Figure 1. Three regimes of exploration: Current RL model can explore via: (1) sharpening: simply increases likelihood on traces it can sample with high probability; (2) chaining: chain asymmetric skills in the base model (e.g., verification-generation gap, abstraction-generation gap); (3) guided: use guidance from offline data (e.g., human-written solutions) to discover solutions to very hard problems that any amount of sampling or chaining can’t solve. Our proposed approach for exploration that scales RL training on hard problems operates in the guided regime.
In 2025 alone, we went from the first release of the DeepSeek-R1 technical report, to the first open-source replications of reinforcement learning (RL) training with long chains of thought, to skepticism that RL merely “sharpens” whatever the pre-trained model already knows, to realization that “RL actually works”. A natural question that follows is whether we can continue to scale compute or experience and expect RL to keep improving. Unfortunately, for current RL methods, the answer is no; results show that current RL training recipes often plateau without maximizing reward fully since several “hard” problems in the training dataset remain unsolved. In principle, a scalable training recipe should lead to continued progress on the training data as more compute is used, but these plateaus show that this does not occur. Although such saturation has not prevented models from achieving good performance on current evaluation benchmarks, it raises serious concerns about whether existing RL methods can continue to scale to increasingly harder test scenarios and whether or not they are capable of autonomously discovering solutions to unsolved problems.
Addressing Exploration is Crucial for RL Scaling
In this blog, we aim to give some perspective on the question of scaling RL compute on hard problems. Current RL recipes run into a fundamental challenge of exploration on hard problems. By exploration, we mean the approach required to discover at least one correct solution for a given problem so that the RL training algorithm can now learn from this trace. The dominant exploration strategy today is fully on-policy, meaning that the model samples many rollouts itself during RL training. However, on many difficult prompts, this strategy fails to produce even a single correct rollout at any point over the course of training, which means that no useful learning signal is ever obtained. The inability to train on hard training problems then brings into question the model’s generalization on similar test problems.
This post focuses on addressing this very obstacle: on-policy RL cannot learn from prompts for which the model’s generated traces receive zero reward. We first describe how classical exploration methods, such as exploration bonuses (see this cool paper), are not sufficient in the LLM setting and often lead to optimization pathologies. We then show how a more ”proactive” approach based on conditioning on offline data from privileged sources can overcome this exploration bottleneck and enable RL to scale more effectively on hard problems.
Three Regimes of Exploration: Sharpening, Chaining and Guided Exploration
Broadly speaking, irrespective of any explicit method to induce exploration (like reward bonus), on-policy RL training for LLMs operates in three regimes. The first regime is when RL sharpens, meaning that RL simply hones in on the correct trajectories (increases their likelihood) the base (pre-trained) model already samples with high probability. This is the regime where we see pure prompt tuning outperforming RL. But then, this means RL is simply making a likely correct trace even more likely, and not discovering solutions for problems it could never sample a correct solution for. Our own earlier work showed that RL can be moved out of this regime into the second regime where RL discovers new solutions, by chaining useful skills (like verification, summarization, etc.) present in the pre-trained model, the combination of which are not as likely to be sampled as a single trace before running RL. This is the regime where RL usually amplifies self-verifications and response length grows over training. The success of exploration in this regime depends on the right base model and appropriate design choices (e.g., curricula with appropriate mixtures of data and token budgets) during training.
Today, many performant RL recipes do exploration that falls into the second regime, relying on on-policy sampling paired with curricula to drive improvement. The pertinent question then is how to drive exploration into a regime where it can discover a learning signal on very hard problems, i.e., problems for which chaining skills that the model already knows via on-policy learning are insufficient to find a successful output trace. In this regime, the model must either chain skills in ways that the base model would almost never produce or generate tokens that are highly unlikely under it. Our approach is a step towards enabling exploration in this third regime, by conditioning on offline data and “guiding” the model toward the behavior needed to solve hard problems, and training it to internalize this behavior. Before describing our approach, we study how classical exploration methods fail to explore on hard problems within the first two regimes.
How Do Classical Exploration Methods Fare With RL on Hard Problems?
