This week researchers from all across computer science, social sciences and humanities are gathering for the flagship conference of the emerging field of Fairness, Accountability and Transparency in algorithmic systems: FAccT. FAccT (previously FAT*) is dedicated to the inherent risks that come with the increasing adoption of data-driven algorithmic decision making systems in socially consequential domains such as policing, criminal justice, health care and education. The conference was formed as a venue for the increasing volume of work in this area in 2018 and has since become one of the top venues in the study of societal impacts of machine learning – submissions have more than quadrupled since the inaugural conference!
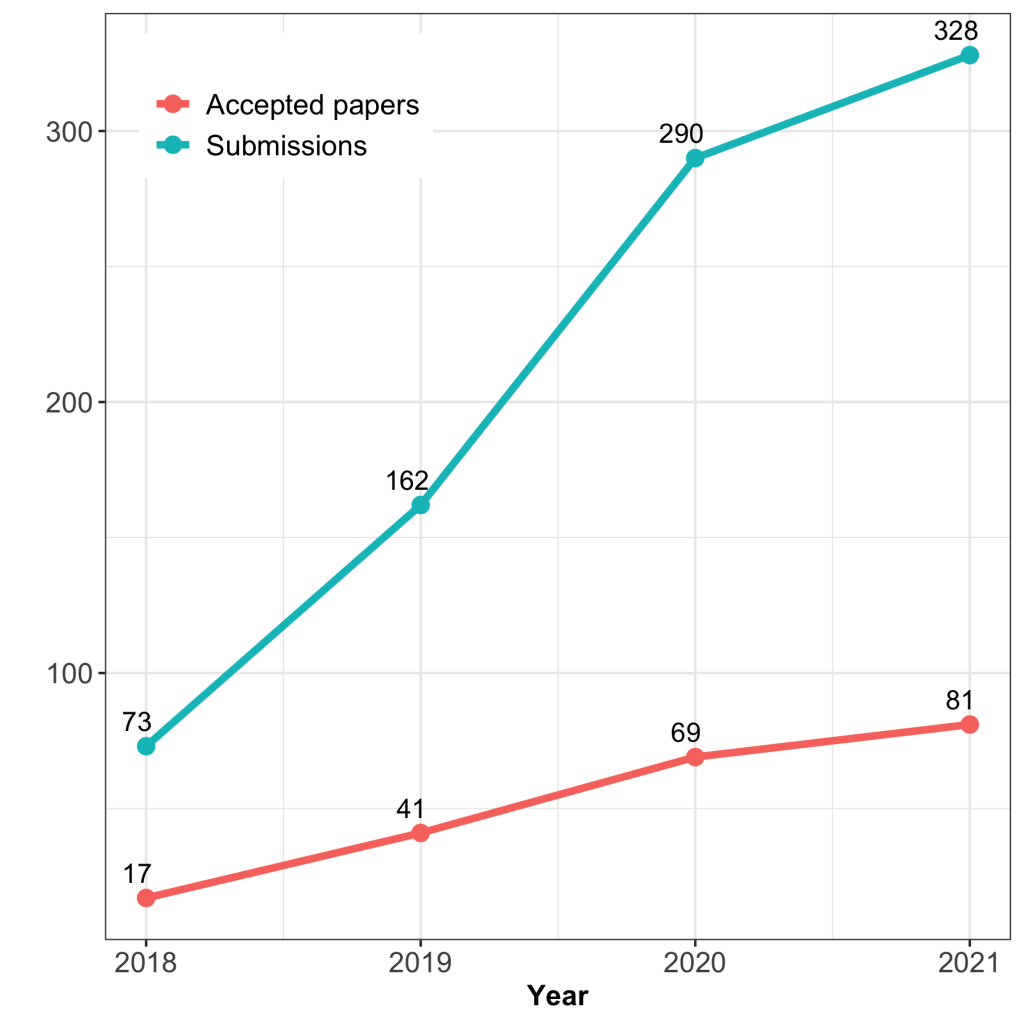 Number of submitted and accepted papers at FAccT since inaugural conference.
Number of submitted and accepted papers at FAccT since inaugural conference.
Now in its 4th year, the fully-virtual event spans 82 paper presentations from 15 different countries across 14 time zones as well as 13 tutorials, a doctoral consortium and 10 CRAFT sessions aimed at Critiquing and Rethinking Accountability, Fairness and Transparency. Complementing paper presentations and tutorials, the CRAFT sessions aim for interaction between participants with different backgrounds including academics, journalists, advocates, activists, educators and artists with the idea of reflection and discussion of the field from a more holistic perspective.
