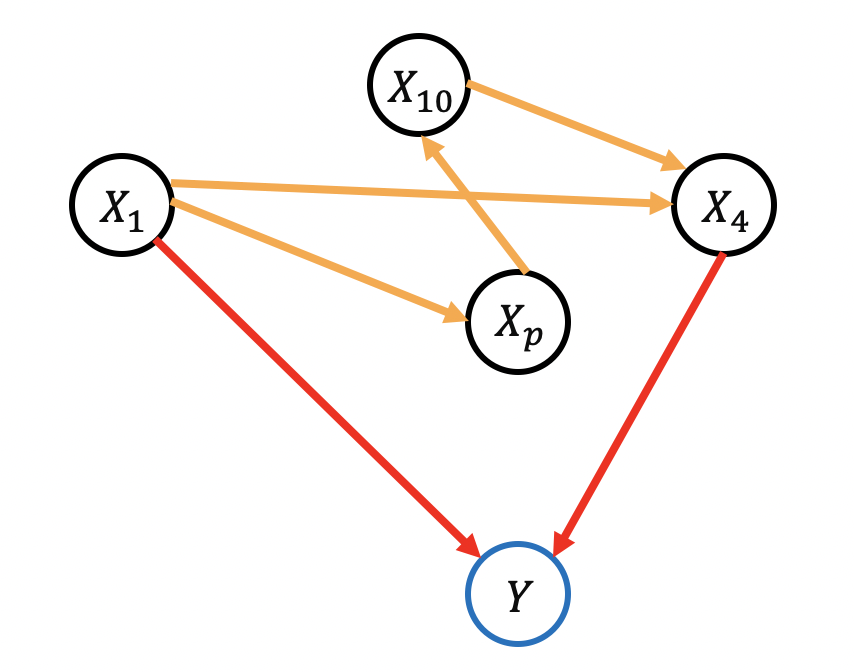
Figure 12. Hypothetical causal model. Red edges come from the genes that cause the disease, whereas orange edges represent the internal association between genes. Of course, blind application of the aforementioned techniques will not be a correct solution to the problem, because most of the machine learning tools cannot distinguish between correlation and causation and hence we may end up with wrong findings. However, a recent breakthrough in statistics allows researchers to take the best from both causal and ML worlds and perform causal inference using their favorite ML tools.
The key component of the knockoff method (Figure 13) is an additional set of features that imitate the original ones. More concretely, for each gene Xi we carefully construct a “fake” gene ~Xi. The construction ensures that while the fake copy is “similar enough” to the original one, the level of the disease Y is independent of ~Xi given all real genes, that is, the fake gene does not cause the disease. Feeding any machine learning algorithm with both original and artificial genes, we obtain a measure of importance for each of them. At this point, a carefully designed statistical procedure (Candes et al., 2018) which selects the set of target genes is called.

Figure 14. Construction of “fake” genes in the knockoff method. Observe that newly added genes are independent of the disease given all the original genes.The intuition behind the statistical selection is as follows. For any real gene that does not cause the disease, we expect its significance to be close to the significance of its fake copy (because neither of them is connected to Y with an arrow). In contrast, for any gene which is a real cause of Y we expect the significance of this gene to be much higher than the significance of its knockoff. This intuition is formalized in a paper by Candes et al., 2018 where the rigorous statement is formulated.
To conclude, we reiterate that the knockoff method is a novel statistical tool that allows researchers to perform a causal inference using any modern ML algorithm under some assumptions.
4. Discussion
So far we have discussed theoretical foundations of causal inference and went through several examples at the intersection of the causality and machine learning research, we can ask ourselves about the general approach to causal inference in data analysis.
As we have seen from various examples discussed in this blog, ignorance of the causal structure of the problem may lead to false conclusions. Because problems involving causal inference often appear in some socially important fields of research, such as medicine, sociology and finance, utmost care must be taken to validate any causal claim that researchers want to make after analyzing the data.
At a more practical level, it seems to us that the simple but crucial first step in conducting any study is to understand the level of the causal hierarchy our research question belongs to. Indeed, without this understanding a researcher is at danger of making wrong conclusions with potentially catastrophic consequences and thus this step should never be neglected.