To go beyond sharpening or chaining done on-policy, we can look back at the classical deep RL literature for ideas on incentivizing exploration. Many exploration methods are retrospective in nature: they encourage the policy to explore randomly, identify novel behavior, and then reward the policy for producing more of that novelty. A typical instantiation of this type of exploration method is to provide a reward bonus for attaining high entropy over states or actions, or a modification to the RL objective that implicitly incentivizes diversity, such as optimizing pass@k scores rather than direct rewards in the LLM setting. Another option is to explore on-policy, but incentivize more exploration by appropriately setting hyperparameters (e.g., a more generous clipping ratio in PPO). In this section, we benchmark some representative exploration methods when running on-policy RL on hard problems, starting with our base model Qwen3-4B-Instruct, a capable instruction-following model.
Experiment setup. We first curate a set of hard math reasoning problems from DAPO, OmniMath (levels 5-8), and AceReason datasets where the base model fails to produce any successful rollout with large parallel sampling (k=128) and under a large token budget (32k). We then run RL training with additional: 1) a token-level entropy bonus and 2) following DAPO, a more generous importance ratio clipping term in a PPO-style policy gradient update allowing the LLM to explore more aggressively on rare, off-policy rollouts. These two approaches form two popular and representative exploration methods for RL training of LLMs today. Other notions of novelty or dynamics prediction error do not quite transfer from deep RL to LLMs naturally because LLMs for math present a single-step, bandit learning problem.
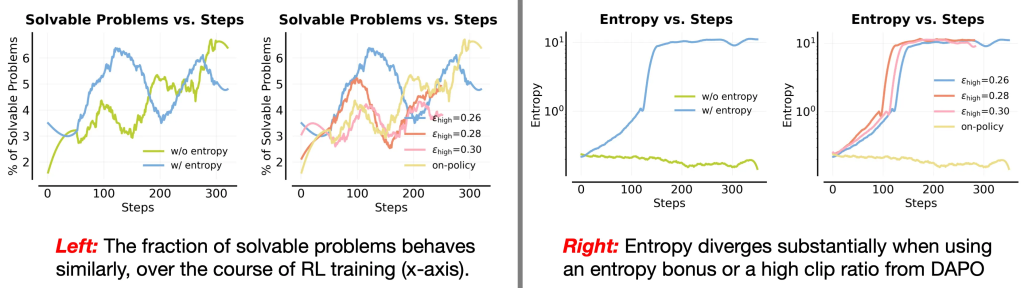
Figure 2. Left: Evolution of the fraction of solvable problems through the RL run (measured via the pass@8 at 16k output length). Right: average token-level entropy statistics through the RL run. Observe that all of these representative classical exploration methods make similar amounts of (few) problems solvable, while creating pathologies in optimization in the sense that entropy blows up. We do notice large sensitivity to the clip threshold epshigh in our runs.
Empirical findings. Observe in Figure 2 that incorporating an entropy bonus or utilizing a larger clip ratio epshigh both increase the average token-level entropy of the trained model to substantially large values. An alternative is to run on-policy training with no entropy bonus at all (shown by the light green line). All of these approaches end up solving a similar number of problems, with no clear signs of improved solvability of the harder problems (as in no signs of “improved” exploration). The addition of these bonuses simply makes optimization pathological.
Takeaway (classical exploration): Classical exploration methods (entropy bonus, generous clipping in PPO) are not effective for training LLMs on hard problems as they often destabilize RL optimization and stability (entropy explodes massively).
Exploration via Transfer from Easy Problems Runs Into Interference
An alternative to classical exploration bonuses is to leverage reasoning behaviors or strategies learned on easier problems at smaller output lengths as building blocks that can be chained to solve harder problems, given a larger token budget. We referred to this idea as extrapolation: if training on easier problems produces a model that can use more tokens to solve harder ones through chaining, then on-policy RL can amplify this effect and no special exploration techniques may be needed. Our prior work, e3, explored this idea by building a curriculum over problem difficulty during training. This curriculum would improve performance on hard problems only when extrapolating the model trained on easy problems at shorter lengths could provide performance gains on the hard problem set at a larger output length.
