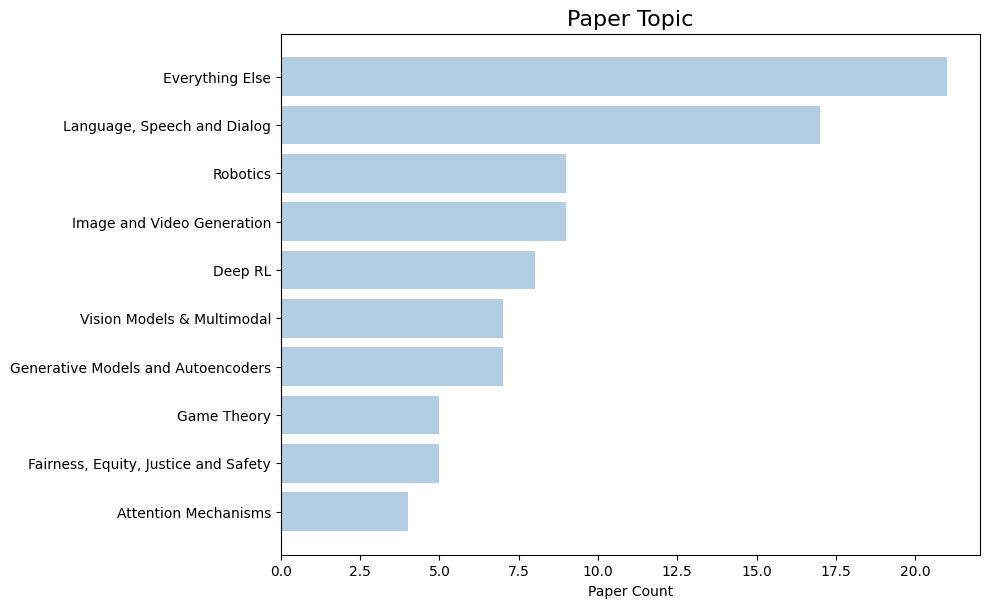
CMU researchers are presenting 194 papers at the Fourteenth International Conference on Learning Representations (ICLR 2026), held from April 23rd-April 27th at the Riocentro Convention and Event Center in Rio de Janeiro, Brazil. Here is a quick overview of the areas our researchers are working on:
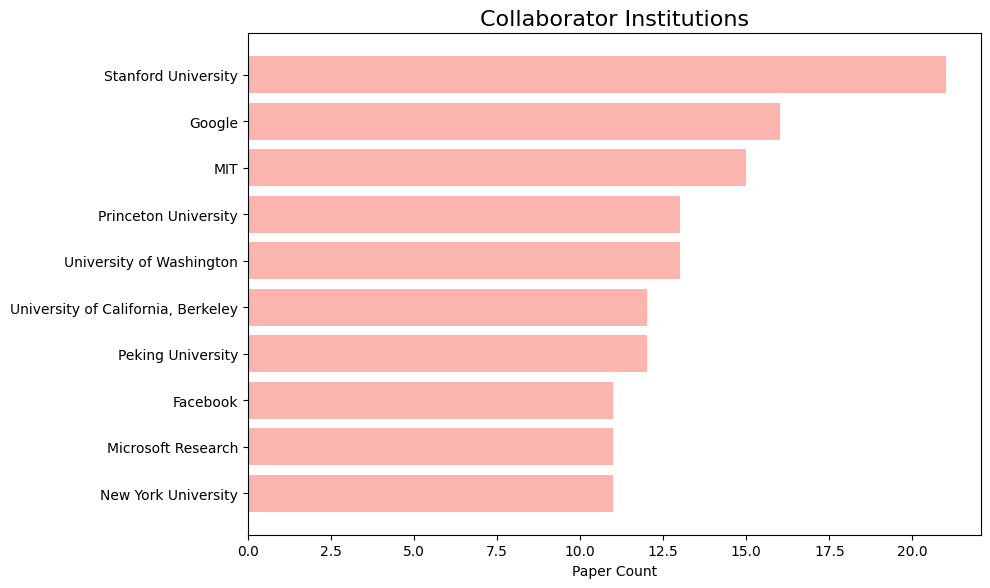
Here are our most frequent collaborator institutions:
Oral Papers
EditBench: Evaluating LLM Abilities to Perform Real-World Instructed Code Edits
Authors: Wayne Chi (CMU), Valerie Chen (Carnegie Mellon University), Ryan Shar (Apple), Aditya Mittal (CMU, Carnegie Mellon University), Jenny Liang (School of Computer Science, Carnegie Mellon University), Wei-Lin Chiang (UC Berkeley / LMSYS), Anastasios Angelopoulos (University of California Berkeley), Ion Stoica (), Graham Neubig (Carnegie Mellon University), Ameet Talwalkar (University of California-Los Angeles), Chris Donahue (CMU / Google DeepMind)
This work introduces EditBench, a new benchmark for testing how well AI models can edit existing code based on user instructions. Unlike prior benchmarks, it uses real-world coding tasks and contexts, including things like the surrounding code and cursor position. The benchmark includes 545 diverse problems, and results show that most models struggle—only a few achieve strong performance. The study also finds that having more realistic context significantly impacts how well models perform, highlighting the importance of evaluating code-editing in real-world settings.
UALM: Unified Audio Language Model for Understanding, Generation and Reasoning
Authors: Jinchuan Tian (CMU, Carnegie Mellon University), Sang-gil Lee (NVIDIA), Zhifeng Kong (NVIDIA), Sreyan Ghosh (Nvidia), Arushi Goel (NVIDIA), Chao-Han Huck Yang (NVIDIA Research), Wenliang Dai (NVIDIA), Zihan Liu (Nvidia), Hanrong Ye (NVIDIA), Shinji Watanabe (Carnegie Mellon University), Mohammad Shoeybi (NVIDIA), Bryan Catanzaro (NVIDIA), Rafael Valle (NVIDIA), Wei Ping (Nvidia)
This paper introduces the Unified Audio Language Model (UALM), a single model designed to handle audio understanding, text-to-audio generation, and multimodal reasoning together. Instead of treating these as separate tasks, UALM learns to both interpret and generate audio, achieving performance comparable to specialized state-of-the-art models. The authors also show that combining text and audio during the model’s reasoning process improves its ability to handle complex tasks. Overall, the work demonstrates a step toward more general AI systems that can reason across both language and sound.
Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
Authors: Yueqi Song (CMU), Ketan Ramaneti (Amazon), Zaid Sheikh (Carnegie Mellon University), Ziru Chen (Ohio State University, Columbus), Boyu Gou (Ohio State University, Columbus), Tianbao Xie (the University of Hong Kong, University of Hong Kong), Yiheng Xu (University of Hong Kong), Danyang Zhang (Shanghai Jiao Tong University), Apurva Gandhi (Carnegie Mellon University), Fan Yang (Fujitsu), Joseph Liu (School of Computer Science, Carnegie Mellon University), Tianyue Ou (Carnegie Mellon University), Zhihao Yuan (Carnegie Mellon University), Frank F Xu (Carnegie Mellon University), Shuyan Zhou (Facebook), Xingyao Wang (All Hands AI), Xiang Yue (Carnegie Mellon University), Tao Yu (University of Hong Kong), Huan Sun (Ohio State University), Yu Su (Ohio State University), Graham Neubig (Carnegie Mellon University)
This work introduces the Agent Data Protocol (ADP), a standardized format for representing training data for AI agents. The authors argue that the main challenge isn’t a lack of data, but that existing datasets are fragmented across different formats and tools. ADP acts as a common “interlingua,” making it easier to combine diverse data sources—like coding, browsing, and tool use—into a single training pipeline. By converting 13 datasets into this unified format, the authors show that models trained on the combined data achieve improved performance.
MotionStream: Real-Time Video Generation with Interactive Motion Controls
Authors: Joonghyuk Shin (Seoul National University), Zhengqi Li (Google), Richard Zhang (Adobe), Jun-Yan Zhu (Carnegie Mellon University), Jaesik Park (Seoul National University), Eli Shechtman (Adobe), Xun Huang (Adobe Research)
This paper introduces MotionStream, a system for generating videos in real time based on motion and text inputs. Unlike prior methods that take minutes to produce a video, MotionStream can stream results at up to 29 frames per second on a single GPU. The key idea is to train a fast, causal model that can generate video continuously, using techniques that prevent quality from degrading over long sequences. As a result, users can interactively control motion—like drawing paths or moving a camera—and see the video update instantly.
