Figure 1. The FACT diagnostic is a general framework that allows easier and flexible analyses of trade-offs between group fairness and predictive performance (type-1 trade-off), or among different types of group fairness definitions (type-2 trade-off).
As machine learning continues to be more widely used for applications with a societal impact like mortgage lending and predictive policing, model developers face increased regulatory scrutiny to verify and understand model fairness. To provide quantitative tests of model fairness, practitioners further need to choose between multiple definitions of fairness that exist in the machine learning literature. One prevalent class of these definitions is group fairness, which measures how a group of individuals with certain protected attributes (like gender or race) is impacted differently from other groups. This general notion is widely studied under the name of disparate impact in the legal context, and one specific instance of this notion has been accepted by the US government as a guideline towards a fair employment process in 1978.
From a technical point of view, however, several definitions of group fairness have been shown to conflict with one another usually with a necessary cost in loss of accuracy. Throughout this post, we will refer to this inherent trade-off between accuracy and fairness as type-1 trade-off, and the trade-off among different notions of group fairness as type-2 trade-off. Such considerations complicate the practical development and assessment of machine learning models designed to satisfy group fairness, as the conditions under which these trade-offs necessarily occur can be too abstract to understand and time-consuming to verify. As a result, it is difficult in general for model developers to explore these trade-offs efficiently. Although previous works have studied these trade-offs in an ad hoc and definition-specific manner, there remains a pressing need for a more general and unified perspective.
Figure 2. Understanding type-1 (left) and type-2 (right) trade-offs in group fairness can speed up the model development process by reducing the time and effort spent on trying to obtain specifications that are not feasible.
To put these issues into context, consider an engineer training a model to satisfy both fairness and performance specifications. Shown in Figure 2 (left), typically the engineer needs to resort to several iterations of training and evaluating models with different levels of performance and fairness (yellow circles). But with a knowledge of the trade-off boundary representing type-1 trade-off (blue solid line), the engineer can easily understand the frontier of achievable accuracy and fairness levels and quickly rule out specifications that are not feasible, all before training or evaluating any models. This reduces the time and effort spent on trying to obtain a model with unrealistic configurations. Furthermore, it is important for not only the engineer but also the regulators to fully grasp type-2 trade-offs with a list of compatible/incompatible group fairness notions (Figure 2 right), in order to provide reasonable guidelines.
In our ICML 2020 paper, we present the FACT (FAirness-Confusion Tensor) diagnostic as a tool for addressing the above desiderata for better understanding trade-offs involving group fairness. The diagnostic hinges on the observation that multiple group fairness definitions can be represented in a unified fashion with the FACT, which is the traditional confusion matrix for each group with different attribute values stacked together (Figure 3). All group fairness definitions take the form of equating conditional probabilities for different protected groups, and these conditional probabilities can be expressed succinctly using the elements of the FACT.
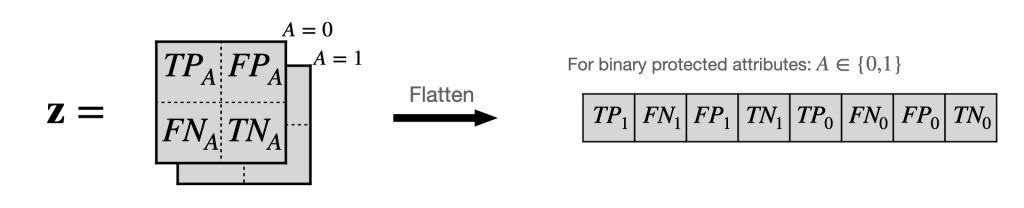 Figure 3. Fairness-confusion tensor (FACT), denoted throughout the post as \( \mathbf{z} \), is simply the confusion matrix (true-positives, false-positives, false-negatives, true-negatives) for each group with protected attribute values \(A\) stacked together. For a single binary protected attribute (e.g. \(A \in \{0, 1\} \)), which is our main focus throughout this post, the resulting tensor can be flattened into an 8-dimensional vector as shown. This allows the simultaneous treatment of multiple protected attributes easily and provides a unified representation for all group fairness notions.
Figure 3. Fairness-confusion tensor (FACT), denoted throughout the post as \( \mathbf{z} \), is simply the confusion matrix (true-positives, false-positives, false-negatives, true-negatives) for each group with protected attribute values \(A\) stacked together. For a single binary protected attribute (e.g. \(A \in \{0, 1\} \)), which is our main focus throughout this post, the resulting tensor can be flattened into an 8-dimensional vector as shown. This allows the simultaneous treatment of multiple protected attributes easily and provides a unified representation for all group fairness notions.