However, this condition does not apply to our hard prompt set, where pass@k is equal to zero at an output length of 32k tokens. Thus, to stress test if any form of transfer is possible, we decided to co-train on a mixture of easy and hard problems using on-policy RL in hopes that any progress on easy problems during RL training may transfer to improvements on hard problems. As shown in Figure 3 below, we find no substantial transfer to hard problems (compare “hard” vs “hard + easy” in Figure 3). The model’s pass@k rate (solvability) on the hard training set of problems increases faster with easy problems are mixed, but still plateaus at a lower asymptote value than the performance obtained by training on the hard set only (”hard”). This means learning on arbitrary easy problems do not transfer the exploration capabilities needed for hard ones. In contrast, our approach of guided exploration (”hard + guide”) that we will discuss later in this post improves solvability (pass@8) by ~13% more in Figure 3 compared to these approaches. A similar trend appears when slightly easier problems are mixed in for RL training (“hard + easier”) in Figure 3 — in fact, this run is able to solvable even fewer problems than “hard + easy” during training.

Figure 3. Left: evolution of the fraction of solvable problems (measured via pass@8 at 16k token lengths). Middle: average training reward on the easy subset mixed into training. Right: average token-level entropy over the course of RL training. Since we do not use an entropy bonus, entropy generally remains stable (or slightly decreases) throughout training. Observe that the fraction of solvable problems increases the most when using our guidance-based approach. In contrast, adding easy or easier data does not improve solvability on hard problems, providing a negative result for the transfer hypothesis for improving exploration on hard problems.
In fact, we also evaluate the pass@32 scores of these checkpoints at a larger output length of 32k tokens (Figure 6) and find a trend, where mixing in easy problems makes pass@32 at this larger length “plateau” more prematurely compared to training on hard problems alone. All of this evidence suggests not only there is largely no transfer of behavior from easy to hard problems, but training on mixtures of easy and hard problems also runs into some form of “interference” across prompts. In multi-task deep RL, this phenomenon is often called ray interference.
Elaborate discussion on interference. In multi-task RL, ray interference arises when RL updates from “rich” tasks (i.e., in our case, this would be easy problems where rewards are easy to attain) dominate those from “poor” tasks (i.e., hard problems, where rewards are hard to attain), causing the model to improve only on the tasks it can already solve. When ray interference becomes excessive, on-policy RL plateaus, indeed justifying the connotation “a source of plateaus in deep RL” by Schaul et al. 2019. In LLMs, results on population-level pass@k dropping below the base model at large ( k) values indicate the presence of ray interference: optimizing reward on some easier problems in a heterogeneous dataset mixture impairs the model from sampling any correct rollout on the hard set beyond the rollout budget. And this is precisely also why optimizing the per-problem pass@k score also does not solve the exploration challenge of learning on hard problems, since per-problem pass@k does not address interference of updates across prompts. It simply shapes reward for problems the model can already solve!
Takeaway (exploration via transfer): Transfer from easy problems alone cannot drive exploration on very hard problems. As training improves performance on easy problems learning signal is starved on the hard ones, and this hinders the model from exploring discovering solutions to hard problems.
Can we Address Exploration with Off-Policy RL or Warmstart SFT?
As Schaul et al. 2019 show, ray interference is more severe with on-policy RL updates, when training rollouts are sampled by the learner itself. A natural alternative is therefore to move towards off-policy RL, where the model performs RL updates on rollouts generated by a different policy. Off-policy RL (and offline RL) methods work well in classical deep RL. Recent work in LLMs does use offline traces from humans and other models for policy learning. The central idea is to replace self-generated traces in RL with offline traces and rely on importance-sampling corrections to account for the distribution shift between on-policy and offline data. Although appealing in principle, importance ratios in very large action spaces suffer from variance explosion or unbounded bias, which in LLM leads to optimization pathologies such as gradient norm blow-up, entropy blow-up or collapse. Thus stabilizing this class of approaches requires additional tricks that further complicate the method. This makes off-policy policy-gradient methods unsuitable for our purposes of training on hard problems.
A more conventional option is to first warmstart (or “mid-train”) the model via supervised fine-tuning (SFT) on off-policy “expert” traces before switching to on-policy RL. This is analogous to a “behavior cloning (BC) + RL” approach from classical RL, as opposed to running off-policy RL. This warmstart can be effective when we can collect synthetic rollouts that resemble the kind of reasoning traces we want the model to produce (e.g., when distilling from other models). However, it is unclear whether such traces are available for the hardest problems that our best models fail to solve. For these hard problems, the only reliable sources of solution traces are often human-written outputs. Human notes or solutions introduce a substantial “type” mismatch compared to the reasoning traces produced by LLMs, making them far too off-policy. Fine-tuning on such heavily off-policy data to leads to entropy collapse, which prevents the resulting model from improving during subsequent on-policy RL even on easier problems.