Having identified the level of the hierarchy, a researcher should carefully choose the tools they use in their analysis. Unfortunately, it is often the case that higher levels of causal hierarchy significantly restrict the variety of methods one may use to answer the research question, sometimes introducing an additional constraint on sample size. Nonetheless, causal inference is a developing field of research and recent advances in statistics (knockoffs) suggest that in the nearest future the gap between (i) theoretically valid and (ii) practically appealing methods will reduce.
Finally, we underscore that to accurately perform causal inference, one often needs to rely on background knowledge. Indeed, data alone is never sufficient to understand whether all the necessary confoundings are included in the dataset or what regime of domain adaptation (Section 3.1) is present in the problem at hand. It is only an expert in the field who can competently answer these questions. Thus, we emphasize the critical importance of collaboration with field scientists when performing causal inference.
5. Summary
The goal of this blog post is to introduce readers to causal inference and show them its criticality and utility in their research. We have introduced the foundations of causal inference and walked readers through examples that highlight its importance in machine learning research. We then explored several well-known methods of causal discovery, including constraint-based methods and functional causal model-based methods, and some examples of how they are used in real-world experiments. Finally, we emphasized the need to consider which level on the causal hierarchy a research question inhabits and the need to use the proper tools, models, and data to then correctly answer that question. Our references below provide ample avenues to explore this area deeper and we hope this often dismissed perspective helps you in your research!
References
David M. Chickering. Optimal structure identification with greedy search. Journal of Machine Learning Research, 3:507–554, 2003.
David Heckerman, Dan Geiger, and David M. Chickering. Learning Bayesian networks: The combination of knowledge and statistical data. Machine Learning, 20:197–243, 1995.
Patrik O. Hoyer, Dominik Janzing, Joris Mooji, Jonas Peters, and Bernhard Schölkopf. Nonlinear causal discovery with additive noise models. In Advances in Neural Information Processing Systems 21, Vancouver, B.C., Canada, 2009
Judea Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, Cambridge, 2000.
Shohei Shimizu, Patrik O. Hoyer, Aapo Hyvärinen, and Antti Kerminen. A linear non-Gaussian acyclic model for causal discovery. Journal of Machine Learning Research, 7:2003–2030, 2006.
Peter Spirtes, Clark Glymour, and Richard Scheines. Causation, Prediction, and Search. Spring-Verlag Lectures in Statistics, 1993.
David L., Sackett. Bias in analytic research. Journal of Chronic Diseases 32: 51-63.
Kun Zhang and Aapo Hyvärinen. On the identifiability of the post-nonlinear causal model. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, Montreal, Canada, 2009b.
Biwei Huang, Kun Zhang, Yizhu Lin, Bernhard Schölkopf, and Clark Glymour. Generalized score functions for causal discovery. In KDD, pages 1551–1560, 2018.
Judea Pearl, Madelyn Glymour, Nicholas P. Jewell. Causal Inference in Statistics – A Primer. Wiley, 2016.
Kun Zhang, Bernhard Schölkopf, Krikamol Muandet, and Zhikun Wang, “Domain adaptation under target and conditional shift,” Proc. 29th International Conference on Machine Learning (ICML 2013).
Kun Zhang, Jiji Zhang, Biwei Huang, Bernhard Schölkopf, Clark Glymour, “On the Identifiability and Estimation of Functional Causal Models in the Presence of Outcome-Dependent Selection,” Proceedings of the 32rd Conference on Uncertainty in Artificial Intelligence (UAI 2016)
Emmanuel Candes, Yingying Fan, Lucas Janson, and Jinchi Lv. J. R. “Panning for Gold: ”Model-X“ Knockoffs for High-dimensional Controlled Variable Selection”, Stat. Soc. B. (2018).
Wasserman, Larry. 2004. All of Statistics: A Concise Course in Statistical Inference. Springer, New York, NY.
Klein, Ezra. 2016. “Want to Live Longer, Even If You’re Poor? Then Move to a Big City in California.” Vox. Vox. April 13, 2016. https://www.vox.com/2016/4/13/11420230/life-expectancy-income.
Chetty, Raj, Michael Stepner, Sarah Abraham, Shelby Lin, Benjamin Scuderi, Nicholas Turner, Augustin Bergeron, and David Cutler. 2016. “The Association Between Income and Life Expectancy in the United States, 2001-2014.” JAMA: The Journal of the American Medical Association 315 (16): 1750–66.