OpenThoughts: Data Recipes for Reasoning Models
Authors: Etash Guha (Stanford University, Anthropic), Ryan Marten (Harbor), Sedrick Keh (Toyota Research Institute), Negin Raoof (University of California, Berkeley), Georgios Smyrnis (University of Texas, Austin), Hritik Bansal (University of California, Los Angeles), Marianna Nezhurina (Juelich Supercomputing Center, LAION, Tuebingen University), Jean Mercat (Toyota Research Institute (TRI)), Trung Vu (Google), Zayne Sprague (New York University), Ashima Suvarna (UCLA), Benjamin Feuer (Stanford University), Leon Liangyu Chen (Stanford University), Zaid Khan (University of North Carolina at Chapel Hill), Eric Frankel (Department of Computer Science, University of Washington), Sachin Grover (Arizona State University), Caroline Choi (None), Niklas Muennighoff (Stanford University), Shiye Su (Stanford University), Wanjia Zhao (Stanford University), John Yang (Princeton University), Shreyas Pimpalgaonkar (New York University), Kartik sharma (Georgia Institute of Technology), Charlie Ji (University of California, Berkeley), Yichuan Deng (Department of Computer Science, University of Washington), Sarah Pratt (University of Washington), Vivek Ramanujan (Department of Computer Science, University of Washington), Jon Saad-Falcon (Computer Science Department, Stanford University), Stutee Acharya (University of South Florida), Jeffrey Li (Carnegie Mellon University), Achal Dave (Anthropic), Alon Albalak (SynthLabs), Kushal Arora (McGill University), Blake Wulfe (Toyota Research Institute), Chinmay Hegde (New York University), Greg Durrett (New York University), Sewoong Oh (University of Washington), Mohit Bansal (UNC Chapel Hill), Saadia Gabriel (University of Washington), Aditya Grover (UCLA), Kai-Wei Chang (University of Virginia Main Campus), Vaishaal Shankar (Apple), Aaron Gokaslan (Cornell University), Mike Merrill (None), Tatsunori Hashimoto (Stanford University), Yejin Choi (Stanford University / NVIDIA), Jenia Jitsev (LAION; Juelich Supercomputing Center, Research Center Juelich), Reinhard Heckel (Technical University Munich), Maheswaran Sathiamoorthy (University of Southern California), Alex Dimakis (Electrical Engineering & Computer Science Department, University of California, Berkeley), Ludwig Schmidt (University of Washington / Stanford / Anthropic)
This work introduces the OpenThoughts project, which aims to create high-quality, open-source datasets for training reasoning-focused AI models. The authors show that models trained on their public data can match or exceed the performance of strong existing systems that rely on private datasets. By carefully studying and improving their data generation process, they build larger and better datasets that significantly boost performance across math, coding, and science benchmarks. Overall, the project demonstrates that open data alone can be enough to train highly capable reasoning models.
Mamba-3: Improved Sequence Modeling using State Space Principles
Authors: Aakash Sunil Lahoti (CMU, Carnegie Mellon University), Kevin Li (Carnegie Mellon University), Berlin Chen (Princeton University), Caitlin Wang (Princeton University), Aviv Bick (Carnegie Mellon University), Zico Kolter (Carnegie Mellon University), Tri Dao (Princeton University), Albert Gu (Cartesia AI CMU)
This paper introduces Mamba-3, a new model designed to make AI inference faster and more efficient without sacrificing performance. While many efficient alternatives to Transformers reduce computation, they often struggle with tasks like tracking long-term information; Mamba-3 addresses this with improved state modeling and a more expressive update mechanism. The model also uses a multi-input, multi-output design to boost accuracy without slowing down generation. Overall, Mamba-3 shows that it’s possible to improve both efficiency and capability at the same time, pushing forward the tradeoff between speed and performance.
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
Authors: Yuxuan Zhou (Independent Researcher), Fei Huang (Alibaba Group), Heng Li (Carnegie Mellon University), Fengyi Wu (University of Washington), Tianyu Wang (University of Washington), Jianwei Zhang (Alibaba Group), Junyang Lin (Alibaba Group), Zhi-Qi Cheng (University of Washington)
This paper introduces Hierarchical Speculative Decoding (HSD), a new method to speed up large language model inference by improving the verification step in speculative decoding while preserving exact output distributions. It addresses the challenge of “joint intractability” in sequence-level verification by organizing resampling into a hierarchy that redistributes probability mass across branches, enabling more tokens to be accepted at once. The approach is theoretically proven to be lossless and empirically shows consistent speed improvements across models and benchmarks, outperforming prior tokenwise and blockwise verification methods. Overall, HSD offers a practical and general way to accelerate decoding without sacrificing fidelity, achieving state-of-the-art efficiency when integrated into existing frameworks.
Distributional Equivalence in Linear Non-Gaussian Latent-Variable Cyclic Causal Models: Characterization and Learning
Authors: Haoyue Dai (Carnegie Mellon University), Immanuel Albrecht (FernUniversität in Hagen), Peter Spirtes (Carnegie Mellon University), Kun Zhang (Carnegie Mellon University & MBZUAI)
This paper studies causal discovery in linear non-Gaussian models with latent variables and cycles, focusing on when different causal graphs are observationally indistinguishable. It provides the first general characterization of distributional equivalence in this setting, introducing new tools—especially edge rank constraints—to describe when two models generate the same observed data. Building on this theory, the authors derive practical graphical criteria and transformations to enumerate all equivalent models and propose an algorithm to recover the entire equivalence class from data. Overall, the work removes the need for strong structural assumptions and offers a general, principled framework for latent-variable causal discovery.
Revela: Dense Retriever Learning via Language Modeling
Authors: Fengyu Cai (Technische Universität Darmstadt), Tong Chen (University of Washington), Xinran Zhao (Carnegie Mellon University), Sihao Chen (Microsoft), Hongming Zhang (Tencent AI Lab Seattle), Sherry Wu (Carnegie Mellon University), Iryna Gurevych (Technical University of Darmstadt / Mohamed bin Zayed University of Artificial Intelligence), Heinz Koeppl (TU Darmstadt)
This paper introduces Revela, a self-supervised framework for training dense retrievers by leveraging language modeling objectives instead of relying on annotated query-document pairs. It augments next-token prediction with an in-batch attention mechanism that allows documents to attend to each other, enabling the retriever to learn cross-document relationships jointly with a language model. Experiments across domain-specific, reasoning-intensive, and general benchmarks show that Revela matches or surpasses supervised and API-based retrievers while using significantly less data and compute. Overall, the work demonstrates a scalable and efficient alternative for retriever learning directly from raw text with strong generalization across domains.
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Authors: Tal Daniel (Carnegie Mellon University), Carl Qi (University of Texas at Austin), Dan Haramati (Brown University), Amir Zadeh (Lambda), Chuan Li (Lambda Labs), Aviv Tamar (Technion), Deepak Pathak (Carnegie Mellon University), David Held (Carnegie Mellon University)
This paper introduces the Latent Particle World Model (LPWM), a self-supervised, object-centric world model that learns to decompose scenes into latent particles (e.g., keypoints, masks, and object attributes) directly from raw video without supervision. It proposes a novel per-particle latent action mechanism that models stochastic dynamics, enabling the system to capture complex multi-object interactions and generate diverse future predictions. The model is trained end-to-end and supports flexible conditioning on actions, language, and goal images, achieving state-of-the-art performance on both real-world and synthetic video prediction tasks. Beyond video modeling, LPWM also demonstrates strong potential for decision-making applications such as imitation learning by leveraging its learned latent dynamics.
LoongRL: Reinforcement Learning for Advanced Reasoning over Long Contexts
Authors: Siyuan Wang (Shanghai Jiao Tong University), Gaokai Zhang (Carnegie Mellon University), Li Lyna Zhang (Microsoft Research Asia), Ning Shang (Microsoft), Fan Yang (Microsoft Research), Dongyao Chen (Shanghai Jiaotong University), Mao Yang (Peking University)
The authors introduce LoongRL, a reinforcement learning framework designed to improve long-context reasoning in large language models by training them on challenging, synthesized tasks. They propose KeyChain, a data construction method that embeds hidden question chains within long documents, forcing models to perform multi-step planning, retrieval, and reasoning rather than relying on shortcuts. Through RL training, models develop an emergent “plan–retrieve–reason–recheck” reasoning pattern that generalizes from shorter (16K) to much longer (128K) contexts. Experiments show that LoongRL significantly boosts long-context reasoning performance while maintaining strong short-context abilities, achieving results comparable to much larger models.