We ran a warmstart approach in Figure 4 to test whether exploration on hard problems can be improved by first performing SFT on synthetically generated responses. Specifically, we prompted the base model with a Gemini-generated partial solution, sampled many responses conditioned on this guidance, and filtered them to retain only correct traces that produced the right final answer. We then performed SFT on this filtered data and used the resulting model as the initialization for RL. We find that the fraction of solvable problems during training is worse with this warmstart SFT when compared to our approach and also slightly below the baseline of just training on hard problems without any warmstart. This indicates somewhat of a failure of the SFT+RL approach. Our approach uses offline guidance in a different way, as described next.
Figure 4. Fraction of solvable problems (pass@8) during RL when warm-starting with SFT on a filtered dataset of synthetically generated traces. Observe that SFT initialization leads to worse solvability than our approach and also naive approach of training only on hard problems.
Takeaway (exploration is not solved by training on offline data): While on-policy interference could be in-principle addressed via offline data (e.g., human solutions), directly supervising a policy on offline data often leads to entropy collapse (after warmstart SFT) or explosion in gradient variance (with off-policy policy gradient).
POPE: Privileged On-Policy Exploration
Our approach attempts to learn on hard problems by utilizing offline human solutions not as training targets, but rather to “guide” exploration. We use human data to implement a proactive exploration strategy that uses privileged information. Concretely, we mix in a modified version of the prompt where we augment the original hard prompt with guidance provided by prefixes of the human solution into on-policy RL training. Crucially, in this setup the model never takes gradient updates on the guidance tokens but rather only conditions on guidance to still learn fully on-policy. On these modified “guided” prompts, we employ the following system instruction:
Prompt v1 (Default POPE system instruction)
You are given a problem and a partial solution.
Your task is to carefully study the partial response, identify what reasoning or steps are already provided, and then complete the solution from where it left off. Ensure your response is logically consistent and leads to a complete and correct final answer.
**Important**: Show your reasoning step-by-step, and clearly present the final answer using LaTeX-style `boxed{}` notation.
Problem:
`<Problem>`
Partial Response:
`<Partial Response>`
Continue solving the problem, starting from where the partial response ends. Make sure your final answer is written as: `boxed{your_answer_here}`
The guidance provided by the partial response (<Partial Response>) helps move the model into “better” regions of the response space, from which on-policy exploration becomes feasible. From an RL perspective, we are moving the model into “states” informed by the prefixes of the human-written solution while still ensuring that all learning remains fully on-policy on the hard problem. Once the model begins its own on-policy learning from these guided states, it is far more likely to experience reward and obtain a learning signal. We then run RL on a mixture of default, unguided hard prompts and their guided variants, and optionally mix in easy problems to broaden coverage of the prompt mixture. This approach sidesteps complications associated with importance ratios, while still learning on prefixes from the human solution. We refer to this approach of training on a mixture of hard problems with and without guidance as privileged on-policy exploration (POPE), since it uses privileged information to shape on-policy exploration of the model. A schematic illustration is shown below.
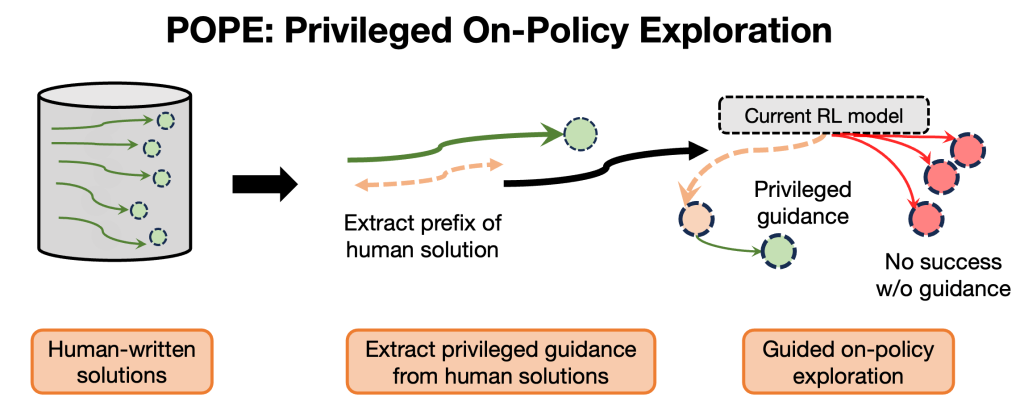
Figure 5. Schematic of privileged on-policy exploration. POPE conducts guided on-policy exploration from prefixes of the human solution for learning on offline data. Concretely POPE trains on a mixture of hard problems and hard problems augmented with a mixture of prefixes of human solutions as privileged guidance. Training starts to gather reward signal on the guided version of the prompt, and this enables the model to solve more unguided prompts .
