This post is cross-listed on hunch.net
The International Conference on Machine Learning (ICML) is a flagship machine learning conference that in 2020 received 4,990 submissions and managed a pool of 3,931 reviewers and area chairs. Given that the stakes in the review process are high — the careers of researchers are often significantly affected by the publications in top venues — we decided to scrutinize several components of the peer-review process in a series of experiments. Specifically, in conjunction with the ICML 2020 conference, we performed three experiments that target: resubmission policies, management of reviewer discussions, and reviewer recruiting. In this post, we summarize the results of these studies.
Resubmission Bias
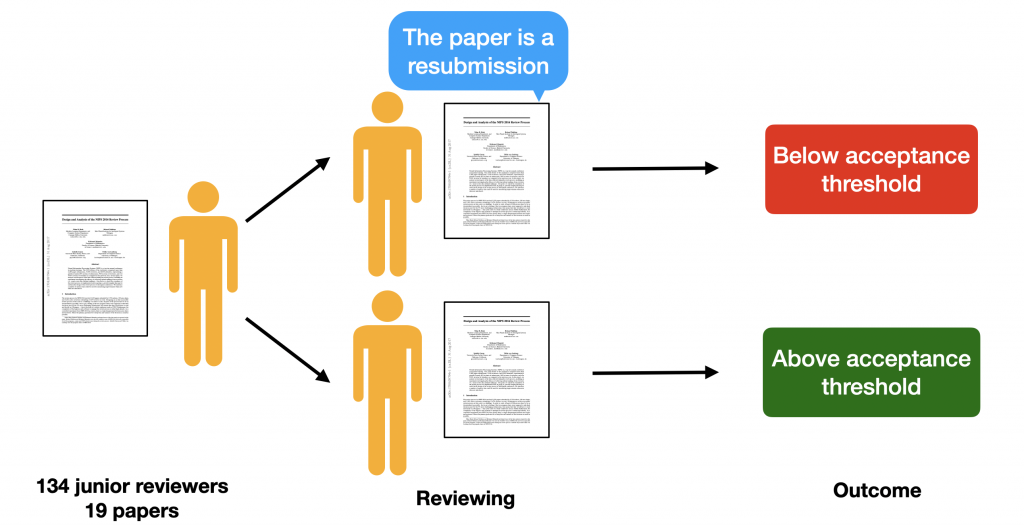
Motivation. Several leading ML and AI conferences have recently started requiring authors to declare previous submission history of their papers. In part, such measures are taken to reduce the load on reviewers by discouraging resubmissions without substantial changes. However, this requirement poses a risk of bias in reviewers’ evaluations.
Research question. Do reviewers get biased when they know that the paper they are reviewing was previously rejected from a similar venue?
Procedure. We organized an auxiliary conference review process with 134 junior reviewers from 5 top US schools and 19 papers from various areas of ML. We assigned participants 1 paper each and asked them to review the paper as if it was submitted to ICML. Unbeknown to participants, we allocated them to a test or control condition uniformly at random:
- Control. Participants review the papers as usual.
- Test. Before reading the paper, participants are told that the paper they review is a resubmission.
Hypothesis. We expect that if the bias is present, reviewers in the test condition should be harsher than in the control.
Key findings. Reviewers give almost one point lower score (95% Confidence Interval: [0.24, 1.30]) on a 10-point Likert item for the overall evaluation of a paper when they are told that a paper is a resubmission. In terms of narrower review criteria, reviewers tend to underrate “Paper Quality” the most.
Implications. Conference organizers need to evaluate a trade-off between envisaged benefits such as the hypothetical reduction in the number of submissions and the potential unfairness introduced to the process by the resubmission bias. One option to reduce the bias is to postpone the moment in which the resubmission signal is revealed until after the initial reviews are submitted. This finding must also be accounted for when deciding whether the reviews of rejected papers should be publicly available on systems like openreview.net and others.