Exchangeability of GNN Representations with Applications to Graph Retrieval
Authors: Kartik Nair (Carnegie Mellon University), Indradyumna Roy (IIT Bombay, Aalto University), Soumen Chakrabarti (IIT Bombay), Anirban Dasgupta (IIT Gandhinagar), Abir De (Indian Institute of Technology Bombay)
This paper introduces the concept of exchangeability in graph neural networks (GNNs), showing that the dimensions of learned node embeddings are statistically interchangeable due to random initialization and permutation-invariant training. This property implies that embedding components share identical distributions, enabling simplifications in how graph similarities are computed. Leveraging this insight, the authors approximate complex transportation-based graph distances using simpler Euclidean operations on sorted embedding values. They further propose GRAPHHASH, a locality-sensitive hashing framework that enables efficient and scalable graph retrieval, achieving strong performance compared to existing methods.
Poster Papers
Applications
TusoAI: Agentic Optimization for Scientific Methods
Authors: Alistair Turcan (School of Computer Science, Carnegie Mellon University), Kexin Huang (Stanford University), Lei Li (School of Computer Science, Carnegie Mellon University), Martin J. Zhang (Carnegie Mellon University)
Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning
Authors: Ganlin Yang (University of Science and Technology of China), Tianyi Zhang (Zhejiang University; Shanghai Artificial Intelligence Laboratory), Haoran Hao (Carnegie Mellon University), Weiyun Wang (Fudan University), Yibin Liu (Northeastern University), Dehui Wang (Shanghai Jiaotong University), Guanzhou Chen (Shanghai AI Laboratory, Shanghai Jiaotong University), Zijian Cai (Shenzhen University), Junting Chen (national university of singaore, National University of Singapore), Weijie Su (University of Science and Technology of China), Wengang Zhou (University of Science and Technology of China), Yu Qiao (Shanghai Aritifcal Intelligence Laboratory), Jifeng Dai (Tsinghua University, Tsinghua University), Jiangmiao Pang (Shanghai AI Laboratory), Gen Luo (Shanghai AI Laboratory), Wenhai Wang (Shanghai AI Laboratory), Yao Mu (Shanghai Jiao Tong University), Zhi Hou (Shanghai Artificial Intelligence Laboratory)
MetaVLA: Unified Meta Co-Training for Efficient Embodied Adaptation
Authors: Chen Li (Carnegie Mellon University), Zhantao Yang (Carnegie Mellon University), Han Zhang (Carnegie Mellon University), Fangyi Chen (ByteDance Inc.), Chenchen Zhu (Meta AI), Anudeepsekhar Bolimera (Carnegie Mellon University), Marios Savvides (Carnegie Mellon University)
RobotArena $\infty$: Scalable Robot Benchmarking via Real-to-Sim Translation
Authors: Yash Jangir (Carnegie Mellon University), Yidi Zhang (), Kashu Yamazaki (CMU, Carnegie Mellon University), Chenyu Zhang (Peking University), Kuan-Hsun Tu (National Taiwan University), Tsung-Wei Ke (Department of computer science and informational engineering, National Taiwan University), Lei Ke (Carnegie Mellon University), Yonatan Bisk (Carnegie Mellon University), Katerina Fragkiadaki (CMU)
Generalizable End-to-End Tool-Use RL with Synthetic CodeGym
Authors: Weihua Du (Tsinghua University), HaileiGong (Huawei Technologies Ltd.), Zhan Ling (UC San Diego), Kang Liu (ByteDance Inc.), Lingfeng Shen (Johns Hopkins University), Xuesong Yao (ByteDance Inc.), Yufei Xu (ByteDance Inc.), Dingyuan Shi (ByteDance Inc.), Yiming Yang (Carnegie Mellon University), Jiecao Chen (ByteDance Inc.)
WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
Authors: Zhaojiang Lin (Meta), YONG XU (Meta), Kai Sun (Meta), Jing Zheng (Ant Group), Yin Huang (Facebook), Surya Appini (Meta), Krish Narang (Facebook), Renjie Tao (Facebook), Ishan Jain (Facebook), Siddhant Arora (Carnegie Mellon University), Ruizhi Li (Facebook), Yiteng Huang (Facebook), Kaushik Patnaik (Apple), Wenfang Xu (Meta Platforms, Inc.), Suwon Shon (ASAPP), Yue Liu (Meta), Ahmed Aly (Facebook), Anuj Kumar (Meta), Florian Metze (Carnegie Mellon University), Xin Dong (Facebook)
Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Authors: Justin Lin (Computer Science Department, Stanford University), Eliot Jones (Gray Swan), Donovan Jasper (Stanford University), Ethan Ho (Stanford University), Anna Wu (Computer Science Department, Stanford University), Arnold Yang (Stanford University), Neil Perry (Princeton University), Andy Zou (CMU, Carnegie Mellon University), Matt Fredrikson (University of Wisconsin, Madison), Zico Kolter (Carnegie Mellon University), Percy Liang (Stanford University), Dan Boneh (Stanford University), Daniel Ho (Stanford University)
Bound by semanticity: universal laws governing the generalization-identification tradeoff
Authors: Marco Nurisso (Polytechnic University of Turin), Jesseba Fernando (Northeastern University), Raj Deshpande (Northeastern University London), Alan Perotti (Intesa Sanpaolo AI Research), Raja Marjieh (Princeton University), Steven Frankland (Dartmouth College), Richard Lewis (Carnegie Mellon University), Taylor Webb (University of California, Los Angeles), Declan Campbell (Princeton University), Francesco Vaccarino (Politecnico di Torino), Jonathan Cohen (Princeton University), Giovanni Petri (Network Science Institute, Northeastern University London)
Zero-shot Forecasting by Simulation Alone
Authors: Boris Oreshkin (Amazon), Mayank Jauhari (Amazon), Ravi Kiran Selvam (Amazon), Malcolm Wolff (Amazon), Wenhao Pan (University of Washington), Shankar Ramasubramanian (Amazon), KIN GUTIERREZ (Carnegie Mellon University), Tatiana Konstantinova (Amazon), Andres Potapczynski (New York University), Mengfei Cao (Amazon.com), Dmitry Efimov (Amazon), Michael W Mahoney (University of California Berkeley), Andrew Gordon Wilson (New York University)
Self-Improving Vision-Language-Action Models with Data Generation via Residual RL
Authors: Wenli Xiao (Carnegie Mellon University), Haotian Lin (CMU, Carnegie Mellon University), Andy Peng (University of California, Berkeley), Haoru Xue (University of California, Berkeley), Tairan He (NVIDIA), Zhengyi Luo (Carnegie Mellon University), Yuqi Xie (NVIDIA), Fengyuan Hu (NVIDIA), Jim Fan (NVIDIA), Guanya Shi (CMU, Carnegie Mellon University), Yuke Zhu (NVIDIA / UT-Austin)
Improving Attributed Long-form Question Answering with Intent Awareness
Authors: Xinran Zhao (CMU, Carnegie Mellon University), Aakanksha Naik (Allen Institute for Artificial Intelligence), Jay DeYoung (Allen Institute for Artificial Intelligence), Joseph Chee Chang (Allen Institute for Artificial Intelligence), Jena Hwang (Allen Institute for Artificial Intelligence), Sherry Wu (Carnegie Mellon University), Varsha Kishore (Cornell University)