A key question remaining is whether the reasoning strategies the model learns when solving the guided version of a problem help improve performance on the default, unguided version, which is ultimately what we care about. We find that a meaningful form of “transfer” does occur when using base models with both instruction-following and reasoning capabilities. Clearly this transfer is crucial to strengthen the learning signal on the original problems, not just the guided ones. We expand on this later when we get into: “Why does POPE work?”. Before that though, we describe some performance results for POPE.
How Well Does POPE Work?
We first evaluate the efficacy of POPE during training. As shown in Figure 3 (previous section), the asymptotic training performance obtained with POPE that uses guidance (”hard + guide”) is substantially higher than the asymptote obtained by just training on the hard set alone. This means that training on the guided version of a hard prompt is the first approach in this post to effectively enables transfer onto the unguided prompt. Concretely, in this section, we identified the shortest prefix that yielded a non-zero success rate for the base model per hard problem, and used it as the guidance for POPE. We have since found that the “minimal” prefix is not strictly required for strong performance, but overly revealing prefixes tends to degrade performance.
In addition, as shown in Figure 6 (below), we evaluate checkpoints from the three settings (“hard,” “hard + easy,” and “hard + guide”) using a much larger evaluation budget of 32k tokens (note that our training was performed at 16k tokens) and a higher value of (k = 32) in pass@k. Observe that POPE (”hard + guide”) solves more problems from the hard set compared to any other configuration. While mixing in easy prompts results in a performance plateau on hard problems due to interference, no such performance plateau is observed for “hard + guide”, which continues to improve as more steps of RL training are done.

Figure 6. Pass@32 on the hard problem set evaluated with a 32k token budget. Mixing in easy problems causes a plateau in pass@32 over training, even though pass@32 continues to improve when training only on the hard set. This drop reflects ray interference caused by the easy data. In contrast, incorporating guidance in the form of a human-written prefix improves pass@32 consistently throughout training, indicating that POPE alleviates ray interference to a great degree. Also note that the drop in solvability from adding in easy problems is substantially smaller when guidance is used on hard problems, when compared to mixing in easy problems on the hard set.
We also ran a version of POPE on a dataset that mixes in easy problems in the “hard + guide” setting to be able to mimic training on a broad training mixture, which is commonly the case in practice. We report our results comparing several runs in Table 1. Concretely, we train on a mixture of “hard + guide” and the easy problem set. Despite the presence of easy problems, introducing guidance via POPE greatly reduces this interference effect even though easy problems are still present (compare the gap between “hard” and “hard + easy” vs “hard + guide” and “hard + guide + easy” in Figure 6). Concretely, on the hard set in Table 1, this “hard + guide + easy” approach reaches a pass@1 of 14.3% and pass@16 of 38.9%, which is close to the performance of “hard + guide” (15.5% pass@1 and 42.5% pass@16), and substantially better than mixing in easy problems without guidance.
Table 1. Pass@1 and pass@16 of various models on the hard set and standardized benchmarks (AIME2025 and HMMT2025). Incorporating guidance via POPE (“hard + guide”) substantially improves performance on the hard problems while also improving performance on standardized benchmarks. When easy problems are mixed in, “hard + guide + easy” retains similar performance on the hard set and improves AIME and HMMT scores, since the easy dataset includes problems that are more in-distribution for the AIME and HMMT sets.