For instance, consider a binary classification task, with \( \hat{Y} \) being the classifier prediction and \(A\) being the binary protected attribute. Demographic parity (DP), which is one of the most widely used notions of group fairness, is defined as equating the positive prediction rate for both groups with \(A = 1\) and \(A = 0\). In terms of conditional probability, this is \(P(\hat{Y}=1 | A = 1) = P(\hat{Y} =1 | A = 0) \), which can be formatted as a linear system of the FACT: $$\mathbf{M} \mathbf{z} = 0, \text{ where } \mathbf{M} = \frac{1}{N_0 + N_1} \begin{pmatrix} N_0 & 0 & N_0 & 0 & -N_1 & 0 & -N_1 & 0 \end{pmatrix}$$ with \(N_a\) being the sum of all elements of the slice of the FACT for group with \(A = a\). Other notions of group fairness can be similarly expressed either in linear or quadratic format with respect to the FACT.
With this tool for characterizing different group fairness notions, we can formulate type-1 trade-off in a unified model-agnostic fashion via linear programs over the FACT. This formulation extends similarly to type-2 trade-offs and model-specific scenarios with some tweaks, yielding an even more comprehensive framework for understanding a wide range of trade-offs involving group fairness.
Optimization over the FACT
We define a linear program over the possible FACTs called Least-squares Accuracy-Fairness Optimality Problem (LAFOP):
$$\min_\mathbf{z} \mathbf{c}^T \mathbf{z} \quad \text{ such that } \quad \mathbf{M} \mathbf{z} \leq \epsilon$$
Essentially the optimization problem searches for a valid FACT that satisfies a specified set of fairness conditions linearly expressed using the fairness matrix \(\mathbf{M}\) while optimizing for the classification error rate in the objective.
Solving this optimization problem for different values of \(\epsilon\) yields different objective function values, which we denote as \(\delta\). We are then interested in the resulting (\(\epsilon, \delta\))-solutions of LAFOP, which intuitively represent FACTs that deviate from perfect fairness and perfect accuracy by \(\epsilon\) and \(\delta\) respectively. These (\(\epsilon, \delta\)) value pairs naturally translate to the trade-off boundary for type-1 trade-off called the FACT Pareto frontier, just like the blue solid line in our earlier example: changes in \(\delta\) as we vary \(\epsilon\) will indicate the change in the best achievable classification error rate by the model (i.e. bigger \(\delta\) means a bigger drop in accuracy). Note that by definition, this frontier is model-agnostic, enabling the engineer to apply it before training any models. We discuss more in the paper how LAFOP is also amenable to proving general incompatibility theorems for type-2 trade-offs.
While LAFOP is designed to be model agnostic, we can modify it to be model specific in case there is a trained model whose limitations in achieving fairness via post-processing need to be assessed. This leads to a model-specific (MS) variation of LAFOP called MS-LAFOP, which places additional model-dependent constraints on the solution space of the FACTs. Because now the problem is grounded on a specific model, (\(\epsilon, \delta\))-solutions of the MS-LAFOP yield a more realistic FACT Pareto frontier. The solutions of the MS-LAFOP naturally provide a way to post-process that model for better fairness guarantees, as we discuss in the paper.
Demonstration on the UCI Adult Dataset
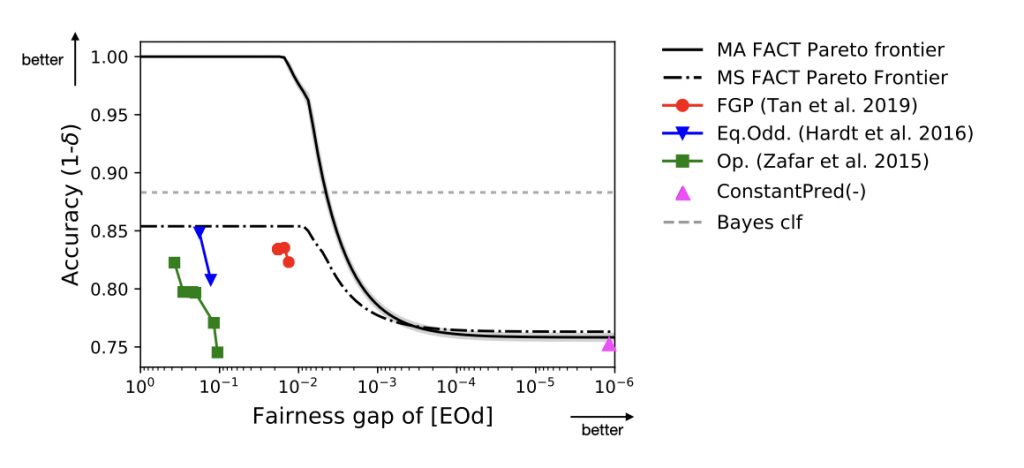 Figure 4. The FACT Pareto frontiers show the trade-off between accuracy and fairness, and several algorithms in the frontier are also plotted for comparison.
