DASH searches for the optimal kernel size and dilation rate efficiently from a large set of options for each convolutional layer in a CNN backbone. The resulting model can achieve task-specific feature extraction and work as well as hand-designed expert architectures, making DASH an effective tool for tackling diverse tasks beyond well-researched domains like vision.
The past decade has witnessed the success of machine learning (ML) in solving diverse real-world problems, from facial recognition and machine translation to disease diagnosis and protein sequence prediction. However, progress in such areas has involved painstaking manual effort in designing and training task-specific neural networks, leveraging human and computational resources that most practitioners do not have access to.
In contrast to this task-specific approach, general-purpose models such as DeepMind’s Perceiver IO and Gato and Google’s Pathway have been developed to solve more than one task at once. However, as these proprietary pretrained models are not publicly available, practitioners cannot even assess whether fine-tuning one of these models would work on their task of interest. Independently developing a general-purpose model from scratch is also infeasible due to the massive amount of compute and training data it requires.
A more accessible alternative is the field of automated machine learning (AutoML), which aims to obtain high-quality models for diverse tasks with minimal human effort and computational resources, as noted in a recent blogpost. In particular, we can use Neural Architecture Search (NAS) to automate the design of neural networks for different learning problems. Indeed, compared with training large-scale transformer-based general-purpose models, many efficient NAS algorithms such as DARTS can be run on a single GPU and take a few hours to complete a simple task. However, while NAS has enabled fast and effective model development in well-studied areas such as computer vision, its application to domains beyond vision remains largely unexplored. In fact, a major difficulty in applying NAS to more diverse problems is the trade-off between considering a sufficiently expressive set of neural networks and being able to efficiently search over this set. In this blog post, we will introduce our approach to find a suitable balance between expressivity and efficiency in NAS.
In our upcoming NeurIPS 2022 paper, we developed a NAS method called DASH that generates and trains task-specific convolutional neural networks (CNNs) with high prediction accuracy. Our core hypothesis is that for a broad set of problems (especially those with non-vision inputs such as audio and protein sequences), simply searching for the right kernel sizes and dilation rates for the convolutional layers in a CNN can achieve high-quality feature extraction and yield models competitive to expert-designed ones. We explicitly focus on extending the generalization ability of CNNs due to the well known effectiveness of convolutions as feature extractors, coupled with recent work demonstrating the success of modern CNNs on a variety of tasks (e.g., the state-of-the-art performance of the ConvNeXt model that incorporates many techniques used by Transformers).
While a search space of diverse kernels is easy to define, searching it efficiently is challenging because we want to consider many kernels with different kernel sizes and dilation rates, which results in a combinatorial explosion of possible architectures. To address this issue, we introduce three techniques exploiting the mathematical properties of convolution and fast matrix multiplication on GPUs. We evaluate DASH on 10 different tasks spanning multiple domains (vision, audio, electrocardiogram, music, protein, genomics, cosmic-ray, and mathematics), input dimensions (1D and 2D), and prediction types (point and dense). While searching up to 10x faster than existing NAS techniques, DASH achieves the lowest error rates among all NAS baselines on 7/10 tasks and all hand-crafted expert models on 7/10 tasks.
In the following, we will first discuss how DASH is inspired by and differs from existing NAS work. Then, we will introduce three novel “tricks” that improve the efficiency of searching over a diverse kernel space. Finally, we will present the empirical evaluation to demonstrate DASH’s effectiveness.
The Expressivity-Efficiency Trade-Off in NAS
Most NAS methods have two components for generating task-specific models: a search space that defines all candidate networks and a search algorithm that explores the search space until a final model is found. Effective models for arbitrary new tasks can be developed if and only if the search space is sufficiently expressive, but this also means we need more time to explore the set of possible architectures in the space.