| Dataset | HARD | HARD | AIME25 | AIME25 | HMMT25 | HMMT25 |
|---|
| Performance | pass@1 | pass@16 | pass@1 | pass@16 | pass@1 | pass@16 |
| Qwen3-4B-Instruct | 0.57 | 7.42 | 48.13 | 77.29 | 29.06 | 52.99 |
| hard | 13.55 | 32.89 | 49.58 | 81.43 | 31.04 | 63.79 |
| hard + easy | 8.22 | 23.81 | 57.19 | 82.50 | 37.19 | 62.81 |
| hard + guide (POPE) | 15.50 | 42.53 | 53.12 | 82.61 | 37.81 | 67.49 |
| hard + guide + easy (POPE) | 14.32 | 38.93 | 58.75 | 83.87 | 38.12 | 67.15 |
Finally, we also observe that “hard + guide + easy” achieves the strongest overall performance on standardized benchmarks such as AIME 2025 and HMMT 2025 when evaluated with a 32k output token budget. These gains appear in both pass@1 and higher pass@k values; the pass@16 values reported above are computed with 64 rollouts. Together, these results highlight the efficacy of POPE in enabling learning on hard problems while remaining fully compatible with larger, mixed datasets that practitioners might want to use for RL training.
Takeaway (summary of POPE results): By incorporating guidance, POPE improves solvability of hard problems and counters the premature pass@k plateau or interference that arises when easy data is mixed in with hard problems. As a result, it offers a more effective and scalable way to learn on hard problems by leveraging guidance from offline data for exploration.
Why Does POPE Work? Synergy b/w Instruction Following & Reasoning
Finally, we analyze how learning on the guided versions of hard problems improves performance on their unguided counterparts. Since the model is never trained on the guidance tokens themselves, the source of such an improvement is not immediately obvious. Our hypothesis or “mental model” draws on the idea of stitching as the core mechanism.
A mental model. Imagine a simple Markov decision process (MDP) where guidance plays the role of a “teleport” operator that moves the agent to a state from which reward is much easier to obtain via simple on-policy sampling. On-policy RL from this state trains the agent to behave optimally from that point onward. After this training, the main challenge is just to reach a nearby state in the unguided setting. Crucially, searching for a nearby state from the initial state is far easier than searching directly for reward, which corresponds to the unguided version.
Applying this mental model to LLMs. We now hypothesize how to extend this mental model to the LLM setting. A natural notion of state in LLMs is the internal representation of a partial sequence, especially because LLM reasoning traces consist of substantial amounts of redundant information. If the base LLM has a strong instruction-following ability, then guiding it using prefixes of human solutions will reliably “teleport” it into states from which success is more likely since a part of the problem is already solved. On-policy RL can then experience reward signal to optimize the next-token distribution from these states onward.
The remaining question is how to reach similar states when no guidance is provided. Here, the reasoning capabilities of long chain-of-thought models become important. These models tend to self-verify, revisit earlier steps, and backtrack when needed. When a model’s reasoning trace includes backtracking or revision behaviors on the guided prompt, it naturally expands coverage over states closer to the initialization (the problem), and thereby learns to collect higher rewards from those nearby states. In fact, there are cases where reasoning models might backtrack all the way to the initial state and reattempt the problem itself!
What all of this means is that RL training now starts to observe reward not just from the state that the LLM was initially “teleported” to with the use of guidance, but also at several other states closer to the initialization. Now, the goal of on-policy RL on the unguided prompt is substantially simpler: it only needs to reach one of these nearby states that a guided rollout already visited and succeeded from, and stitch this behavior with the optimal one that was learned to complete the guidance. As a result, the model becomes more likely to find complete traces that can attain reward without the guidance.
Of course, this mental model greatly simplifies the setup, but we have found it to be a useful guiding principle to explain our results. Next we test this mental model by making interventional edits to our system instruction to see whether this overlap hypothesis helps explain the efficacy of POPE in improving performance on the unguided hard prompts.
Experimental setup. We modify the system instruction (see “Prompt v2” below) so that the model continues solving the problem starting after the partial solution, but without restating or recomputing any part of that partial guidance. This instruction discourages the model from revisiting states near the initialization, thereby reducing the overlap between the early-state distributions of guided and unguided rollouts. Under this setup, guided rollouts are allowed to explore only states beyond the information contained in the guidance. In contrast, the unguided version still needs to compute intermediate information on its own in order to benefit from any state overlap with the guided rollout. Hence, we would expect this system instruction to create a more challenging stitching scenario, thereby hindering transfer to unguided counterparts. We apply this system instruction in the “hard + guide” setting, keeping all other settings identical.
Prompt v2 (continue w/o restate)
You are given a problem and a partial solution. Your task is to infer what reasoning has already been completed and continue solving the problem **without repeating, paraphrasing, or referencing any part of the partial response**.
You must NOT restate earlier steps, summarize them, or quote them in any form. Begin directly from the next logical step that has not yet been completed.