Many influential papers have been published at FAccT even within these first few years of the conference. Examples include Joy Buolamwini and Timnit Gebru’s 2018 study on Gender Shades in which the authors uncover significantly higher error rates in commercial gender classification for darker-skinned females which led companies to adjust their algorithms and sparked a wider discussion of similar problems in computer vision. Leading up to this year’s conference, the paper ‘On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?’ coming out of Google and the University of Washington has gotten much attention in the wider field as it led to the firing of Timnit Gebru as co-lead of the Ethical AI team from Google leaving both room for speculations and sparking a discussion on the future of AI ethics research in private companies.
As one of the main contributing institutions, Carnegie Mellon University is proud to present 10 papers and one tutorial at this year’s conference. Contributions are made from all across campus with authors from the Machine Learning Department, the Department of Statistics and Data Science, the Institute for Software Research, the Computer Science Department, Heinz College of Public Policy, and the Philosophy Department. Several of the studies focus on auditing existing systems in the context of predictive policing [4], image representations learned in an unsupervised manner [5], or the use of mobility data for Covid-19 policy [6]. Others propose new algorithmic solutions to analyze the allocation of opportunities for intergenerational mobility [1], post-process predictions in risk assessment [2], examine the equity of cash bail decisions [3], or understand the fairness implications of leave-one-out training data [8]. The authors of [7] focus on disparity amplification avoidance under different world views and fairness notions, while [9] introduce Value Cards, an educational toolkit for teaching the societal impacts of machine learning. Finally, the authors of [10] provide counternarratives on data sharing in Africa using a storytelling approach based on a series of interviews. We give a short description of each of the papers along with the session times at the conference and links to the preprints below.
Papers
[1] Allocating Opportunities in a Dynamic Model of Intergenerational Mobility
Hoda Heidari (Carnegie Mellon University), Jon Kleinberg (Cornell University)
Session: March 8, 22:00 – 23:45 UTC
Tags: Algorithm Development, Fairness
Summary: The authors develop a model for analyzing the allocation of opportunities for intergenerational mobility such as higher education and find that purely payoff-maximizing objectives can still lead to a form of socioeconomic affirmative action in the optimal allocation.
[2] Fairness in Risk Assessment Instruments: Post-Processing to Achieve Counterfactual Equalized Odds
Alan Mishler (Carnegie Mellon University), Edward Kennedy (Carnegie Mellon University), Alexandra Chouldechova (Carnegie Mellon University)
Session: March 10, 20:00 – 21:30 UTC
Tags: Algorithm Development, Causality, Evaluation, Fairness
Summary: The authors develop a method to post-process existing binary predictors used in risk assessment, e.g. for recidivism prediction, to satisfy approximate counterfactual equalized odds. They discuss the convergence rate to an optimal fair predictor and propose doubly robust estimation of the risk and fairness properties of a fixed post-processed predictor.
[3] A Bayesian Model of Cash Bail Decisions
Joshua Williams (Carnegie Mellon University), Zico Kolter (Carnegie Mellon University)
Session: March 8, 20 – 21:45 UTC
Tags: Algorithm Development, Data, Fairness, Law & Policy
Summary: The authors create a hierarchical Bayesian model of cash bail assignments to analyze fairness between racial groups while overcoming the problem of infra-marginality. Results on 50 judges uniformly show that they are more likely to assign cash bail to black defendants than to white defendants given the same likelihood of skipping a court appearance.
[4] The effect of differential victim crime reporting on predictive policing systems
Nil-Jana Akpinar (Carnegie Mellon University), Maria De-Arteaga (University of Texas at Austin), Alexandra Chouldechova (Carnegie Mellon University)
Session: March 8, 20:00 – 21:45 UTC
Tags: Auditing, Data, Evaluation
Summary: The authors audit place-based predictive policing algorithms trained on victim crime reporting data and find that geographical bias arises when victim crime reporting rates vary within a city. This result requires no use of arrest data or data from police initiated contact.