This tension between search space expressivity and search algorithm efficiency has been prominent in NAS research. On one hand, vision-centric approaches like DARTS are designed to explore multiple architectures quickly, but the search spaces are limited to models with (inverted) residual blocks, and are thus highly tailored to vision tasks. On the other hand, new approaches like AutoML-Zero and XD aim to solve arbitrary tasks by considering highly expressive search spaces, but the associated search algorithms are often practically intractable. For instance, XD tries to substitute layers in existing networks with matrix transformations. The matrix search space is continuous and expansive, but optimizing it is extremely time-consuming even for simple benchmarking tasks like CIFAR-100, rendering XD impractical for diverse tasks with more data points or larger input dimensions.
To bridge this gap, we present DASH, which fixes a CNN as the backbone and searches for the optimal kernel configurations. The intuition is that modern convolutional models like ConvNeXt and Conv-Mixer are powerful enough to compete with attention-based architectures, and varying kernel sizes and dilations can further strengthen the feature extraction process for different problems. For instance, small filters are generally used for visual tasks to detect low-level features such as edges and corners, whereas large kernels are typically more effective for sequence tasks to model long-range dependencies. Unlike conventional cell-based NAS which searches for a block of operations and stacks several copies of the same block together, DASH is more flexible as it decouples layer operations from the network structure: since the searched operators can vary from the beginning to the end of a network, features at different granularities can be processed differently.
“Kernel Tricks” for Improving NAS Efficiency
As mentioned above, we seek a sufficiently expressive (i.e., large) kernel search space to ensure that there exist kernels that can effectively extract features for a diverse set of tasks. To achieve this, we replace each convolutional layer in the backbone network with the following aggregated convolution operator:
$$S_{\bf AggConv_{K, D}} = \{\bf Conv_{k,d} | k \in K, d\in D\}, \tag{1}\label{1}$$
where \(K\) and \(D\) denote the set of kernel sizes and dilations that we consider, respectively. A naive approach to searching over this kernel space is to use the continuous relaxation scheme of DARTS to compute the output (we call this approach mixed-results):
$$\bf AggConv_{K,D} (\mathbf{x}) := \sum_{k\in K}\sum_{d\in D} \alpha_{k,d}\cdot \bf Conv(\mathbf{w}_{k,d})(\mathbf{x}), \tag{2}\label{2}$$
where \(\mathbf{w}_{k,d}\) are the kernel weights and \(\alpha_{k, d}\) are the architecture parameters. However, DARTS only considers a few kernels with small sizes and dilations (with \(k_{\max}\)=5, \(d_{\max}\)=2, and thus small \(|K||D|\)), whereas we aim to search over many and large kernels (e.g., with \(k_{\max}\)=11, \(d_{\max}\)=127, and large \(|K||D|\)). This increased expressivity leads to drastically higher search costs for naive search, whose runtime complexity is \(O(n|K||D|)\), where \(n\) is the input size.
In the following, we will describe three techniques—kernel-mixing, Fourier convolution, and Kronecker dilation—that DASH collectively employs to enable efficient search. Complexity-wise, DASH’s efficient search replaces the \(O(n|K||D|)\) complexity of naive search with an \(O(n\log n)\) complexity, where \(\log n\) is small for any realistic \(n\), including long sequence inputs. Empirically, this latter complexity translates to significantly improved search speed, e.g., DASH searches about 10 times faster than DARTS for the large \(|K||D|\) regime (Figure 1).