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Authors: Yitang Li (), Zhengyi Luo (Carnegie Mellon University), Tonghe Zhang (Carnegie Mellon University), Cunxi Dai (Carnegie Mellon University), Anssi Kanervisto (Microsoft Research), Andrea Tirinzoni (Meta, FAIR), Haoyang Weng (Tsinghua University, Tsinghua University), Kris Kitani (Carnegie Mellon University), Mateusz Guzek (Meta AI), Ahmed Touati (Meta AI Research), Alessandro Lazaric (Facebook), Matteo Pirotta (Meta), Guanya Shi (CMU, Carnegie Mellon University)
Real-Time Reasoning Agents in Evolving Environments
Authors: Yule Wen (Tsinghua University, Tsinghua University), Yixin Ye (Shanghai Jiaotong University), Yanzhe Zhang (Georgia Institute of Technology), Diyi Yang (Stanford University), Hao Zhu (Carnegie Mellon University)
ExpertLongBench: Benchmarking Language Models on Expert-Level Long-Form Generation Tasks with Structured Checklists
Authors: Jie Ruan (University of Michigan – Ann Arbor), Inderjeet Nair (University of Michigan – Ann Arbor), Shuyang Cao (Bloomberg), Amy Liu (University of Michigan), Sheza Munir (University of Toronto), Micah Pollens-Dempsey (University of Michigan – Ann Arbor), Yune-Ting Chiang (University of Michigan – Ann Arbor), Lucy Kates (University of Michigan – Ann Arbor), Nicholas David (University of Michigan – Ann Arbor), Sihan Chen (Carnegie Mellon University), Ruxin Yang (University of Michigan – Ann Arbor), Yuqian Yang (University of Michigan – Ann Arbor), Jihyun Gump (University of Michigan – Ann Arbor), Tessa Bialek (University of Michigan Law School), Vivek Sankaran (University of Michigan – Ann Arbor), Margo Schlanger (University of Michigan – Ann Arbor), Lu Wang (University of Michigan)
ViPRA: Video Prediction for Robot Actions
Authors: Sandeep Kumar Routray (Skild AI), Hengkai Pan (CMU, Carnegie Mellon University), Unnat Jain (Facebook AI Research), Shikhar Bahl (Skild AI), Deepak Pathak (Carnegie Mellon University)
Contact-guided Real2Sim from Monocular Video with Planar Scene Primitives
Authors: Zihan Wang (Amazon), Jiashun Wang (School of Computer Science, Carnegie Mellon University), Jeff Tan (Carnegie Mellon University), Yiwen Zhao (School of Computer Science, Carnegie Mellon University), Jessica Hodgins (RAI Institute), Shubham Tulsiani (Carnegie Mellon University), Deva Ramanan (School of Computer Science, Carnegie Mellon University)
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Authors: Junlong Li (The Hong Kong University of Science and Technology), Wenshuo Zhao (Zhejiang University), Jian Zhao (Beijing University of Posts and Telecommunications), Weihao Zeng (Hong Kong University of Science and Technology), Haoze Wu (Zhejiang University), Xiaochen Wang (None), Rui Ge (Shanghai Jiaotong University), Yuxuan Cao (HKUST), Yuzhen Huang (HKUST), Wei Liu (HKUST), Junteng LIU (HKUST), Zhaochen Su (The Hong Kong University of Science and Technology), Yiyang Guo (Fudan University), FAN ZHOU (Shanghai Jiao Tong University), Lueyang Zhang (The Hong Kong University of Science and Technology), Juan Michelini (Universidad de la República), Xingyao Wang (All Hands AI), Xiang Yue (Carnegie Mellon University), Shuyan Zhou (Facebook), Graham Neubig (Carnegie Mellon University), Junxian He (HKUST)
SAC Flow: Sample-Efficient Reinforcement Learning of Flow-Based Policies via Velocity-Reparameterized Sequential Modeling
Authors: Yixian Zhang (Tsinghua University, Tsinghua University), Shu-ang Yu (Tsinghua University), Tonghe Zhang (Carnegie Mellon University), Mo Guang (Li Auto Inc.), Haojia Hui (Li Auto Inc.), Kaiwen Long (Li Auto Inc.), Yu Wang (Tsinghua Univ.), Chao Yu (Tsinghua University), Wenbo Ding (Tsinghua University, Tsinghua University)
Computer Vision
Multi-Object System Identification from Videos
Authors: Chunjiang Liu (Carnegie Mellon University), Xiaoyuan Wang (Carnegie Mellon University), Qingran Lin (Georgia Institute of Technology), Albert Xiao (Carnegie Mellon University), Haoyu Chen (Harvard University, Harvard University), Shizheng Wen (ETHZ – ETH Zurich), Hao Zhang (UIUC), Lu Qi (Insta360), Ming-Hsuan Yang (Google DeepMind), Laszlo A. Jeni (Carnegie Mellon University), Min Xu (Carnegie Mellon University), Yizhou Zhao (Snap Inc.)
Learning an Image Editing Model without Image Editing Pairs
Authors: Nupur Kumari (Carnegie Mellon University), Sheng-Yu Wang (CMU, Carnegie Mellon University), Cherry Zhao (Adobe Research), Yotam Nitzan (Adobe Research), Yuheng Li (Adobe Systems), Krishna Kumar Singh (Adobe Systems), Richard Zhang (Adobe), Eli Shechtman (Adobe), Jun-Yan Zhu (Carnegie Mellon University), Xun Huang (Adobe Research)
Controllable Video Generation with Provable Disentanglement
Authors: Yifan Shen (Mohamed bin Zayed University of Artificial Intelligence), Peiyuan Zhu (Mohamed bin Zayed University of Artificial Intelligence), Zijian Li (Mohamed bin Zayed University of Artificial Intelligence), Shaoan Xie (Carnegie Mellon University), Namrata Deka (Carnegie Mellon University), Zongfang Liu (Zhejiang University), Zeyu Tang (Stanford University), Guangyi Chen (MBZUAI&CMU), Kun Zhang (Carnegie Mellon University & MBZUAI)
Virtual Community: An Open World for Humans, Robots, and Society
Authors: Qinhong Zhou (University of Massachusetts at Amherst), Hongxin Zhang (UMass Amherst), Xiangye Lin (University of Massachusetts at Amherst), Zheyuan Zhang (Johns Hopkins University), Yutian Chen (Carnegie Mellon University), Wenjun Liu (University of Massachusetts at Amherst), Zunzhe Zhang (Tsinghua University), Sunli Chen (University of Massachusetts at Amherst), Lixing Fang (University of Massachusetts at Amherst), Qiushi Lyu (University of Illinois, Urbana-Champaign), Xinyu Sun (South China University of Technology), Jincheng Yang (University of Maryland, College Park), Zeyuan Wang (Tsinghua University, Tsinghua University), Bao Dang (University of Massachusetts at Amherst), Zhehuan Chen (Peking University), Daksha Ladia (University of Massachusetts Amherst), Quang Dang (University of Massachusetts at Amherst), Jiageng Liu (University of Massachusetts at Amherst), Chuang Gan (MIT-IBM Watson AI Lab)
Faster Vision Transformers with Adaptive Patches
Authors: Rohan Choudhury (None), JungEun Kim (General Robotics), Jinhyung Park (Carnegie Mellon University), Eunho Yang (Korea Advanced Institute of Science & Technology), Laszlo A. Jeni (Carnegie Mellon University), Kris Kitani (Carnegie Mellon University)
VINCIE: Unlocking In-context Image Editing from Video
Authors: Leigang Qu (National University of Singapore), Feng Cheng (ByteDance Seed), Ziyan Yang (ByteDance Inc.), Qi Zhao (ByteDance Inc.), Shanchuan Lin (ByteDance), Yichun Shi (None), Yicong Li (National University of Singapore), Wenjie Wang (University of Science and Technology of China), Tat-Seng Chua (National University of Singapore), Lu Jiang (Carnegie Mellon University)
lmgame-Bench: How Good are LLMs at Playing Games?