[5] Image Representations Learned With Unsupervised Pre-Training Contain Human-like Biases
Ryan Steed (Carnegie Mellon University), Aylin Caliskan (George Washington University)
Session: March 8, 12:00 – 13:45 UTC
Tags: Computer Vision, Data, Evaluation, Fairness, Humanistic Theory & Critique
Summary: The authors develop a method for quantifying biased associations between representations of social concepts and attributes in images using image representations learned in an unsupervised manner. The results closely match hypotheses about intersectional bias from social psychology and suggest that machine learning models can automatically learn bias from the way people are stereotypically portrayed on the web.
[6] Leveraging Administrative Data for Bias Audits: Assessing Disparate Coverage with Mobility Data for COVID-19 Policy
Amanda Coston (Carnegie Mellon University), Neel Guha (Stanford University), Derek Ouyang (Stanford University), Lisa Lu (Stanford University), Alexandra Chouldechova (Carnegie Mellon University), Daniel E. Ho (Stanford University)
Session: March 9, 14:00 – 15:45 UTC
Tags: Auditing, Data, Evaluation
Summary: The authors audit the use of smartphone-based mobility data for COVID-19 policy by leveraging administrative voter roll data in the absence of demographic information. Their results suggest that older and non-white voters are less liekely to be captured by mobility data which can disproportionally harm these groups if allocation of public health resources is based on such data sets.
[7] Avoiding Disparity Amplification under Different Worldviews
Samuel Yeom (Carnegie Mellon University), Michael Carl Tschantz (International Computer Science Institute)
Session: Match 10, 14:00 – 15:45 UTC
Tags: Data, Evaluation, Metrics
Summary: The authors mathematically compare competing definitions of group-level fairness and their properties under various worldviews which are assumptions about how, if at all, the observed data is biased. They discuss the criterion of disparity amplification and introduce a new world view with a corresponding notion of fairness as a more realistic perspective.
[8] Leave-one-out Unfairness
Emily Black (Carnegie Mellon University), Matt Fredrikson (Carnegie Mellon University)
Session: March 9, 22:00 – 23:45 UTC
Tags: Algorithm Development, Data, Evaluation, Fairness, Metrics
Summary: The authors introduce leave-one-out unfairness which focuses on the change of prediction for an individual due to inclusion or exclusion of a single other individual from the training data. They discuss the relation of this concept to robustness, memorization and individual fairness in deep models.
[9] Value Cards: An Educational Toolkit for Teaching Social Impacts of Machine Learning through Deliberation
Hong Shen (Carnegie Mellon University), Wesley Deng (UC Berkeley), Aditi Chattopadhyay (Carnegie Mellon University), Steven Wu (Carnegie Mellon University), Xu Wang (University of Michigan), Haiyi Zhu (Carnegie Mellon University)
Session: March 8, 22:00 – 23:45 UTC
Tags: Accountability, Education, Human Factors
Summary: The authors introduce Value Cards, an educational toolkit with topics related to Fairness, Accountability, and Ethics, and present an early use of the approach in a college-level computer science course. Results suggest that the use of the toolkit can improve students’ understanding of both technical definitions and trade-offs of performance metrics and apply them in real-world contexts.
[10] Narratives and Counternarratives on Data Sharing in Africa
Rediet Abebe (UC Berkeley), Kehinde Aruleba (University of Witwatersrand), Abeba Birhane (University College Dublin), Sara Kingsley (Carnegie Mellon University), George Obaido (University of Witwatersrand), Sekou L. Remy (IBM Research Africa), Swathi Sadagopan (Deloitte)
Session: March 9, 12:00 – 13:50 UTC
Tags: Data, Ethics, Humanistic Theory & Critique
Summary: The authors use storytelling via fictional personas built from a series of interviews with African data experts to complicate dominant narratives and provide counternarratives on data sharing in Africa. They discuss issues arising from power imbalances and Western-centric policies in the context of open data initiatives centered around data extracted from African communities and discuss avenues for addressing these issues.
Tutorials
Sociocultural diversity in machine learning: Lessons from philosophy, psychology, and organizational science
Sina Fazelpour (Carnegie Mellon University) and Maria De-Arteaga (University of Texas at Austin)
Session: March 4, 14:00 – 15:30 UTC
Summary: The current discussion of sociocultural diversity in machine learning research leaves a gap between the conversation about measures and benefits and the philosophical, psychological and organizational research on the underlying concepts. This tutorial addresses the concepts and consequences of sociocultural diversity and situates this understanding and its implications for the discussion of sociocultural diversity in machine learning.