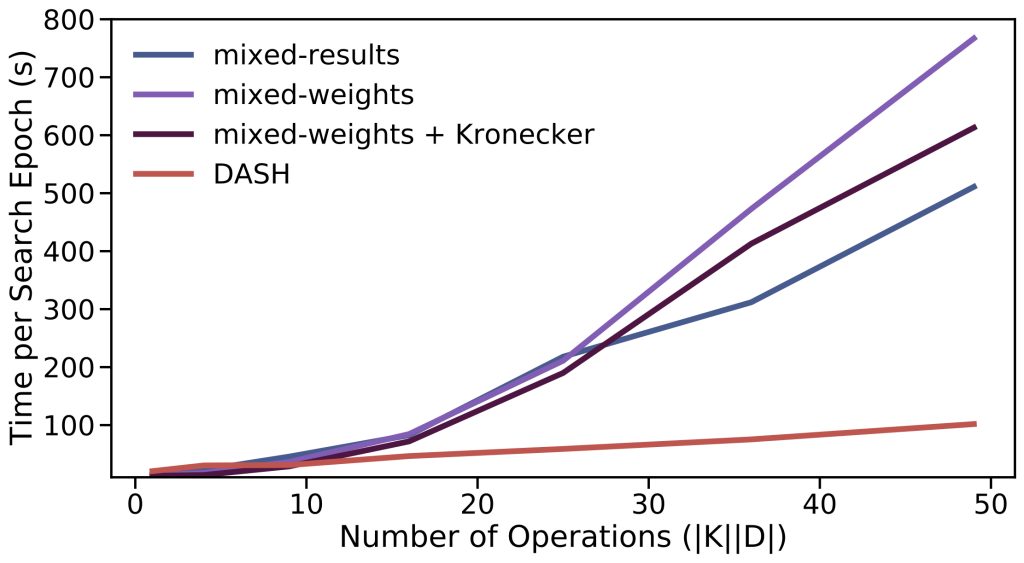 Figure 1. Combined forward- and backward-pass time for one search epoch vs. the search space size for 1D input with \(n = 1000\). We vary the search space by letting \(K = \{2p+1 | 1\leq p \leq c\}\), \(D = \{2^q-1 | 1\leq q\leq c\}\) and increasing \(c\) from 1 to 7. As the aggregated kernel size \(\bar{D}\) increases, the DASH curves grow much slower than the other methods.
Figure 1. Combined forward- and backward-pass time for one search epoch vs. the search space size for 1D input with \(n = 1000\). We vary the search space by letting \(K = \{2p+1 | 1\leq p \leq c\}\), \(D = \{2^q-1 | 1\leq q\leq c\}\) and increasing \(c\) from 1 to 7. As the aggregated kernel size \(\bar{D}\) increases, the DASH curves grow much slower than the other methods.Technique 1: Mixed-Weights. We first observe that all computations in Equation 2 are linear, so the distributive law applies. Hence, instead of computing \(|K||D|\) convolutions, we can combine the kernels and compute convolution once:
$$\bf AggConv_{K, D}(\mathbf{x})=\bf Conv\left(\sum_{k\in K}\sum_{d\in D} \alpha_{k, d}\cdot\mathbf{w}_{k,d}\right)(\mathbf{x}). \tag{3}\label{3}$$
Let’s call this approach mixed-weights. Mixed-weights allows the search complexity to depend on the aggregated kernel size \(\bar{D} := \max (k − 1)d + 1\) rather than \(|K||D|\), but the former still scales with search space. Can we do better than this?
Technique 2: Fourier Convolution. Imagine that \(x\) is an image input. Then, Equation 3 operates on the pixel values in the spatial domain. Alternatively, one can work with the rate of change of the pixel values in the frequency domain to compute the convolution output more efficiently, taking advantage of the celebrated convolution theorem:
$$\bf AggConv_{K,D}(\mathbf{x})= \mathbf{F}^{-1}\bf diag\left(\mathbf{F}(\sum_{k\in K}\sum_{d\in D} \alpha_{k,d}\cdot \mathbf{w}_{k,d})\right)\mathbf{F}\mathbf{x}. \tag{4}\label{4}$$
where \(\mathbf{F}\) represents the discrete Fourier transform. Equation 4 allows us to remove the dependence on the combined kernel size \(\bar{D}\), as \(\mathbf{F}\) can be applied in time \(O(n \log n)\) using the Fast Fourier Transform.