Authors: Lanxiang Hu (University of California, San Diego), Mingjia Huo (University of California, San Diego), Yuxuan Zhang (University of California, San Diego), Haoyang Yu (University of California San Diego), Eric P Xing (CMU), Ion Stoica (), Tajana Rosing (University of California, San Diego), Haojian Jin (None), Hao Zhang (University of California, San Diego)
SpineBench: A Clinically Salient, Level-Aware Benchmark Powered by the SpineMed-450k Corpus
Authors: Ming Zhao (Jilin University), Wenhui Dong (NanJing University), Yang Zhang (Chinese People’s Liberation Army General Hospital), wangyou (University of the Chinese Academy of Sciences), Zhonghao Zhang (Ningxia University), Zian Zhou (Zhejiang University), YUNZHI GUAN (Fudan University), Liukun Xu (Nanjing Medical University), Wei Peng (Stanford University), Zhaoyang Gong (Fudan University), Zhicheng Zhang (Chinese People’s Liberation Army General Hospital), Dachuan li (Fudan University), Xiaosheng Ma (Fudan University), Yuli Ma (Peking University), Jianing Ni (Carnegie Mellon University), Changjiang Jiang (Ant Group), Lixia Tian (Beijing Jiaotong University), Chen Qixin (Zhejiang University), Xia Kaishun (Zhejiang University of Technology), Pingping Liu (Jilin University), Tongshun Zhang (Jilin University), ZhiqiangLiu (Huazhong University of Science and Technology), Zhongan Bi (Zhejiang Lab), Chenyang Si (Nanyang Technological University), Tiansheng Sun (Chinese People’s Liberation Army General Hospital), Caifeng Shan (Nanjing University)
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Authors: Jianyi Wang (Nanyang Technological University), Shanchuan Lin (ByteDance), Zhijie Lin (Zhejiang University), Yuxi Ren (ByteDance Inc.), Meng Wei (ByteDance Inc.), Zongsheng Yue (Xi’an Jiaotong University), Shangchen Zhou (Nanyang Technological University), Hao Chen (ByteDance Inc.), Yang Zhao (Bytedance Inc.), Ceyuan Yang (ByteDance), Xuefeng Xiao (ByteDance), Chen Change Loy (Nanyang Technological University), Lu Jiang (Carnegie Mellon University)
Mixture of Contexts for Long Video Generation
Authors: Shengqu Cai (Stanford University), Ceyuan Yang (ByteDance), Lvmin Zhang (Stanford University), Yuwei Guo (The Chinese University of Hong Kong), Junfei Xiao (Johns Hopkins University), Ziyan Yang (ByteDance Inc.), Yinghao Xu (Stanford University), Zhenheng Yang (Tiktok), Alan Yuille (Johns Hopkins University), Leonidas Guibas (Stanford University), Maneesh Agrawala (Stanford University), Lu Jiang (Carnegie Mellon University), Gordon Wetzstein (Stanford University)
pySpatial: Generating 3D Visual Programs for Zero-Shot Spatial Reasoning
Authors: Zhanpeng Luo (University of Pittsburgh), Ce Zhang (Carnegie Mellon University), Silong Yong (Department of Automation, Tsinghua University, Tsinghua University), Cunxi Dai (Carnegie Mellon University), Qianwei Wang (University of Michigan – Ann Arbor), Haoxi Ran (Carnegie Mellon University), Guanya Shi (CMU, Carnegie Mellon University), Katia Sycara (Carnegie Mellon University), Yaqi Xie (Carnegie Mellon University)
Sharp Monocular View Synthesis in Less Than a Second
Authors: Lars Mescheder (Apple), Wei Dong (Apple), Shiwei Li (Apple), Xuyang BAI (Apple), Marcel Santos (Apple), Peiyun Hu (Carnegie Mellon University), Bruno Lecouat (Telecom ParisTech), Mingmin Zhen (Apple), Amaël Delaunoy (Apple), Tian Fang (Hong Kong University of Science and Technology), Yanghai Tsin (Apple), Stephan Richter (Apple), Vladlen Koltun (Apple)
S2GO: Streaming Sparse Gaussian Occupancy
Authors: Jinhyung Park (Carnegie Mellon University), Chensheng Peng (University of California, Berkeley), yihan hu (Applied Intuition), Wenzhao Zheng (UC Berkeley), Kris Kitani (Carnegie Mellon University), Wei Zhan (University of California Berkeley)
Captain Cinema: Towards Short Movie Generation
Authors: Junfei Xiao (Johns Hopkins University), Ceyuan Yang (ByteDance), Lvmin Zhang (Stanford University), Shengqu Cai (Stanford University), Yang Zhao (Bytedance Inc.), Yuwei Guo (The Chinese University of Hong Kong), Gordon Wetzstein (Stanford University), Maneesh Agrawala (Stanford University), Alan Yuille (Johns Hopkins University), Lu Jiang (Carnegie Mellon University)
Deep Learning
VisCoder2: Building Multi-Language Visualization Coding Agents
Authors: Yuansheng Ni (University of Waterloo), Songcheng Cai (University of Waterloo), Xiangchao Chen (University of Waterloo), Jiarong Liang (University of Waterloo), Zhiheng LYU (University of Hong Kong), Jiaqi Deng (Korea Advanced Institute of Science & Technology), Kai Zou (NetMind.AI), PING NIE (Peking University), Fei Yuan (Shanghai Artificial Intelligent Laboratory), Xiang Yue (Carnegie Mellon University), Wenhu Chen (University of Waterloo)
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Authors: Amrith Setlur (Carnegie Mellon University), Matthew Yang (Carnegie Mellon University), Charlie Snell (University of California, Berkeley), Jeremiah Greer (Oumi AI PBC), Ian Wu (Carnegie Mellon University), Virginia Smith (Carnegie Mellon University), Max Simchowitz (Massachusetts Institute of Technology), Aviral Kumar (University of California Berkeley)
Log-Linear Attention
Authors: Guo (), Songlin Yang (ShanghaiTech University), Tarushii Goel (Massachusetts Institute of Technology), Eric P Xing (CMU), Tri Dao (Princeton University), Yoon Kim (MIT)
Generalized Parallel Scaling with Interdependent Generations
Authors: Harry Dong (Carnegie Mellon University), David Brandfonbrener (NYU), Eryk Helenowski (Facebook), Yun He (Meta), Mrinal Kumar (Facebook), Han Fang (Meta GenAI), Yuejie Chi (Carnegie Mellon University), Karthik Abinav Sankararaman (Facebook)
General Machine Learning
On Code-Induced Reasoning in LLMs
Authors: Abdul Waheed (Carnegie Mellon University), Zhen Wu (Carnegie Mellon University), Carolyn Rose (School of Computer Science, Carnegie Mellon University), Daphne Ippolito (School of Engineering and Applied Science, University of Pennsylvania)
Multiple-Prediction-Powered Inference
Authors: Charlie Cowen-Breen (Massachusetts Institute of Technology), Alekh Agarwal (Google), Stephen Bates (Massachusetts Institute of Technology), William W. Cohen (Carnegie Mellon University), Jacob Eisenstein (Google), Amir Globerson (Google), Adam Fisch (Google DeepMind)
Command-V: Training-Free Representation Finetuning Transfer
Authors: Barry Wang (Carnegie Mellon University), Avi Schwarzschild (Carnegie Mellon University), Alexander Robey (CMU, Carnegie Mellon University), Ali Payani (Cisco Systems), Charles Fleming (Cisco), Mingjie Sun (School of Computer Science, Carnegie Mellon University), Daphne Ippolito (School of Engineering and Applied Science, University of Pennsylvania)
Prompt-MII: Meta-Learning Instruction Induction for LLMs
Authors: Emily Xiao (Carnegie Mellon University), Yixiao Zeng (XPeng Motors / Carnegie Mellon University), Ada Chen (CMU, Carnegie Mellon University), Chin-Jou Li (Language Technologies Institute, Carnegie Mellon University), Amanda Bertsch (Carnegie Mellon University), Graham Neubig (Carnegie Mellon University)
Optimization
Reinforcement Learning
HARDTESTGEN: A High-Quality RL Verifier Generation Pipeline for LLM Algorithimic Coding
Authors: Zhongmou He (Carnegie Mellon University), Yee Man Choi (University of Waterloo), Kexun Zhang (Carnegie Mellon University), Ivan Bercovich (UC Santa Barbara + ScOp VC), Jiabao Ji (University of California, Santa Barbara), Junting Zhou (Peking University), Dejia Xu (University of Texas at Austin), Aidan Zhang (Carnegie Mellon University), Yixiao Zeng (XPeng Motors / Carnegie Mellon University), Lei Li (School of Computer Science, Carnegie Mellon University)
Reevaluating Policy Gradient Methods for Imperfect-Information Games