**Important: Use the information from the partial response silently — do NOT copy, rephrase, or explicitly mention anything from it. Your continuation must be logically consistent with what has already been done. Show your reasoning step-by-step (only the new reasoning steps you add), and present the final answer using LaTeX-style \boxed{{}} notation.
Problem:
`<Problem>`
Partial Response:
`<Partial Response>`
Continue solving the problem from the *next new step*, without restating or referring to anything that appears above. Make sure your final answer is written as: `boxed{{your_answer_here}}`
As expected, we observe in Figure 7, that this modified system instruction (continue w/o restate) achieves a lower pass@32 score on the unguided prompt. On the other hand, it does actually solve more problems when guidance is given. In short, it tilts the balance between solving unguided and guided versions of the hard problems from the default version of POPE towards solving more guided prompts and less unguided prompts. This result provides some evidence in favor of the “stitching” mental model, and the utility of instruction following in enabling transfer in POPE.
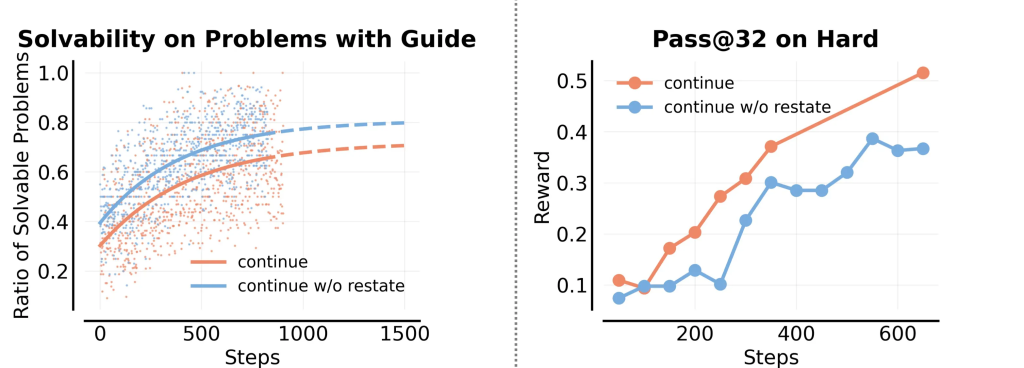
Figure 7. Left: solvability (pass@8) and Right: pass@32 scores on the guided and unguided versions of the hard prompt. The system instruction that forces the model to continue without restating or revisiting information in the guidance solves more problems with guidance, presumably because it simplifies the RL problem conditioned on the guidance. However, this instruction also achieves a worse pass@32 score on the unguided version of the hard problem, indicating reduced transfer from guided to unguided settings, supporting our mental model.
Finally, to understand whether overlap between the initial states of guided and unguided rollouts is essential for success, we qualitatively evaluated model outputs on several problems in the hard set using models trained with our original system instruction and with the revised instruction (“Prompt v2,” which continues without restating or recomputing the guidance). As shown in Table 2, for one representative problem, the unguided solution produced under the original system instruction reflects several aspects of the guidance, indicating that the model is stitching its reasoning back to states encountered during guided exploration. In contrast, with “Prompt v2,” the model’s unguided solution no longer resembles the guided trace and instead follows a distinct solution path, exhibiting minimal use of concepts appearing in the guidance. This suggests that learning under “Prompt v2” does not effectively stitch or bootstrap from the guided states, and the model instead learns to derive its own independent sequence of steps. A comparison is included in the summary linked here: https://chatgpt.com/share/6926a9e8-c270-8004-89f7-c49d6ee67c80.
Table 2. Comparison of unguided solutions produced by models trained with the default system instruction (Prompt v1) and the modified instruction (Prompt v2) in the “hard + guide” setting. Rollouts from the Prompt v1 model replicate several aspects of the guidance, indicating successful transfer. In contrast, rollouts from the Prompt v2 model show almost no resemblance to the guidance, suggesting that this instruction suppresses the stitching effect.