Technique 3: Kronecker Dilation. Lastly, we focus on accelerating search in a subset of the search space where the kernel size \(k\) is fixed and the dilation rate \(d\) varies. To dilate a kernel before applying it to the input, we need to insert \(d-1\) zeros between the adjacent elements in the weight matrix. An efficient implementation on GPUs exploits the Kronecker product \(\otimes\). For example, in 2D, we can introduce a sparse pattern matrix \(P \in \mathbb{R}^{d\times d}\) whose entries are all \(0\)’s except for the upper-left entry \(P_{1,1} = 1\). Then, \(\mathbf{w}_{k,d} = \mathbf{w}_{k,1}\ \otimes P\). After dilating the kernels, we can proceed by following Equation 4.
Empirical Results on NAS-Bench-360
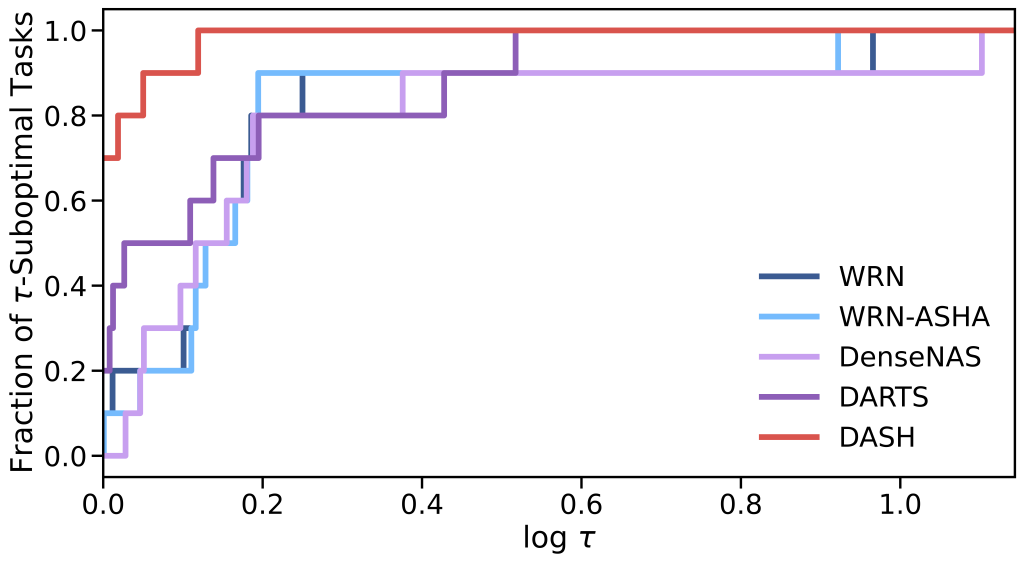 Figure 2. We use performance profiles to measure the aggregate performance of DASH and other NAS methods (higher is better). Each profile is a curve corresponding to a single method and plots the fraction of tasks on which that method is a multiplicative factor \(\tau\) worse than the best method, where \(\tau\) is the domain variable between 1 and infinity. DASH being far in the top left corner indicates it is rarely suboptimal and is often the best.
Figure 2. We use performance profiles to measure the aggregate performance of DASH and other NAS methods (higher is better). Each profile is a curve corresponding to a single method and plots the fraction of tasks on which that method is a multiplicative factor \(\tau\) worse than the best method, where \(\tau\) is the domain variable between 1 and infinity. DASH being far in the top left corner indicates it is rarely suboptimal and is often the best.To verify that DASH finds a balance between expressivity and efficiency, we evaluate its performance with the Wide ResNet backbone on ten diverse tasks from NAS-Bench-360. We present the performance profile (a technique for comparing different methods while revealing both ranking and absolute performance characteristics) for DASH and the NAS baselines in Figure 2. The exact accuracy metrics can be found in our paper. We highlight the following observations:
- DASH ranks first among all NAS baselines (and outperforms DARTS) on 7/10 tasks. It also dominates traditional non-DL approaches such as Auto-Sklearn and general-purpose models such as Perceiver IO.
- DASH outperforms hand-crafted expert models on 7/10 tasks. While the degree of sophistication of the expert networks varies task by task, the performance of DASH on tasks such as Darcy Flow suggests that it is capable of competing with highly specialized networks, e.g., Fourier Neural Operator for PDE solving. This implies that equipping backbone networks with task-specific kernels is a promising approach for model development in new domains.