Authors: Max Rudolph (University of Texas at Austin), Nathan Lichtlé (Electrical Engineering & Computer Science Department, University of California, Berkeley), Sobhan Mohammadpour (MIT), Alexandre M Bayen (None), Zico Kolter (Carnegie Mellon University), Amy Zhang (UT Austin), Gabriele Farina (Massachusetts Institute of Technology), Eugene Vinitsky (New York University), Samuel Sokota (Carnegie Mellon University)
GEM: A Gym for Generalist LLMs
Authors: Zichen Liu (Sea AI Lab), Anya Sims (University of Oxford), Keyu Duan (national university of singaore, National University of Singapore), Changyu Chen (Stanford University), Simon Yu (Northeastern University), Xiangxin Zhou (UCAS), Haotian Xu (Tsinghua University, Tsinghua University), Shaopan Xiong (Alibaba Group), Bo Liu (National University of Singapore), Chenmien Tan (University of Edinburgh), Weixun Wang (Tianjin University), Hao Zhu (Carnegie Mellon University), Weiyan Shi (Columbia University), Diyi Yang (Stanford University), Michael Qizhe Shieh (National University of Singapore), Yee Whye Teh (University of Oxford and Google DeepMind), Wee Sun Lee (National University of Singapore), Min Lin (Sea AI Lab)
Social Aspects
BEAT: Visual Backdoor Attacks on VLM-based Embodied Agents via Contrastive Trigger Learning
Authors: Qiusi Zhan (University of Illinois Urbana-Champaign), Hyeonjeong Ha (University of Illinois Urbana-Champaign), Rui Yang (Hong Kong University of Science and Technology), Sirui Xu (University of Illinois at Urbana-Champaign), Hanyang Chen (University of Illinois at Urbana-Champaign), Liang-Yan Gui (UIUC), Yu-Xiong Wang (UIUC), Huan Zhang (CMU), Heng Ji (University of Illinois at Urbana-Champaign), Daniel Kang (UIUC)
VLSU: Mapping the Limits of Joint Multimodal Understanding for AI Safety
Authors: Shruti Palaskar (Apple), Leon Gatys (Apple), Mona Abdelrahman (Apple), Mar Jacobo (Apple), Laurence Lindsey (Apple), Rutika Moharir (Apple), Gunnar Lund (Grammarly), Yang Xu (Apple), Navid Shiee (Apple), Jeffrey Bigham (Carnegie Mellon University), Charles Maalouf (Apple), Joseph Cheng (Apple)
Generative Value Conflicts Reveal LLM Priorities
Authors: Andy Liu (Carnegie Mellon University), Kshitish Ghate (University of Washington), Mona Diab (Carnegie Mellon University), Daniel Fried (Carnegie Mellon University), Atoosa Kasirzadeh (Alan Turing Institute), Max Kleiman-Weiner (Common Sense Machines)
PluriHarms: Benchmarking the Full Spectrum of Human Judgments on AI Harm
Authors: Jing-Jing Li (University of California, Berkeley), Joel Mire (Carnegie Mellon University), Eve Fleisig (UC Berkeley), Valentina Pyatkin (Ai2, ETH AI Center), Anne Collins (University of California, Berkeley), Maarten Sap (Carnegie Mellon University), Sydney Levine (NYU / Google Deepmind)
Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability
Authors: Taylor Sorensen (humans&), Benjamin Newman (University of Washington), Jared Moore (Computer Science Department, Stanford University), Chan Young Park (University of Texas at Austin), Jillian Fisher (University of Washington), Niloofar Mireshghallah (Carnegie Mellon University), Liwei Jiang (None), Yejin Choi (Stanford University / NVIDIA)
Theory
Convergence of Regret Matching in Potential Games and Constrained Optimization
Authors: Ioannis Anagnostides (Carnegie Mellon University), Emanuel Tewolde (Carnegie Mellon University), Brian Zhang (MIT), Ioannis Panageas (Donald Bren School of Information and Computer Sciences, University of California, Irvine), Vincent Conitzer (Carnegie Mellon University), Tuomas Sandholm (Carnegie Mellon University)
Sample Complexity and Representation Ability of Test-time Scaling Paradigms
Authors: Baihe Huang (University of California, Berkeley), Shanda Li (Carnegie Mellon University), Tianhao Wu (University of California, Berkeley), Yiming Yang (Carnegie Mellon University), Ameet Talwalkar (University of California-Los Angeles), Kannan Ramchandran (), Michael Jordan (University of California, Berkeley), Jiantao Jiao (University of California Berkeley)
Polynomial Convergence of Riemannian Diffusion Models
Authors: Xingyu Xu (CMU, Carnegie Mellon University), Ziyi Zhang (CMU, Carnegie Mellon University), Yorie Nakahira (Researcher at NII LLM Center Assistant Professor at CMU), Guannan Qu (Carnegie Mellon University), Yuejie Chi (Carnegie Mellon University)
Learning-Augmented Moment Estimation on Time-Decay Models
Authors: Soham Nagawanshi (Texas A&M University – College Station), Shalini Panthangi (CMU, Carnegie Mellon University), Chen Wang (Rice University and Texas A&M University), David Woodruff (Carnegie Mellon University), Samson Zhou (Texas A&M University)
Uncategorized
RLP: Reinforcement as a Pretraining Objective
Authors: Ali Hatamizadeh (Nvidia), Syeda Nahida Akter (Carnegie Mellon University), Shrimai Prabhumoye (NVIDIA), Jan Kautz (NVIDIA), Mostofa Patwary (NVIDIA), Mohammad Shoeybi (NVIDIA), Bryan Catanzaro (NVIDIA), Yejin Choi (Stanford University / NVIDIA)
Think Then Embed: Generative Context Improves Multimodal Embedding
Authors: Xuanming Cui (University of Central Florida), Jianpeng Cheng (Meta), Hong-You Chen (Ohio State University), Satya Narayan Shukla (Meta), Abhijeet Awasthi (Indian Institute of Technology Bombay), Xichen Pan (New York University), Chaitanya Ahuja (Carnegie Mellon University), Shlok Mishra (Facebook), Taipeng Tian (Meta), Qi Guo (Facebook), Ser-Nam Lim (University of Central Florida), Aashu Singh (Facebook), Xiangjun Fan (Meta)
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Authors: Yanghao Li (Apple), Rui Qian (Apple), Bowen Pan (Massachusetts Institute of Technology), Haotian Zhang (NVIDIA), Haoshuo Huang (Apple), Bowen Zhang (Apple), Jialing Tong (Apple), Haoxuan You (Apple AI/ML), Xianzhi Du (Apple), Zhe Gan (Apple), Hyunjik Kim (DeepMind), Chao Jia (Google), Zhenbang Wang (Apple), Yinfei Yang (Apple), Mingfei Gao (Apple), Zi-Yi Dou (Carnegie Mellon University), Wenze Hu (UCLA, University of California, Los Angeles), Chang Gao (Waymo), Dongxu Li (SalesForce.com), Philipp Dufter (Apple), Zirui Wang (Apple AI/ML), Guoli Yin (Apple), Zhengdong Zhang (Google), Chen Chen (Apple), Yang Zhao (University of California, Berkeley), Ruoming Pang (None), Zhifeng Chen (Apple)
TrustGen: A Platform of Dynamic Benchmarking on the Trustworthiness of Generative Foundation Models
Authors: Yue Huang (University of Notre Dame), Chujie Gao (Mohamed bin Zayed University of Artificial Intelligence), Siyuan Wu (None), Haoran Wang (Emory University), Xiangqi Wang (University of Notre Dame), Jiayi Ye (Sichuan University), Yujun Zhou (University of Notre Dame), Yanbo Wang (Mohamed bin Zayed University of Artificial Intelligence), Jiawen Shi (Huazhong University of Science and Technology), Qihui Zhang (Sichuan University), Han Bao (University of Notre Dame), Zhaoyi Liu (University of Illinois at Urbana-Champaign), Yuan Li (University of Cambridge), Tianrui Guan (Department of Computer Science, University of Maryland, College Park), Peiran Wang (University of California, Los Angeles), Haomin Zhuang (University of Notre Dame), Dongping Chen (University of Washington), Kehan Guo (University of Notre Dame), Andy Zou (CMU, Carnegie Mellon University), Bryan Hooi (National University of Singapore), Caiming Xiong (Salesforce Research), Elias Stengel-Eskin (Department of Computer Science, UT Austin), Hongyang Zhang (University of Waterloo), Hongzhi Yin (University of Queensland), Huan Zhang (CMU), Huaxiu Yao (UNC-Chapel Hill), Jieyu Zhang (Department of Computer Science, University of Washington), Jaehong Yoon (NTU Singapore), Kai Shu (Emory University), Ranjay Krishna (Department of Computer Science), Swabha Swayamdipta (University of Southern California), Weijia Shi (University of Washington, Seattle), Xiang Li (Massachusetts General Hospital), Yuexing Hao (Massachusetts Institute of Technology), Zhihao Jia (School of Computer Science, Carnegie Mellon University), Zhize Li (KAUST), Xiuying Chen (Mohamed bin Zayed University of Artificial Intelligence), Zhengzhong Tu (Texas A&M University – College Station), Xiyang Hu (Arizona State University), Tianyi Zhou (MBZUAI), Jieyu Zhao (University of Southern California), Lichao Sun (Lehigh University), Furong Huang (University of Maryland), Or Cohen-Sasson (University of Miami), Prasanna Sattigeri (IBM Research), Anka Reuel (Stanford University), Max Lamparth (Stanford University), Yue Zhao (University of Southern California), Nouha Dziri (Allen Institute for AI), Yu Su (Ohio State University), Huan Sun (Ohio State University), Heng Ji (University of Illinois at Urbana-Champaign), Chaowei Xiao (Johns Hopkins University/NVIDIA), Mohit Bansal (UNC Chapel Hill), Nitesh Chawla (University of Notre Dame), Jian Pei (Simon Fraser University), Jianfeng Gao (Microsoft Research), Michael Backes (CISPA Helmholtz Center for Information Security), Philip Yu (University of Illinois, Chicago), Neil Gong (), Pin-Yu Chen (IBM Research AI), Bo Li (University of Illinois, Urbana Champaign), Dawn Song (Berkeley), Xiangliang Zhang (University of Notre Dame)