| Criterion | Solution from model trained with Default (Prompt V1) | Solution from model trained with Prompt V2 |
|---|
| Uses inequality structure | ✔ Yes | ✔ Yes |
| Uses cyclic indexing | ✔ Conceptually | ✘ Nominal only |
| Uses “λ = max S” idea | ✔ Yes | ✘ Weak |
| Follows partial response | ⚠ Extremal patterns | ✘ Not at all |
Uses geometric sequence
(a_i = x^{i-1}) | ✘ No | ✘ No |
| Extremal constructions | ✔ Yes (patterns, ratios) | ✘ No |
| Uses (n ge 4k) | ⚠ Light use | ✘ Mention only |
| Depth of reasoning | Medium | Low |
| Is it a true continuation of the partial response? | ⚠ Partial | ✘ No |
An RL Perspective on POPE vs Warmstart SFT & Off-Policy Policy Gradient
From an RL perspective, training via on-policy RL at offline states (Figure 3) has been at the core of several effective RL algorithms that use “SAC-style” policy extraction. In fact, our prior work shows that learning using on-policy actions at offline states (via re-parameterized policy gradient) is more effective than learning on offline actions at offline states via advantage-weighted regression (AWR). We expect this gap to be even larger when the action space is very large, as it is for LLMs where each action corresponds to several tokens in a partial solution. In such settings, any method that depends on using the specific “action” tokens appearing in offline trajectories is likely to provide limited benefit and is generally more cumbersome than an approach that performs on-policy exploration starting from offline states.
Discussion and Future Perspectives
In this blog post, we examined methods for improving exploration in RL to boost performance on hard problems. We showed that several representative exploration techniques inspired from counterparts in classical deep RL, such as entropy bonuses or DAPO-style relaxations, do not improve solvability on hard problems and instead introduce optimization pathologies. This perhaps implies that studying exploration in a regime not plagued by optimization pathologies is critical. Although using offline data seems like a natural solution, directly incorporating such data into policy gradients or using it for a warmstart SFT procedure also leads to collapse. Our approach sidesteps these issues by performing guided exploration, in which we reset the model to prefixes of human solutions and let it perform its own on-policy exploration. Learning under this guidance improves performance even on the original, unguided prompts. Related ideas involving resets to off-policy states have appeared in earlier LLM work, but their usefulness on truly hard problems has not been identified. Much of the recent open-source RL literature has focused on improving on-policy RL for reasoning models, yet our results show that this is rarely sufficient. This blog post is based on our paper POPE that we plan to release soon!
Perspectives on future work. In this blog we asked how to explore on hard problems. But even defining “hard” is tricky. We used a simple, testable notion (large token budgets and parallel attempts still fail), though better definitions might lead to more practical algorithms. We found that guided exploration can indeed push RL beyond the sharpening and chaining regimes, but some problems remain unsolved even with guidance. For example, in Figure 2, we were only able to solve ~50% of the hard problem set after sufficiently many RL iterations. This means there is both room in pushing guided exploration further as well as going beyond this paradigm to novel ones. For instance, we can leverage previously spent compute on the pre-trained model (e.g., prior RL runs) in the form of off-policy data that can guide exploration for the current RL model (Amrith’s work coming out soon!). Another example would be to repurpose human solutions for credit assignment by exploiting asymmetries, e.g., the gap between comparing solutions to provide targeted interventions in the middle of a reasoning trace (our work coming out soon!). Likewise, leaning on classical deep RL, we can enabling RL algorithms to benefit from both offline and off-policy data to learn value functions, which is likely to improve exploration. Our prior work has already shown the promise of process-level advantage value functions for improving solvability on hard problems. These remain promising directions for scaling RL further.
Acknowledgements. We thank Ian Wu, Matthew Yang, Saurabh Garg, Preston Fu, Apurva Gandhi, Gabriel Sarch, Sang Michael Xie, Paria Rashidinejad, Violet Xiang, Christina Baek, Chen Wu and Anikait Singh for helpful discussions and feedback on an earlier version of this post. Most experiments in this blog were done using our adaptation of PipelineRL, a streaming RL library that we recently switched our experiments to for better throughput on RL runs. We thank the CMU FLAME center for providing the GPU resources that supported this work.
If you think this blog post is useful for your work, please consider citing it. Thank you!
@misc{qu2025pope,
author={Qu, Yuxiao and Setlur, Amrith and Smith, Virginia and Salakhutdinov, Ruslan and Kumar, Aviral},
title={How to Explore to Scale RL Training of LLMs on Hard Problems?},
howpublished = {url{https://blog.ml.cmu.edu/2025/11/26/how-to-explore-to-scale-rl-training-of-llms-on-hard-problems}},
note = {CMU MLD Blog} ,
year={2025},
}