Figure 4. The FACT Pareto frontiers show the trade-off between accuracy and fairness, and several algorithms in the frontier are also plotted for comparison.
Using the UCI Adult dataset with gender as the protected attribute, we demonstrate the FACT diagnostic’s usefulness. Figure 4 shows both model-agnostic (MA) and model-specific (MS) FACT Pareto frontiers by plotting (\(\epsilon, \delta\))-solutions, under the equalized odds (EOd) fairness. Essentially the frontier allows us to gauge the type-1 trade-off, i.e., how accuracy inevitably drops for increasing levels of fairness. One thing to note when is that the MA FACT Pareto frontier is model-agnostic, and therefore does not take into account the Bayes error of the problem, which is an irreducible amount of error in the problem due to inherent statistical fluctuations in the data preventing a perfectly accurate classifier. This means that the \(\delta\) of 0 (equivalent to accuracy of 1) for the MA FACT Pareto frontier should be interpreted as the Bayes error, not as the value 0 itself. In other words, when viewing the frontier, relative change of the accuracy is more important than the actual values on the y-axis for the model-agnostic case. Accordingly, the frontier tells us that only for the fairness gaps below 0.01 will the accuracy of any models actually start to drop. With results from some fair classification algorithms plotted in the frontier, we can also observe that FGP provides a better trade-off scheme compared to the other two methods presented. Unlike the MA FACT Pareto frontier, its model-specific counterpart has a benefit of providing tighter bounds, as it depends on the pre-trained model used as a reference point.
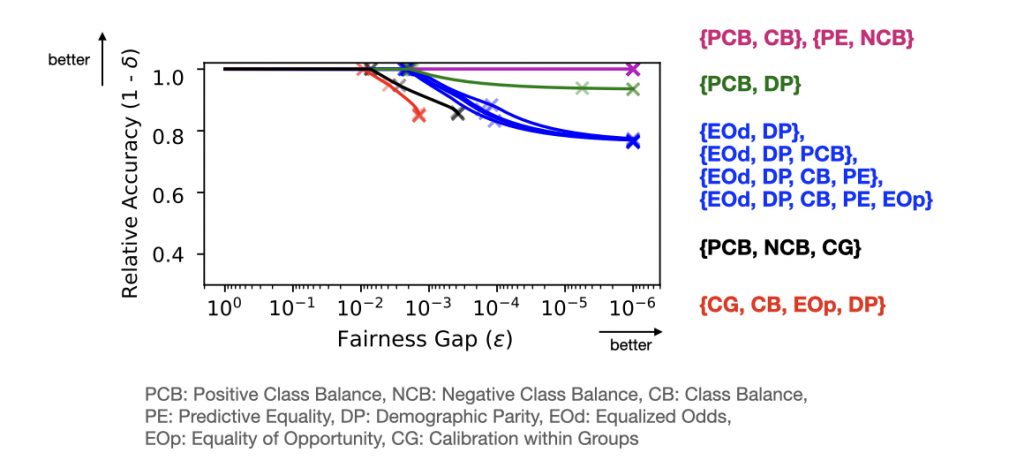 Figure 5. It is also possible to plot trade-offs that involve a set of fairness conditions together. Fairness gap for a set of fairness definitions is the sum of individual gaps for each definition in the set. For the details of each definition, refer to Table 1 of our paper.
Figure 5. It is also possible to plot trade-offs that involve a set of fairness conditions together. Fairness gap for a set of fairness definitions is the sum of individual gaps for each definition in the set. For the details of each definition, refer to Table 1 of our paper.
Modifying the constraints on LAFOP to encode multiple fairness definitions leads to the MA FACT Pareto frontier for scenarios when those fairness conditions are imposed simultaneously. This is shown in Figure 5, where we observe different sets of group fairness imposed lead to different behaviors of the frontier. Notably, the two halted lines in red and black that do not reach smaller fairness gaps verify the well-established type-2 trade-off result among the given group fairness definitions.
What’s Next?
The FACT diagnostic aids an intuitive understanding of the trade-offs involved in group fairness by merging multiple definitions into a single framework. Using the FACT as a tool to characterize group fairness definitions, solving LAFOP defined over the FACTs directly shows the degree of trade-offs present in the problem, prior to any training of the model. In this post we have mostly focused on LAFOP and model-agnostic cases, but as we discuss further in the paper, the FACT diagnostic more broadly encompasses different optimization problems while at the same time demonstrating versatility of improving models via post-processing.
If you are interested, check out the paper and code for more details. This is joint work with Jiahao Chen (JPMorgan AI Research) and Ameet Talwalkar (CMU).
Here are some relevant references.
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.