RefineBench: Evaluating Refinement Capability of Language Models via Checklists
Authors: Young-Jun Lee (KAIST), Seungone Kim (Carnegie Mellon University), Byung-Kwan Lee (NVIDIA), Minkyeong Moon (Yonsei University), Yechan Hwang (), Jong Myoung Kim (Korea Advanced Institute of Science & Technology), Graham Neubig (Carnegie Mellon University), Sean Welleck (Carnegie Mellon University), Ho-Jin Choi (Korea Advanced Institute of Science & Technology)
Scaling Group Inference for Diverse and High-Quality Generation
Authors: Gaurav Parmar (Carnegie Mellon University), Or Patashnik (Tel Aviv University), Daniil Ostashev (Snap Inc.), Kuan-Chieh Wang (Snap Inc.), Kfir Aberman (Google), Srinivasa Narasimhan (Carnegie Mellon University), Jun-Yan Zhu (Carnegie Mellon University)
Much Ado About Noising: Dispelling the Myths of Generative Robotic Control
Authors: Chaoyi Pan (Carnegie Mellon University), Giridharan Anantharaman (Facebook), Nai-Chieh Huang (Carnegie Mellon University), Claire Jin (School of Computer Science, Carnegie Mellon University), Daniel Pfrommer (None), Chenyang Yuan (Toyota Research Institute), Frank Permenter (Toyota Research Institute), Guannan Qu (Carnegie Mellon University), Nicholas Boffi (CMU, Carnegie Mellon University), Guanya Shi (CMU, Carnegie Mellon University), Max Simchowitz (Massachusetts Institute of Technology)
Taming Imperfect Process Verifiers: A Sampling Perspective on Backtracking
Authors: Dhruv Rohatgi (Massachusetts Institute of Technology), Abhishek Shetty (University of California Berkeley), Donya Saless (University of California, Berkeley), Yuchen Li (Carnegie Mellon University), Ankur Moitra (Massachusetts Institute of Technology), Andrej Risteski (Carnegie Mellon University), Dylan Foster (Microsoft Research NYC)
Ada-Diffuser: Latent-Aware Adaptive Diffusion for Decision-Making
Authors: Fan Feng (University of California, San Diego), Selena Ge (University of California, San Diego), Minghao Fu (University of California, San Diego), Zijian Li (Mohamed bin Zayed University of Artificial Intelligence), Yujia Zheng (Carnegie Mellon University), Zeyu Tang (Stanford University), Yingyao Hu (Johns Hopkins University), Biwei Huang (University of California, San Diego), Kun Zhang (Carnegie Mellon University & MBZUAI)
ZeroGR: A Generalizable and Scalable Framework for Zero-Shot Generative Retrieval
Authors: Weiwei Sun (Carnegie Mellon University), Keyi Kong (Shandong University), xinyu ma (Institute of Computing Technology,Chinese Academy of Science), Shuaiqiang Wang (Baidu Inc.), Dawei Yin (Baidu), Maarten de Rijke (University of Amsterdam), Zhaochun Ren (Leiden University), Yiming Yang (Carnegie Mellon University)
TokUR: Token-Level Uncertainty Estimation for Large Language Model Reasoning
Authors: Tunyu Zhang (Rutgers University), Haizhou Shi (ML Lab@Rutgers), Yibin Wang (None), Hengyi Wang (Rutgers University), Xiaoxiao He (Facebook), Zhuowei Li (Amazon), Haoxian Chen (Columbia University), Ligong Han (Rutgers University), Kai Xu (Amazon), Huan Zhang (CMU), Dimitris Metaxas (Rutgers University), Hao Wang (Rutgers University)
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Authors: Mike Merrill (None), Alexander Shaw (Brigham Young University), Nicholas Carlini (Anthropic), Boxuan Li (Microsoft), Harsh Raj (Northeastern University), Ivan Bercovich (UC Santa Barbara + ScOp VC), Lin Shi (Cornell University), Jeong Shin (Snorkel AI), Thomas Walshe (Reflection AI), E. Kelly Buchanan (Columbia University), Junhong Shen (Carnegie Mellon University), Guanghao Ye (Massachusetts Institute of Technology), Haowei Lin (Peking University), Jason Poulos (Independent Researcher), Maoyu Wang (), Marianna Nezhurina (Juelich Supercomputing Center, LAION, Tuebingen University), Di Lu (Tencent), Orfeas Menis Mastromichalakis (National Technical University of Athens), Zhiwei Xu (University of Michigan), Zizhao Chen (Department of Computer Science, Cornell University), Yue Liu (NUS), Robert Zhang (University of Texas at Austin), Leon Liangyu Chen (Stanford University), Anurag Kashyap (Amazon), Jan-Lucas Uslu (Stanford University), Jeffrey Li (Carnegie Mellon University), Jianbo Wu (University of California, Merced), Minghao Yan (Department of Computer Science, University of Wisconsin – Madison), Song Bian (University of Wisconsin-Madison), Vedang Sharma (Fremont Unified School District), Ke Sun (Amazon), Steven Dillmann (Stanford University), Akshay Anand (University of California, Berkeley), Andrew Lanpouthakoun (Stanford University), Bardia Koopah (University of California, Berkeley), Changran Hu (Sambanova Systems, Inc), Etash Guha (Stanford University, Anthropic), Gabriel Dreiman (Insitro), Jiacheng Zhu (Massachusetts Institute of Technology), Karl Krauth (Stanford), Li Zhong (Anthropic), Niklas Muennighoff (Stanford University), Robert Amanfu (Independent), Shangyin Tan (University of California, Berkeley), Shreyas Pimpalgaonkar (New York University), Tushar Aggarwal (Microsoft Research / Stanford), Xiangning Lin (CMU), Xin Lan (Michigan State University), Xuandong Zhao (UC Berkeley), Yiqing Liang (Brown University), Yuanli Wang (Boston University), Zilong (Ryan) Wang (UC San Diego), Changzhi Zhou (Tencent), David Heineman (Allen Institute for Artificial Intelligence), Hange Liu (Microsoft), Harsh Trivedi (Allen Institute for Artificial Intelligence), John Yang (Princeton University), Junhong Lin (Massachusetts Institute of Technology), Manish Shetty (University of California, Berkeley), Michael Yang (University of California, Santa Barbara), Nabil Omi (Microsoft Research), Negin Raoof (University of California, Berkeley), Shanda Li (Carnegie Mellon University), Terry Yue Zhuo (Data61, CSIRO), Wuwei Lin (OpenAI), Yiwei Dai (Cornell University), Yuxin Wang (Dartmouth College), Wenhao Chai (Princeton University), Shang Zhou (University of California, San Diego), Dariush Wahdany (CISPA Helmholtz Center), Ziyu She (None), Jiaming Hu (Boston University), Zhikang Dong (State University of New York at Stony Brook), Yuxuan Zhu (University of Illinois Urbana-Champaign), Sasha Cui (Yale University), Ahson Saiyed (University of Virginia, Charlottesville), Arinbjörn Kolbeinsson (UVA & K01), Christopher Rytting (Brigham Young University), Ryan Marten (Harbor), Yixin Wang (University of Michigan – Ann Arbor), Jenia Jitsev (LAION; Juelich Supercomputing Center, Research Center Juelich), Alex Dimakis (Electrical Engineering & Computer Science Department, University of California, Berkeley), Andy Konwinski (University of California, Berkeley), Ludwig Schmidt (University of Washington / Stanford / Anthropic)
A Dense Subset Index for Collective Query Coverage