Details. http://arxiv.org/abs/2011.14646
Herding Effects in Discussions
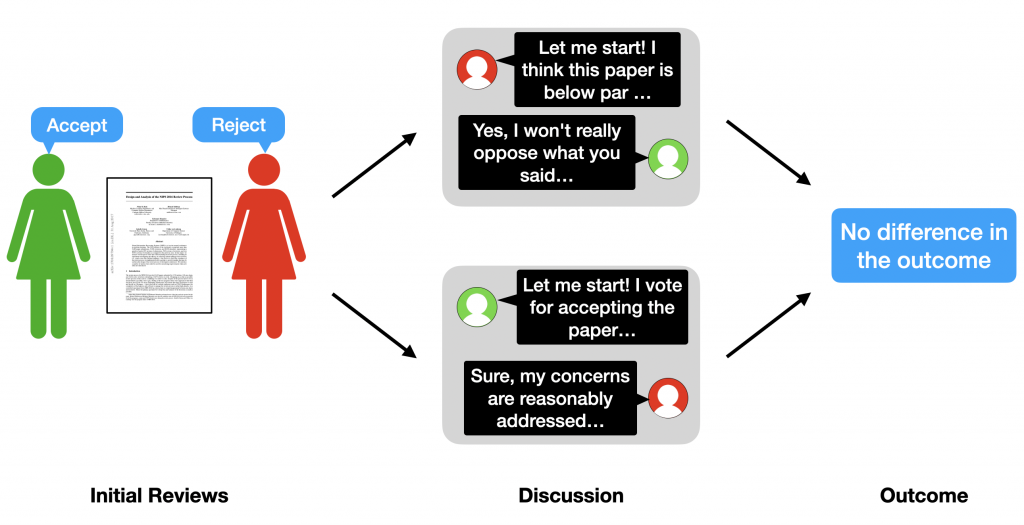
Motivation. Past research on human decision making shows that group discussion is susceptible to various biases related to social influence. For instance, it is documented that the decision of a group may be biased towards the opinion of the group member who proposes the solution first. We call this effect herding and note that, in peer review, herding (if present) may result in undesirable artifacts in decisions as different area chairs use different strategies to select the discussion initiator.
Research question. Conditioned on a set of reviewers who actively participate in a discussion of a paper, does the final decision of the paper depend on the order in which reviewers join the discussion?
Procedure. We performed a randomized controlled trial on herding in ICML 2020 discussions that involved about 1,500 papers and 2,000 reviewers. In peer review, the discussion takes place after the reviewers submit their initial reviews, so we know prior opinions of reviewers about the papers. With this information, we split a subset of ICML papers into two groups uniformly at random and applied different discussion-management strategies to them:
- Positive Group. First ask the most positive reviewer to start the discussion, then later ask the most negative reviewer to contribute to the discussion.
- Negative Group. First ask the most negative reviewer to start the discussion, then later ask the most positive reviewer to contribute to the discussion.
Hypothesis. The only difference between the strategies is the order in which reviewers are supposed to join the discussion. Hence, if the herding is absent, the strategies will not impact submissions from the two groups disproportionately. However, if the herding is present, we expect that the difference in the order will introduce a difference in the acceptance rates across the two groups of papers.
Key findings. The analysis of outcomes of approximately 1,500 papers does not reveal a statistically significant difference in acceptance rates between the two groups of papers. Hence, we find no evidence of herding in the discussion phase of peer review.
Implications. Regarding the concern of herding which is found to occur in other applications involving people, discussion in peer review does not seem to be susceptible to this effect and hence no specific measures to counteract herding in peer-review discussions are needed.