- Speedwise, DASH is consistently faster than DARTS, and its search process often takes only a fraction of the time needed to train the backbone. Figure 3 visualizes the trade-off between efficiency and effectiveness for each method-task combination. Evidently, DASH is both faster and more effective than most NAS methods on the tasks we considered.
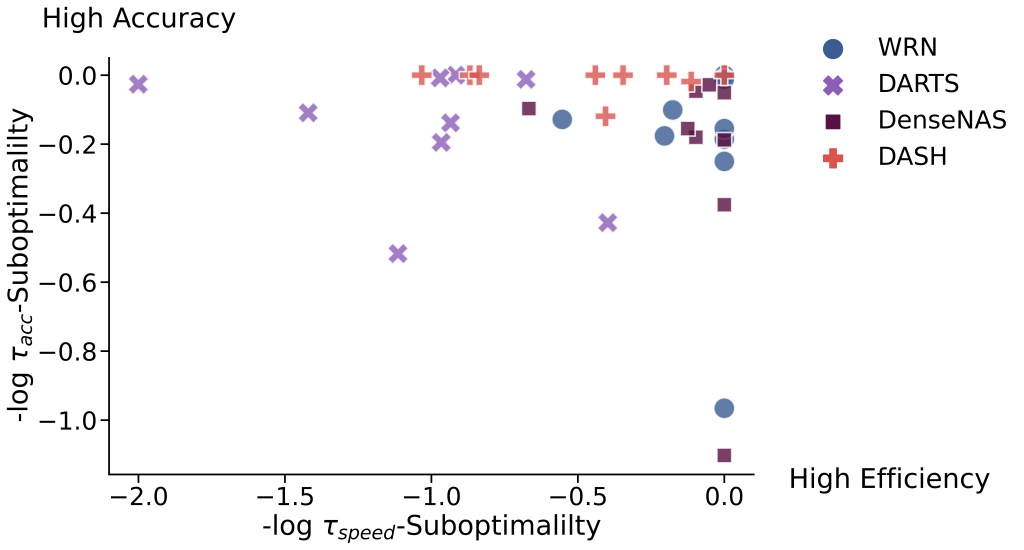 Figure 3. Comparing -\(\log\tau\)-suboptimality of speed vs. accuracy on all tasks. DASH’s concentration in the top right corner indicates its strong efficacy-efficiency trade-offs relative to the other methods.
Figure 3. Comparing -\(\log\tau\)-suboptimality of speed vs. accuracy on all tasks. DASH’s concentration in the top right corner indicates its strong efficacy-efficiency trade-offs relative to the other methods.In addition to the Wide ResNet backbone and NAS-Bench-360 tasks, we have also verified the efficacy of DASH on other backbones including TCN and ConvNeXt, and on large-scale datasets including ImageNet. In particular, DASH is able to achieve a 1.5% increase in top-1 accuracy for ImageNet-1K on top of the ConvNeXt backbone (note that ConvNeXt itself was developed in part via manual tuning of the kernel size). These results provide further support that DASH is backbone-agnostic, and it can be used to augment modern architectures with task-specific kernels to solve diverse problems effectively and efficiently.
Discussion and Takeaways
In this blogpost, we argue that a crucial goal of AutoML is to discover effective models for solving diverse learning problems that we may encounter in reality. To this end, we propose DASH, which efficiently searches for task-specific kernel patterns and integrates them into existing convolutional backbones. Please see our paper and codebase to learn more about DASH or try it out on your own tasks and backbones.
While DASH makes progress in obtaining high-quality models by finding a suitable balance between expressivity and efficiency in NAS, we view it as an early step as part of the broader challenge of AutoML for diverse tasks. Thus, we would like to highlight and encourage participation in the ongoing AutoML Decathlon competition at NeurIPS 2022. At the moment, we are working on implementing DASH as one of the baselines for the competition. Meanwhile, we hope to see more automated and practical methods developed for tackling diverse tasks in the future.