Authors: Kartik Nair (Carnegie Mellon University), Pritish Chakraborty (Indian Institute of Technology Bombay, Indian Institute of Technology, Bombay), Atharva Tambat (Indian Institute of Technology Bombay, Indian Institute of Technology, Bombay), Indradyumna Roy (IIT Bombay, Aalto University), Soumen Chakrabarti (IIT Bombay), Anirban Dasgupta (IIT Gandhinagar), Abir De (Indian Institute of Technology Bombay,)
MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers
Authors: Zhenting Wang (Rutgers University), Qi Chang (Accenture), Hemani Patel (University of California, Berkeley), Shashank Biju (University of California, Berkeley), Cheng-En Wu (Accenture), Quan Liu (Accenture), Aolin Ding (Accenture), Alireza Rezazadeh (Accenture), Ankit Parag Shah (Carnegie Mellon University), Yujia Bao (Accenture), Eugene Siow (Accenture)
STEM: SCALING TRANSFORMERS WITH EMBEDDING MODULES
Authors: Ranajoy Sadhukhan (Carnegie Mellon University), Sheng Cao (Meta), Harry Dong (Carnegie Mellon University), Changsheng Zhao (Meta Inc.), Attiano Purpura-Pontoniere (Meta – UCLA), Yuandong Tian (Meta AI Research), Zechun Liu (Meta), Beidi Chen (CMU, Carnegie Mellon University)
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Authors: Ruibin Yuan (Hong Kong University of Science and Technology), Hanfeng Lin (Hong Kong University of Science and Technology), Shuyue Guo (Beijing University of Posts and Telecommunications), Ge Zhang (University of Waterloo), Jiahao Pan (Hong Kong University of Science and Technology), Yongyi Zang (Smule, Inc.), Haohe Liu (Ohio State University), Yiming Liang (University of the Chinese Academy of Sciences), Wenye Ma (Mohamed bin Zayed University of Artificial Intelligence), Xingjian Du (University of Rochester), Xeron Du (01.AI), Zhen Ye (The Hong Kong University of Science and Technology), Tianyu Zheng (Beijing University of Posts and Telecommunications), Zhengxuan Jiang (Zhejiang University), Yinghao MA (Queen Mary University of London), Minghao Liu (2077AI), Zeyue Tian (Hong Kong University of Science and Technology), Ziya Zhou (The Hong Kong University of Science and Technology), Liumeng Xue (Hong Kong University of Science and Technology), Xingwei Qu (University of Manchester), Yizhi Li (University of Manchester), Shangda Wu (Tencent), Tianhao Shen (Tianjin University), Ziyang Ma (Shanghai Jiao Tong University), Jun Zhan (Fudan University), Chunhui Wang (JD.com), Yatian Wang (The Hong Kong University of Science and Technology), Xiaowei Chi (Hong Kong University of Science and Technology), Xinyue Zhang (National University of Singapore), Zhenzhu Yang (China University of Geoscience Beijing), XiangzhouWang (Wuhan University of Engineering Science), Shansong Liu (Institute of Artificial Intelligence (TeleAI), China Telecom), Lingrui Mei (University of the Chinese Academy of Sciences), Peng Li (Hong Kong University of Science and Technology), JUNJIE WANG (None), Jianwei Yu (Microsoft), Guojian Pang (ByteDance Inc.), Xu Li (Kuaishou- 快手科技), Zihao Wang (CMU, Carnegie Mellon University;ZJU,Zhejiang University), Xiaohuan Zhou (ByteDance Inc.), Lijun Yu (Google DeepMind), Emmanouil Benetos (Queen Mary University of London), Yong Chen (Geely Automobile Research Institute (Ningbo) Co., Ltd), Chenghua Lin (University of Manchester ), Xie Chen (Shanghai Jiaotong University), Gus Xia (MBZUAI), Zhaoxiang Zhang (Institute of automation, Chinese academy of science, Chinese Academy of Sciences), Chao Zhang (Department of Electronic Engineering, Tsinghua University), Wenhu Chen (University of Waterloo), Xinyu Zhou (Megvii Inc.), Xipeng Qiu (Fudan University), Roger Dannenberg (Carnegie Mellon University), JIAHENG LIU (Nanjing University), Jian Yang (Beihang University), Wenhao Huang (01.AI), Wei Xue (Hong Kong University of Science and Technology), Xu Tan (Microsoft Research), Yike Guo (Imperial College London)
PAT3D: Physics-Augmented Text-to-3D Scene Generation
Authors: Guying Lin (Carnegie Mellon University), Kemeng Huang (University of Hong Kong), Michael Liu (CMU, Carnegie Mellon University), Ruihan Gao (Carnegie Mellon University), Hanke Chen (Carnegie Mellon University), Lyuhao Chen (Carnegie Mellon University), Beijia Lu (Carnegie Mellon University), Taku Komura (the University of Hong Kong, University of Hong Kong), Yuan Liu (The University of Hong Kong), Jun-Yan Zhu (Carnegie Mellon University), Minchen Li (School of Engineering and Applied Science, University of Pennsylvania)
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Authors: Yong Lin (Princeton University), Shange Tang (Princeton University), Bohan Lyu (Tsinghua University), Ziran Yang (Princeton University), Jui-Hui Chung (Princeton University), Haoyu Zhao (Princeton University), Lai Jiang (University of Illinois at Urbana-Champaign), Yihan Geng (Peking University), Jiawei Ge (Princeton University), Jingruo Sun (Stanford University), Jiayun Wu (Carnegie Mellon University), Jiri Gesi (Amazon Science), Ximing Lu (University of Washington), David Acuna (NVIDIA / Univ of Toronto), Kaiyu Yang (Meta), Hongzhou Lin (Amazon), Yejin Choi (Stanford University / NVIDIA), Danqi Chen (Princeton University), Sanjeev Arora (Princeton University), Chi Jin (Princeton University)
Diverse Dictionary Learning
Authors: Yujia Zheng (Carnegie Mellon University), Zijian Li (Mohamed bin Zayed University of Artificial Intelligence), Shunxing Fan (Mohamed bin Zayed University of Artificial Intelligence), Andrew Gordon Wilson (New York University), Kun Zhang (Carnegie Mellon University & MBZUAI)
Accelerating Eigenvalue Dataset Generation via Chebyshev Subspace Filter
Authors: Hong Wang (University of Science and Technology of China), Jie Wang (University of Science and Technology of China), Jian Luo (Stony Brook University), huanshuo dong (University of Science and Technology of China), Yeqiu Chen (University of Science and Technology of China), Runmin Jiang (Carnegie Mellon University), Zhen Huang (University of Science and Technology of China)
Beyond Hearing: Learning Task-Agnostic ExG Representations from Earphones via Physiology-Informed Tokenization
Authors: Hyungjun Yoon (Korea Advanced Institute of Science & Technology), Seungjoo Lee (Carnegie Mellon University), Yu Wu (Dartmouth College), XiaoMeng Chen (Shanghai Jiaotong University), Taiting Lu (Pennsylvania State University), Freddy Liu (University of Pennsylvania, University of Pennsylvania), Taeckyung Lee (KAIST), Hyeongheon Cha (Korea Advanced Institute of Science & Technology), Haochen Zhao (), Gaoteng Zhao (Northwest University), Dongyao Chen (Shanghai Jiaotong University), Cecilia Mascolo (University of Cambridge), Sung-Ju Lee (UCLA Computer Science Department, University of California, Los Angeles), Lili Qiu (Microsoft)
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
Authors: Seongyun Lee (KAIST AI), Seungone Kim (Carnegie Mellon University), Minju Seo (Korea Advanced Institute of Science & Technology), Yongrae Jo (KAIST), Dongyoung Go (Cornell University), Hyeonbin Hwang (Korea Advanced Institute of Science & Technology), Jinho Park (Korea Advanced Institute of Science & Technology), Xiang Yue (Carnegie Mellon University), Sean Welleck (Carnegie Mellon University), Graham Neubig (Carnegie Mellon University), Moontae Lee (University of Illinois, Chicago), Minjoon Seo (KAIST)
PersonaX: Multimodal Datasets with LLM-Inferred Behavior Traits
Authors: Loka Li (MBZUAI), Wong Kang (Mohamed bin Zayed University of Artificial Intelligence), Minghao Fu (University of California, San Diego), Guangyi Chen (MBZUAI&CMU), Zhenhao Chen (MBZUAI), Gongxu Luo (Mohamed bin Zayed University of Artificial Intelligence), Yuewen Sun (Mohamed bin Zayed University of Artificial Intelligence), Salman Khan (Mohamed bin Zayed University of Artificial Intelligence), Peter Spirtes (Carnegie Mellon University), Kun Zhang (Carnegie Mellon University & MBZUAI)