Details. https://arxiv.org/abs/2011.15083
Novice Reviewer Recruiting
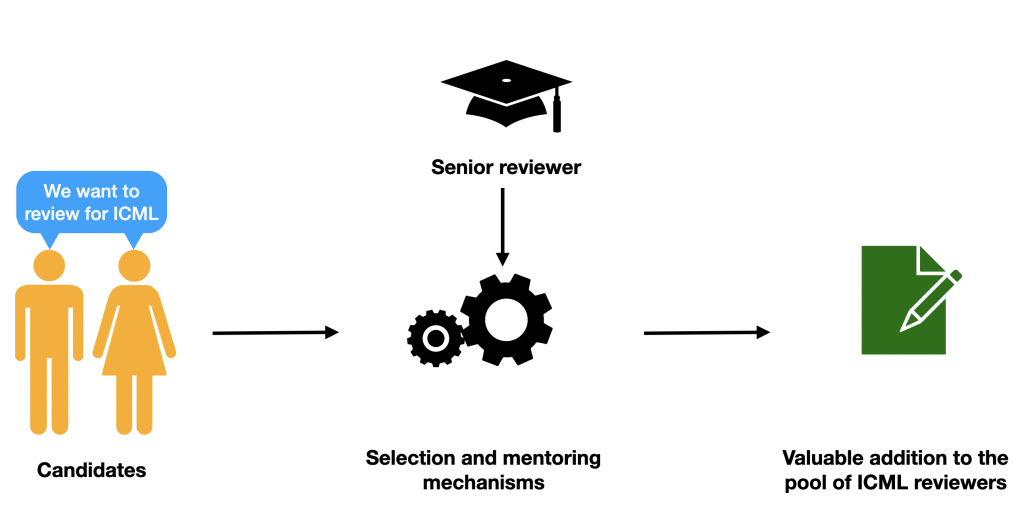
Motivation. A surge in the number of submissions received by leading ML and AI conferences has challenged the sustainability of the review process by increasing the burden on the pool of qualified reviewers. Leading conferences have been addressing the issue by relaxing the seniority bar for reviewers and inviting researchers with limited or no publication history, but there is mixed evidence regarding the impact of such interventions on the quality of reviews.
Research question. Can researchers with limited or no publication history be recruited and guided such that they enlarge the reviewer pool of leading ML and AI conferences without compromising the quality of the process?
Procedure. We implemented a twofold approach towards managing novice reviewers:
- Selection. We evaluated reviews written in the aforementioned auxiliary conference review process involving 134 junior reviewers, and invited 52 of these reviewers who produced the strongest reviews to join the reviewer pool of ICML 2020. Most of these 52 “experimental” reviewers come from the population not considered by the conventional way of reviewer recruiting used in ICML 2020.
- Mentoring. In the actual conference, we provided these experimental reviewers with a senior researcher as a point of contact who offered additional mentoring.
Hypothesis. If our approach allows to bring strong reviewers to the pool, we expect experimental reviewers to perform at least as good as reviewers from the main pool on various metrics, including the quality of reviews as rated by area chairs.
Key findings. A combination of the selection and mentoring mechanisms results in reviews of at least comparable and on some metrics even higher-rated quality as compared to the conventional pool of reviews: 30% of reviews written by the experimental reviewers exceeded the expectations of area chairs (compared to only 14% for the main pool).
Implications. The experiment received positive feedback from participants who appreciated the opportunity to become a reviewer in ICML 2020 and from authors of papers used in the auxiliary review process who received a set of useful reviews without submitting to a real conference. Hence, we believe that a promising direction is to replicate the experiment at a larger scale and evaluate the benefits of each component of our approach.
Details. http://arxiv.org/abs/2011.15050
Conclusion
All in all, the experiments we conducted in ICML 2020 reveal some useful and actionable insights about the peer-review process. We hope that some of these ideas will help to design a better peer-review pipeline in future conferences.
We thank ICML area chairs, reviewers, and authors for their tremendous efforts. We would also like to thank the Microsoft Conference Management Toolkit (CMT) team for their continuous support and implementation of features necessary to run these experiments, the authors of papers contributed to the auxiliary review process for their responsiveness, and participants of the resubmission bias experiment for their enthusiasm. Finally, we thank Ed Kennedy and Devendra Chaplot for their help with designing and executing the experiments.
The post is based on joint works with Nihar B. Shah, Aarti Singh, Hal Daumé III, and Charvi Rastogi.
In a previous version of this post, we had used an illustration that reinforced sexist stereotypes. We have updated the figure this morning, and sincerely apologize to the entire ICML community for not checking the illustrations more carefully and thereby sending the wrong message to the ICML community. We are strongly opposed to sexism or any other form of discrimination, and thank those who raised this issue with us.